
Gemma 3n 是生成式 AI 模型,經過最佳化處理,可用於日常使用的裝置,例如手機、筆電和平板電腦。這個模型包含參數效能處理的創新功能,包括每層嵌入 (PLE) 參數快取功能,以及 MatFormer 模型架構,可靈活減少運算和記憶體需求。這些模型可處理音訊輸入內容、文字和視覺資料。
Gemma 3n 包含下列重點功能:
- 音訊輸入:處理音訊資料,以便進行語音辨識、翻譯和音訊資料分析。瞭解詳情
- 視覺和文字輸入:多模態功能可處理視覺、聲音和文字,協助您理解及分析周遭環境。瞭解詳情
- 視覺編碼器:高效能 MobileNet-V5 編碼器可大幅提升視覺資料處理速度和準確度。瞭解詳情
- PLE 快取:這些模型中包含的每層嵌入 (PLE) 參數可快取至本機儲存空間,以減少模型記憶體執行成本。瞭解詳情
- MatFormer 架構:Matryoshka Transformer 架構可針對每個要求,有選擇地啟用模型參數,以降低運算成本和回應時間。瞭解詳情
- 條件式參數載入:略過模型中視覺和音訊參數的載入作業,以減少已載入參數的總數並節省記憶體資源。瞭解詳情
- 支援多種語言:支援多種語言,訓練超過 140 種語言。
- 32K 符記脈絡:用於分析資料和處理工作任務的大量輸入脈絡。
試用 Gemma 3n 在 Kaggle 取得模型 在 Hugging Face 取得模型
與其他 Gemma 模型一樣,Gemma 3n 提供開放權重,並授權進行負責任的商業用途,讓您在自己的專案和應用程式中進行調整及部署。
模型參數和有效參數
Gemma 3n 模型會列出參數計數,例如 E2B 和 E4B,這些計數低於模型中包含的參數總數。E 前置字串表示這些模型可使用較少的有效參數運作。您可以使用 Gemma 3n 模型內建的彈性參數技術,實現這項縮減參數作業,讓模型能在資源較少的裝置上順利運作。
Gemma 3n 模型中的參數分為 4 個主要群組:文字、影像、音訊和每層嵌入 (PLE) 參數。在執行 E2B 模型的標準執行作業時,會載入超過 50 億個參數。不過,透過參數略過和 PLE 快取技術,這個模型可在有效記憶體負載量略低於 20 億 (1.91B) 個參數的情況下運作,如圖 1 所示。
