Gemini può gestire contemporaneamente vari tipi di dati di input, tra cui testo, immagini e audio.
Questa guida mostra come utilizzare i file multimediali utilizzando l'API Files. Le operazioni di base sono le stesse per file audio, immagini, video, documenti e altri tipi di file supportati.
Per indicazioni sui prompt dei file, consulta la sezione Guida ai prompt dei file.
Carica un file
Puoi utilizzare l'API Files per caricare un file multimediale. Utilizza sempre l'API Files quando la dimensione totale della richiesta (inclusi i file, il prompt di testo, le istruzioni di sistema, ecc.) è superiore a 100 MB. Per i file PDF, il limite è 50 MB.
Il seguente codice carica un file e lo utilizza in una chiamata a
interactions.create.
Python
from google import genai
client = genai.Client()
myfile = client.files.upload(file="path/to/sample.mp3")
interaction = client.interactions.create(
model="gemini-3.5-flash",
input=[
{"type": "text", "text": "Describe this audio clip"},
{"type": "audio", "uri": myfile.uri, "mime_type": myfile.mime_type}
]
)
print(interaction.output_text)
JavaScript
import { GoogleGenAI } from "@google/genai";
const client = new GoogleGenAI({});
async function main() {
const myfile = await client.files.upload({
file: "path/to/sample.mp3",
config: { mime_type: "audio/mpeg" },
});
const interaction = await client.interactions.create({
model: "gemini-3.5-flash",
input: [
{ type: "text", text: "Describe this audio clip" },
{ type: "audio", uri: myfile.uri, mime_type: myfile.mimeType }
]
});
console.log(interaction.output_text);
}
await main();
Go
file, err := client.Files.UploadFromPath(ctx, "path/to/sample.mp3", nil)
if err != nil {
log.Fatal(err)
}
defer client.Files.Delete(ctx, file.Name)
interaction, err := client.Interactions.Create(ctx, "gemini-3.5-flash", &genai.InteractionRequest{
Input: []interface{}{
genai.NewPartFromFile(*file),
genai.NewPartFromText("Describe this audio clip"),
},
}, nil)
if err != nil {
log.Fatal(err)
}
// Print the model's text response
for _, step := range interaction.Steps {
if step.Type == "model_output" {
for _, part := range step.Content {
if part.Type == "text" {
fmt.Println(part.Text)
}
}
}
}
REST
AUDIO_PATH="path/to/sample.mp3"
MIME_TYPE=$(file -b --mime-type "${AUDIO_PATH}")
NUM_BYTES=$(wc -c < "${AUDIO_PATH}")
DISPLAY_NAME=AUDIO
tmp_header_file=upload-header.tmp
# Initial resumable request defining metadata.
# The upload url is in the response headers dump them to a file.
curl "${BASE_URL}/upload/v1beta/files" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-D "${tmp_header_file}" \
-H "X-Goog-Upload-Protocol: resumable" \
-H "X-Goog-Upload-Command: start" \
-H "X-Goog-Upload-Header-Content-Length: ${NUM_BYTES}" \
-H "X-Goog-Upload-Header-Content-Type: ${MIME_TYPE}" \
-H "Content-Type: application/json" \
-d "{'file': {'display_name': '${DISPLAY_NAME}'}}" 2> /dev/null
upload_url=$(grep -i "x-goog-upload-url: " "${tmp_header_file}" | cut -d" " -f2 | tr -d "\r")
rm "${tmp_header_file}"
# Upload the actual bytes.
curl "${upload_url}" \
-H "Content-Length: ${NUM_BYTES}" \
-H "X-Goog-Upload-Offset: 0" \
-H "X-Goog-Upload-Command: upload, finalize" \
--data-binary "@${AUDIO_PATH}" 2> /dev/null > file_info.json
file_uri=$(jq ".file.uri" file_info.json)
echo file_uri=$file_uri
# Now create an interaction using the Interactions API
curl -X POST "https://generativelanguage.googleapis.com/v1beta/interactions" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-d '{
"model": "gemini-3.5-flash",
"input": [
{"type": "text", "text": "Describe this audio clip"},
{"type": "audio", "uri": '$file_uri', "mime_type": "'${MIME_TYPE}'"}
]
}' 2> /dev/null > response.json
cat response.json
echo
jq ".outputs[] | select(.type == \"text\") | .text" response.json
Recuperare i metadati di un file
Puoi verificare che l'API abbia archiviato correttamente il file caricato e recuperare i relativi metadati chiamando files.get.
