
Gemma 3n është një model gjenerues i AI i optimizuar për përdorim në pajisjet e përditshme, si telefonat, laptopët dhe tabletët. Ky model përfshin inovacione në përpunimin me efikasitet të parametrave, duke përfshirë ruajtjen e parametrave të futjes në shtresë (PLE) dhe një arkitekturë modeli MatFormer që ofron fleksibilitet për të reduktuar kërkesat e llogaritjes dhe kujtesës. Këto modele shfaqin trajtimin e hyrjes audio, si dhe të dhëna teksti dhe vizuale.
Gemma 3n përfshin karakteristikat kryesore të mëposhtme:
- Hyrja audio : Përpunoni të dhënat e zërit për njohjen e të folurit, përkthimin dhe analizën e të dhënave audio. Mësoni më shumë
- Futja vizuale dhe teksti : Aftësitë multimodale ju lejojnë të trajtoni vizionin, tingullin dhe tekstin për t'ju ndihmuar të kuptoni dhe analizoni botën përreth jush. Mësoni më shumë
- Enkoderi i vizionit: Enkoderi MobileNet-V5 me performancë të lartë përmirëson ndjeshëm shpejtësinë dhe saktësinë e përpunimit të të dhënave vizuale. Mësoni më shumë
- Memoria e memories PLE : Parametrat e ngulitjes për shtresa (PLE) të përfshira në këto modele mund të ruhen në memorien specifike në memorie të shpejtë, lokale për të reduktuar kostot e funksionimit të memories së modelit. Mësoni më shumë
- Arkitektura MatFormer: Arkitektura e transformatorit Matryoshka lejon aktivizimin selektiv të parametrave të modelit për kërkesë për të reduktuar koston e llogaritjes dhe kohën e përgjigjes. Mësoni më shumë
- Ngarkimi i parametrave të kushtëzuar: Anashkaloni ngarkimin e parametrave të shikimit dhe audios në model për të zvogëluar numrin total të parametrave të ngarkuar dhe për të kursyer burimet e kujtesës. Mësoni më shumë
- Mbështetje e gjerë gjuhësore : Aftësi të gjera gjuhësore, të trajnuara në mbi 140 gjuhë.
- Konteksti i tokenit 32K : Konteksti thelbësor i hyrjes për analizimin e të dhënave dhe trajtimin e detyrave të përpunimit.
Provoni Gemma 3n Merrni atë në Kaggle Merrni atë në Hugging Face
Ashtu si me modelet e tjera Gemma, Gemma 3n është i pajisur me pesha të hapura dhe i licencuar për përdorim komercial të përgjegjshëm, duke ju lejuar ta akordoni dhe ta vendosni në projektet dhe aplikacionet tuaja.
Parametrat e modelit dhe parametrat efektivë
Modelet Gemma 3n renditen me numërimin e parametrave, si E2B dhe E4B , që janë më të ulëta se numri i përgjithshëm i parametrave që përmbahen në modele. Prefiksi E tregon se këto modele mund të funksionojnë me një grup të reduktuar parametrash efektivë. Ky funksion i reduktuar i parametrave mund të arrihet duke përdorur teknologjinë e parametrave fleksibël të integruar në modelet Gemma 3n për t'i ndihmuar ata të funksionojnë me efikasitet në pajisjet me burime më të ulëta.
Parametrat në modelet Gemma 3n ndahen në 4 grupe kryesore: parametrat e tekstit, vizual, audio dhe ngulitje për shtresë (PLE). Me ekzekutimin standard të modelit E2B, mbi 5 miliardë parametra ngarkohen gjatë ekzekutimit të modelit. Megjithatë, duke përdorur teknikat e kapërcimit të parametrave dhe të memorizimit PLE, ky model mund të operohet me një ngarkesë efektive memorie prej pak më pak se 2 miliardë (1.91B) parametra, siç ilustrohet në Figurën 1.
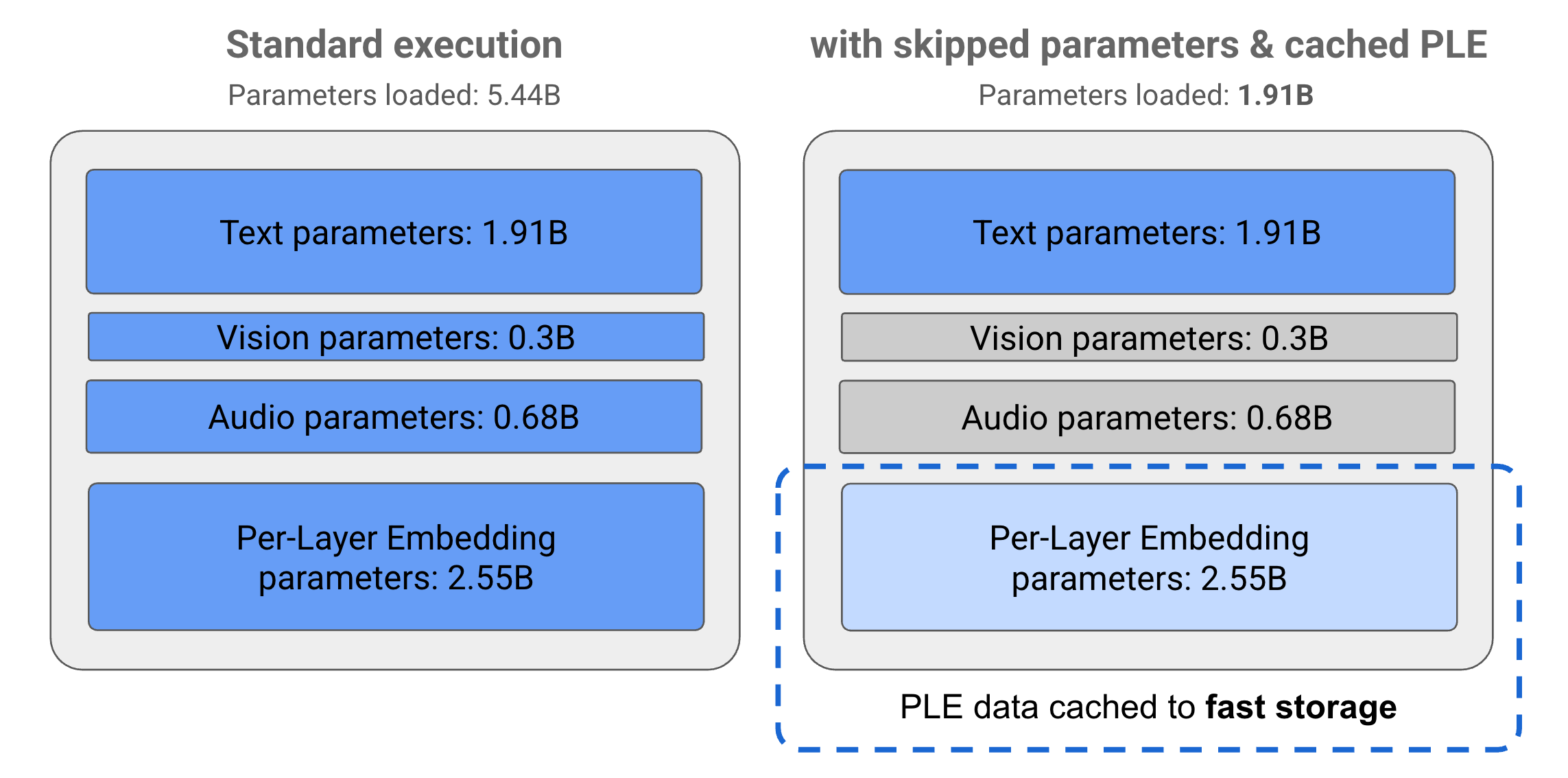
Figura 1. Parametrat e modelit Gemma 3n E2B që funksionojnë në ekzekutim standard kundrejt një ngarkese parametrash efektivisht më të ulët duke përdorur teknikat e ruajtjes së memories PLE dhe kalimit të parametrave.
Duke përdorur këto teknika të shkarkimit të parametrave dhe aktivizimit selektiv, mund ta ekzekutoni modelin me një grup parametrash shumë të dobët ose të aktivizoni parametra shtesë për të trajtuar lloje të tjera të dhënash si vizual dhe audio. Këto veçori ju mundësojnë të rritni funksionalitetin e modelit ose të zvogëloni aftësitë bazuar në aftësitë e pajisjes ose kërkesat e detyrave. Seksionet e mëposhtme shpjegojnë më shumë rreth teknikave efikase të parametrave të disponueshme në modelet Gemma 3n.
PLE memorie
Modelet Gemma 3n përfshijnë parametra Per-Layer Embedding (PLE) që përdoren gjatë ekzekutimit të modelit për të krijuar të dhëna që rrisin performancën e çdo shtrese modeli. Të dhënat PLE mund të gjenerohen veçmas, jashtë memories operative të modelit, të ruhen në memorie të fshehtë në ruajtje të shpejtë dhe më pas të shtohen në procesin e konkluzionit të modelit ndërsa çdo shtresë funksionon. Kjo qasje lejon që parametrat PLE të mbahen jashtë hapësirës së kujtesës së modelit, duke reduktuar konsumin e burimeve duke përmirësuar ende cilësinë e përgjigjes së modelit.
Arkitektura MatFormer
Modelet Gemma 3n përdorin një arkitekturë modeli Matryoshka Transformer ose MatFormer që përmban modele më të vogla brenda një modeli të vetëm, më të madh. Nën-modelet e ndërthurura mund të përdoren për konkluzione pa aktivizuar parametrat e modeleve mbyllëse kur iu përgjigjen kërkesave. Kjo aftësi për të ekzekutuar vetëm modelet më të vogla, thelbësore brenda një modeli MatFormer mund të zvogëlojë koston e llogaritjes, kohën e përgjigjes dhe gjurmën e energjisë për modelin. Në rastin e Gemma 3n, modeli E4B përmban parametrat e modelit E2B. Kjo arkitekturë ju lejon gjithashtu të zgjidhni parametra dhe të montoni modele në madhësi të ndërmjetme midis 2B dhe 4B. Për më shumë detaje mbi këtë qasje, shihni punimin kërkimor MatFormer . Provoni të përdorni teknikat MatFormer për të zvogëluar madhësinë e një modeli Gemma 3n me udhëzuesin MatFormer Lab .
Ngarkimi i parametrave të kushtëzuar
Ngjashëm me parametrat PLE, ju mund të anashkaloni ngarkimin e disa parametrave në memorie, të tilla si parametrat audio ose vizualë, në modelin Gemma 3n për të zvogëluar ngarkesën e memories. Këto parametra mund të ngarkohen në mënyrë dinamike në kohën e ekzekutimit nëse pajisja ka burimet e nevojshme. Në përgjithësi, kapërcimi i parametrave mund të zvogëlojë më tej kujtesën e nevojshme të funksionimit për një model Gemma 3n, duke mundësuar ekzekutimin në një gamë më të gjerë pajisjesh dhe duke lejuar zhvilluesit të rrisin efikasitetin e burimeve për detyra më pak të vështira.
Gati për të filluar ndërtimin? Filloni me modelet Gemma!