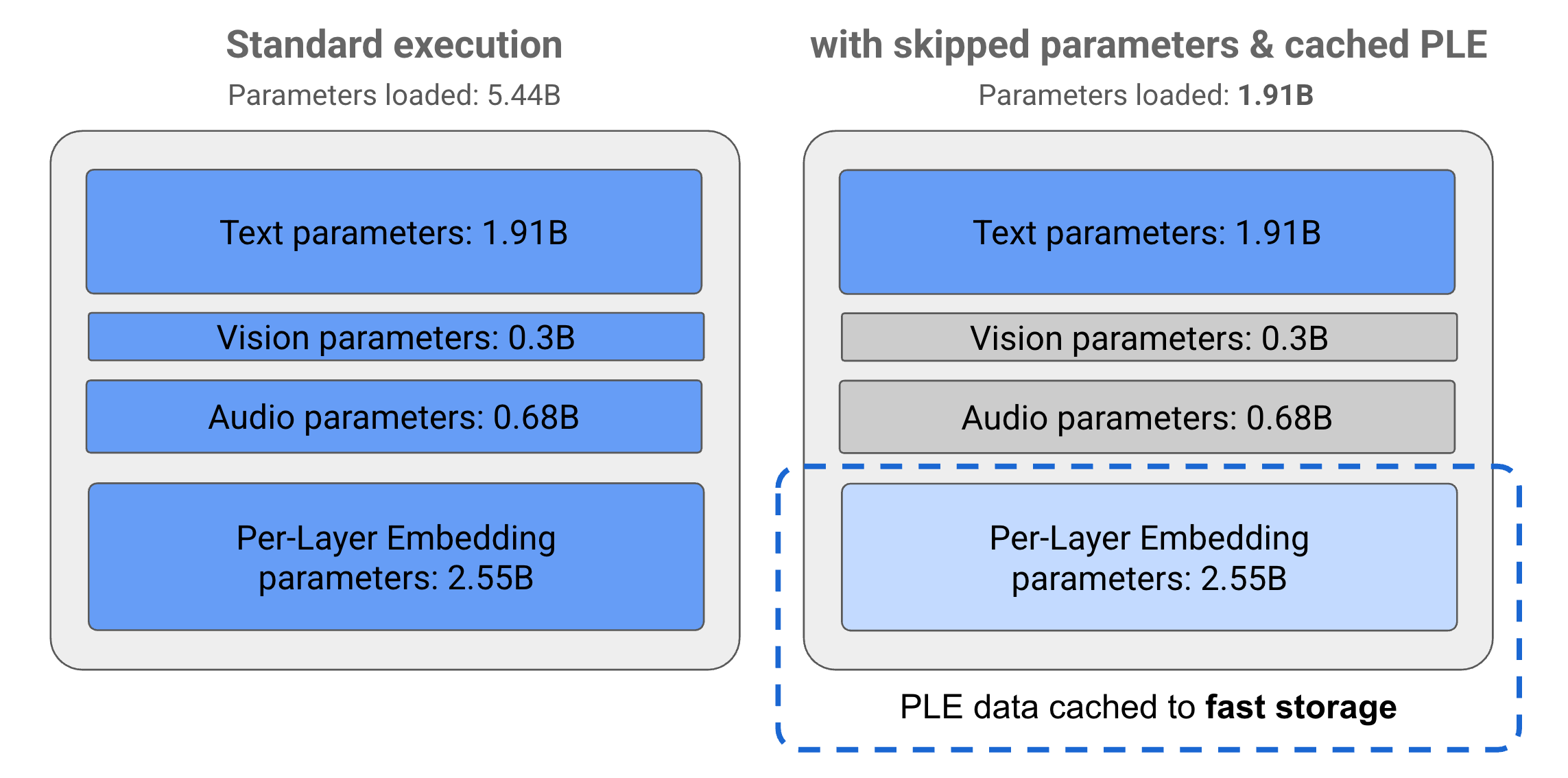
圖 1. 在標準執行模式下執行的 Gemma 3n E2B 模型參數,與使用 PLE 快取和參數略過技術的有效降低參數負載相比。
透過這些參數卸載和選擇性啟用技術,您可以使用非常精簡的參數組合執行模型,或是啟用其他參數來處理視覺和音訊等其他資料類型。這些功能可讓您根據裝置功能或工作需求,提升或降低模型功能。以下各節將進一步說明 Gemma 3n 模型中可用的參數效率技術。
PLE 快取
Gemma 3n 模型包含每層嵌入 (PLE) 參數,這些參數會在模型執行期間使用,用於建立可提升各模型層效能的資料。PLE 資料可在模型的作業記憶體之外個別產生,並快取至快速儲存空間,然後在各層執行時加入模型推論程序。這種做法可讓 PLE 參數不占用模型記憶體空間,進而減少資源用量,同時改善模型回應品質。
MatFormer 架構
Gemma 3n 模型採用 Matryoshka Transformer 或 MatFormer 模型架構,在單一大型模型中包含巢狀的較小模型。在回應要求時,您可以使用巢狀子模型進行推論,而無需啟用包函模型的參數。這種只在 MatFormer 模型中執行較小核心模型的能力,可降低模型的運算成本、回應時間和能源足跡。以 Gemma 3n 為例,E4B 模型包含 E2B 模型的參數。這個架構還可讓您選取參數,並組合 2B 到 4B 之間的中型模型。如要進一步瞭解這種方法,請參閱 MatFormer 研究論文。請嘗試使用 MatFormer 技術,並參閱 MatFormer Lab 指南,縮減 Gemma 3n 模型的大小。
條件式參數載入
與 PLE 參數類似,您可以在 Gemma 3n 模型中略過將部分參數 (例如音訊或視覺參數) 載入記憶體,以減少記憶體負載。如果裝置有必要的資源,這些參數可以在執行階段動態載入。整體而言,略過參數可進一步減少 Gemma 3n 模型所需的作業記憶體,讓開發人員可在更多裝置上執行,並提高資源效率,以便執行較不耗資源的工作。
準備好開始建構了嗎?
開始使用 Gemma 模型!