Python
from google import genai
client = genai.Client()
myfile = client.files.upload(file='path/to/sample.mp3')
file_name = myfile.name
myfile = client.files.get(name=file_name)
print(myfile)
JavaScript
import {
GoogleGenAI,
} from "@google/genai";
const client = new GoogleGenAI({});
async function main() {
const myfile = await client.files.upload({
file: "path/to/sample.mp3",
config: { mime_type: "audio/mpeg" },
});
const fileName = myfile.name;
const fetchedFile = await client.files.get({ name: fileName });
console.log(fetchedFile);
}
await main();
Go
file, err := client.Files.UploadFromPath(ctx, "path/to/sample.mp3", nil)
if err != nil {
log.Fatal(err)
}
gotFile, err := client.Files.Get(ctx, file.Name)
if err != nil {
log.Fatal(err)
}
fmt.Println("Got file:", gotFile.Name)
REST
# file_info.json was created in the upload example
name=$(jq -r ".file.name" file_info.json)
# Get the file of interest to check state
curl https://generativelanguage.googleapis.com/v1beta/$name \
-H "x-goog-api-key: $GEMINI_API_KEY" > file_info.json
# Print some information about the file you got
name=$(jq -r ".name" file_info.json)
echo name=$name
file_uri=$(jq -r ".uri" file_info.json)
echo file_uri=$file_uri
Elencare i file caricati
Il seguente codice recupera un elenco di tutti i file caricati:
Python
from google import genai
client = genai.Client()
print('My files:')
for f in client.files.list():
print(' ', f.name)
JavaScript
import {
GoogleGenAI,
} from "@google/genai";
const client = new GoogleGenAI({});
async function main() {
const listResponse = await client.files.list({ config: { pageSize: 10 } });
for await (const file of listResponse) {
console.log(file.name);
}
}
await main();
Go
for file, err := range client.Files.All(ctx) {
if err != nil {
log.Fatal(err)
}
fmt.Println(file.Name)
}
REST
echo "My files: "
curl "https://generativelanguage.googleapis.com/v1beta/files" \
-H "x-goog-api-key: $GEMINI_API_KEY"
Eliminare i file caricati
I file vengono eliminati automaticamente dopo 48 ore. Puoi anche eliminare manualmente un file caricato:
Python
from google import genai
client = genai.Client()
myfile = client.files.upload(file='path/to/sample.mp3')
client.files.delete(name=myfile.name)
JavaScript
import {
GoogleGenAI,
} from "@google/genai";
const client = new GoogleGenAI({});
async function main() {
const myfile = await client.files.upload({
file: "path/to/sample.mp3",
config: { mime_type: "audio/mpeg" },
});
const fileName = myfile.name;
await client.files.delete({ name: fileName });
}
await main();
Go
file, err := client.Files.UploadFromPath(ctx, "path/to/sample.mp3", nil)
if err != nil {
log.Fatal(err)
}
client.Files.Delete(ctx, file.Name)
REST
curl --request "DELETE" https://generativelanguage.googleapis.com/v1beta/$name \
-H "x-goog-api-key: $GEMINI_API_KEY"
Informazioni sull'utilizzo
Puoi utilizzare l'API Files per caricare e interagire con i file multimediali. L'API Files consente di archiviare fino a 20 GB di file per progetto, con una dimensione massima di 2 GB per file. I file vengono archiviati per 48 ore. Durante questo periodo, puoi utilizzare l'API per ottenere i metadati dei file, ma non puoi scaricarli. L'API Files è disponibile senza costi in tutte le regioni in cui è disponibile l'API Gemini.
Strategie di richiesta di file
Questa sezione fornisce indicazioni e best practice per l'utilizzo di file multimediali con prompt per l'API Gemini.
La possibilità di utilizzare vari tipi di dati nei prompt ti offre maggiore flessibilità in termini di attività che puoi svolgere con l'API Gemini. Ad esempio, puoi inviare al modello la foto di un pasto delizioso e chiedergli di scrivere un breve post del blog sul pasto.
| Prompt | Risposta |
|
Scrivi un breve post del blog coinvolgente basato su questa immagine. Deve includere una descrizione del pasto nella foto e parlare del mio percorso di preparazione dei pasti. 
|
Preparare i pasti in anticipo è un ottimo modo per risparmiare tempo e denaro e può anche aiutarti a mangiare in modo più sano. Questo pasto è un ottimo esempio di piatto sano e delizioso che può essere preparato in anticipo. Questo pasto include riso integrale, verdure arrosto e pollo teriyaki. Il riso integrale è un carboidrato sano e complesso che ti darà energia costante. