
Gemma 3n เป็นโมเดล Generative AI ที่เพิ่มประสิทธิภาพให้เหมาะกับการใช้งานในอุปกรณ์ที่ใช้ในชีวิตประจำวัน เช่น โทรศัพท์ แล็ปท็อป และแท็บเล็ต โมเดลนี้รวมนวัตกรรมด้านการประมวลผลที่มีประสิทธิภาพด้านพารามิเตอร์ ซึ่งรวมถึงการแคชพารามิเตอร์การฝังต่อเลเยอร์ (PLE) และสถาปัตยกรรมโมเดล MatFormer ที่มีความยืดหยุ่นในการลดข้อกำหนดด้านการคำนวณและหน่วยความจำ โมเดลเหล่านี้มีการจัดการอินพุตเสียง รวมถึงข้อมูลข้อความและภาพ
Gemma 3n มีฟีเจอร์หลักๆ ต่อไปนี้
- อินพุตเสียง: ประมวลผลข้อมูลเสียงสำหรับการจดจำคำพูด การแปล และการวิเคราะห์ข้อมูลเสียง ดูข้อมูลเพิ่มเติม
- อินพุตภาพและข้อความ: ความสามารถแบบหลายรูปแบบช่วยให้คุณจัดการกับภาพ เสียง และข้อความเพื่อช่วยให้คุณเข้าใจและวิเคราะห์โลกรอบตัว ดูข้อมูลเพิ่มเติม
- โปรแกรมเข้ารหัสภาพ: โปรแกรมเข้ารหัส MobileNet-V5 ประสิทธิภาพสูงช่วยเพิ่มความเร็วและความแม่นยำในการประมวลผลข้อมูลภาพได้อย่างมาก ดูข้อมูลเพิ่มเติม
- การแคช PLE: พารามิเตอร์การฝังต่อเลเยอร์ (PLE) ที่มีอยู่ในโมเดลเหล่านี้สามารถแคชไว้ในพื้นที่เก็บข้อมูลในเครื่องที่รวดเร็วเพื่อลดต้นทุนการเรียกใช้หน่วยความจําของโมเดล ดูข้อมูลเพิ่มเติม
- สถาปัตยกรรม MatFormer: สถาปัตยกรรม Matryoshka Transformer ช่วยให้สามารถเปิดใช้งานพารามิเตอร์ของโมเดลแบบเลือกตามคําขอเพื่อลดต้นทุนการประมวลผลและเวลาในการตอบสนอง ดูข้อมูลเพิ่มเติม
- การโหลดพารามิเตอร์แบบมีเงื่อนไข: ข้ามการโหลดพารามิเตอร์ภาพและเสียงในโมเดลเพื่อลดจํานวนพารามิเตอร์ทั้งหมดที่โหลดและประหยัดทรัพยากรหน่วยความจํา ดูข้อมูลเพิ่มเติม
- การรองรับภาษาที่หลากหลาย: ความสามารถในการใช้ภาษาที่หลากหลายซึ่งได้รับการฝึกอบรมในภาษาต่างๆ กว่า 140 ภาษา
- บริบทโทเค็น 32,000 รายการ: บริบทอินพุตจำนวนมากสําหรับการวิเคราะห์ข้อมูลและจัดการงานการประมวลผล
ลองใช้ Gemma 3n ดาวน์โหลดใน Kaggle ดาวน์โหลดใน Hugging Face
Gemma 3n มีน้ำหนักแบบเปิดและได้รับอนุญาตให้ใช้งานเชิงพาณิชย์อย่างมีความรับผิดชอบเช่นเดียวกับ Gemma รุ่นอื่นๆ ซึ่งช่วยให้คุณปรับแต่งและนำไปใช้ในโปรเจ็กต์และแอปพลิเคชันของคุณเองได้
พารามิเตอร์รูปแบบและพารามิเตอร์ที่มีประสิทธิภาพ
โมเดล Gemma 3n จะแสดงพร้อมกับจํานวนพารามิเตอร์ เช่น E2B และ E4B ซึ่งต่ำกว่าจํานวนพารามิเตอร์ทั้งหมดที่มีอยู่ในโมเดล ส่วนคำนำหน้า E บ่งบอกว่าโมเดลเหล่านี้สามารถทํางานได้โดยใช้ชุดพารามิเตอร์ที่มีประสิทธิภาพลดลง การดำเนินการพารามิเตอร์ที่ลดลงนี้ทำได้โดยใช้เทคโนโลยีพารามิเตอร์ที่ยืดหยุ่นซึ่งติดตั้งไว้ในรุ่น Gemma 3n เพื่อช่วยให้การทํางานมีประสิทธิภาพในอุปกรณ์ที่มีทรัพยากรน้อย
พารามิเตอร์ในโมเดล Gemma 3n แบ่งออกเป็น 4 กลุ่มหลัก ได้แก่ พารามิเตอร์ข้อความ รูปภาพ เสียง และการฝังต่อเลเยอร์ (PLE) เมื่อใช้การดําเนินการแบบมาตรฐานของรูปแบบ E2B ระบบจะโหลดพารามิเตอร์มากกว่า 5 พันล้านรายการเมื่อดําเนินการรูปแบบ อย่างไรก็ตาม เมื่อใช้เทคนิคการข้ามพารามิเตอร์และการแคช PLE รูปแบบนี้จะทํางานได้โดยใช้หน่วยความจําที่มีประสิทธิภาพเพียง 2 พันล้าน (1.91 พันล้าน) พารามิเตอร์ดังที่แสดงในรูปที่ 1
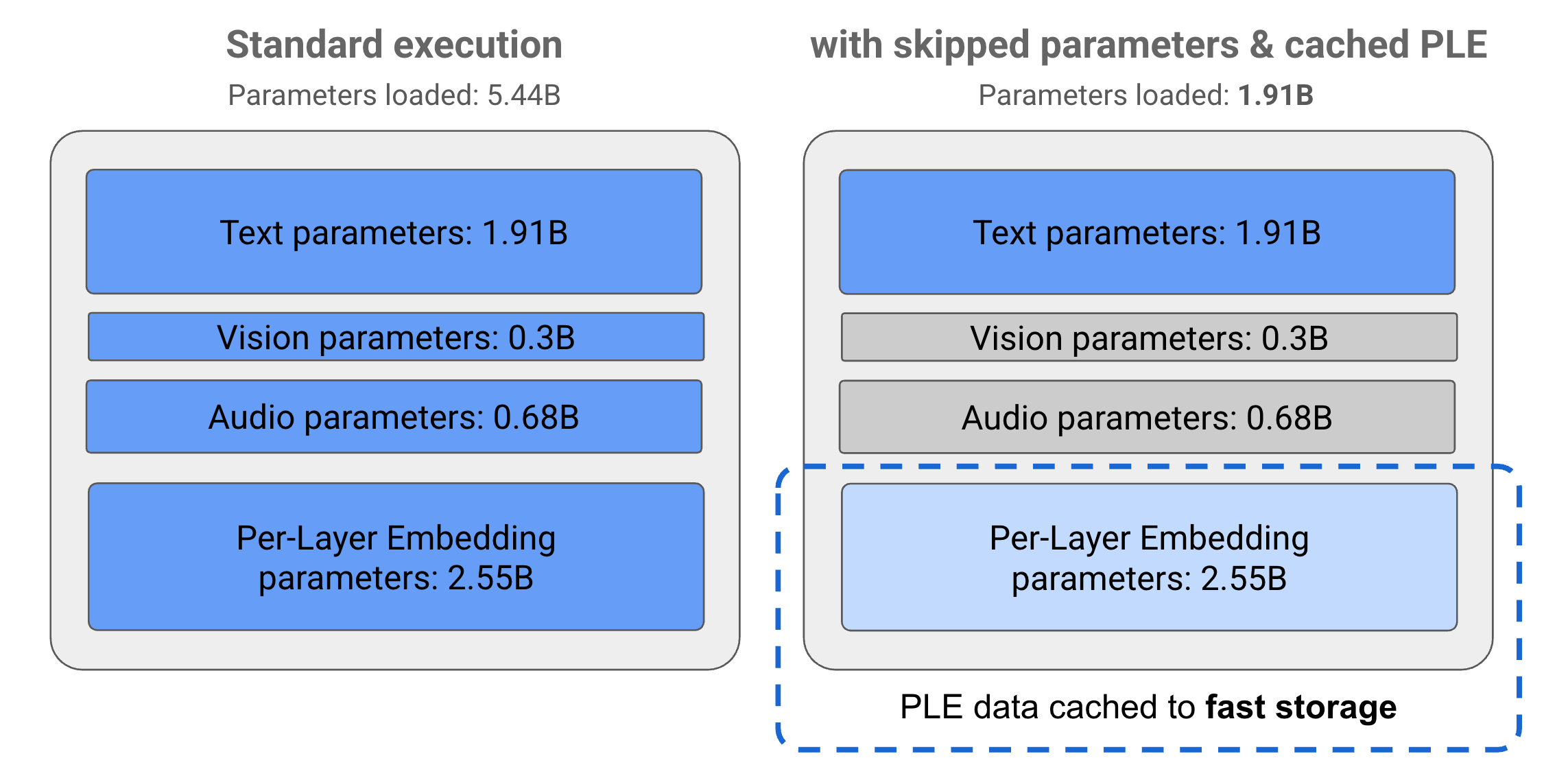
รูปที่ 1 พารามิเตอร์รูปแบบ Gemma 3n E2B ที่ทำงานในการดําเนินการแบบมาตรฐานเทียบกับโหลดพารามิเตอร์ที่ต่ำลงอย่างมีประสิทธิภาพโดยใช้เทคนิคการแคช PLE และการข้ามพารามิเตอร์
การใช้เทคนิคการถ่ายโอนพารามิเตอร์และการเปิดใช้งานแบบเลือกเหล่านี้จะช่วยให้คุณเรียกใช้โมเดลด้วยชุดพารามิเตอร์ที่น้อยมากหรือเปิดใช้งานพารามิเตอร์เพิ่มเติมเพื่อจัดการกับข้อมูลประเภทอื่นๆ เช่น รูปภาพและเสียง ฟีเจอร์เหล่านี้จะช่วยให้คุณเพิ่มฟังก์ชันการทำงานของโมเดลหรือลดความสามารถตามความสามารถของอุปกรณ์หรือข้อกำหนดของงานได้ ส่วนต่อไปนี้จะอธิบายเพิ่มเติมเกี่ยวกับเทคนิคที่มีประสิทธิภาพของพารามิเตอร์ที่มีในโมเดล Gemma 3n
การแคช PLE
โมเดล Gemma 3n มีพารามิเตอร์การฝังต่อเลเยอร์ (PLE) ที่ใช้ในระหว่างการเรียกใช้โมเดลเพื่อสร้างข้อมูลที่ช่วยเพิ่มประสิทธิภาพของเลเยอร์โมเดลแต่ละเลเยอร์ ข้อมูล PLE สามารถสร้างแยกต่างหากนอกหน่วยความจําของโมเดล แคชไว้ในพื้นที่เก็บข้อมูลแบบรวดเร็ว แล้วเพิ่มลงในกระบวนการอนุมานของโมเดลเมื่อแต่ละเลเยอร์ทํางาน แนวทางนี้ช่วยให้พารามิเตอร์ PLE ไม่ถูกเก็บไว้ในพื้นที่หน่วยความจำของโมเดล ซึ่งจะช่วยลดการใช้ทรัพยากรไปพร้อมกับปรับปรุงคุณภาพการตอบกลับของโมเดล
สถาปัตยกรรม MatFormer
โมเดล Gemma 3n ใช้สถาปัตยกรรมโมเดล Matryoshka Transformer หรือ MatFormer ซึ่งมีโมเดลขนาดเล็กที่ฝังอยู่ภายในโมเดลขนาดใหญ่โมเดลเดียว โมเดลย่อยที่ฝังอยู่สามารถใช้เพื่อการอนุมานได้โดยไม่ต้องเปิดใช้งานพารามิเตอร์ของโมเดลที่รวมอยู่เมื่อตอบสนองต่อคําขอ ความสามารถในการเรียกใช้เฉพาะโมเดลหลักขนาดเล็กภายในโมเดล MatFormer นี้จะช่วยประหยัดต้นทุนการประมวลผล รวมถึงเวลาในการตอบสนองและการใช้พลังงานของโมเดล ในกรณีของ Gemma 3n โมเดล E4B จะมีพารามิเตอร์ของโมเดล E2B สถาปัตยกรรมนี้ยังให้คุณเลือกพารามิเตอร์และประกอบโมเดลขนาดกลางระหว่าง 2B ถึง 4B ได้ด้วย ดูรายละเอียดเพิ่มเติมเกี่ยวกับแนวทางนี้ได้ที่เอกสารวิจัย MatFormer ลองใช้เทคนิค MatFormer เพื่อลดขนาดของโมเดล Gemma 3n ด้วยคำแนะนำในMatFormer Lab
การโหลดพารามิเตอร์แบบมีเงื่อนไข
ในรุ่น Gemma 3n คุณสามารถข้ามการโหลดพารามิเตอร์บางรายการลงในหน่วยความจำได้ เช่น พารามิเตอร์เสียงหรือภาพ เพื่อลดการโหลดหน่วยความจำ ซึ่งคล้ายกับพารามิเตอร์ PLE พารามิเตอร์เหล่านี้จะโหลดแบบไดนามิกขณะรันไทม์ได้หากอุปกรณ์มีทรัพยากรที่จําเป็น โดยรวมแล้ว การข้ามพารามิเตอร์จะช่วยลดหน่วยความจําที่ใช้งานจริงที่จําเป็นสําหรับรุ่น Gemma 3n ได้อีก ซึ่งช่วยให้สามารถใช้งานในอุปกรณ์ที่หลากหลายมากขึ้น และช่วยให้นักพัฒนาแอปเพิ่มประสิทธิภาพทรัพยากรสําหรับงานที่ต้องใช้ทรัพยากรไม่มากได้
หากพร้อมเริ่มสร้างแล้ว
เริ่มต้นใช้งานกับรุ่น Gemma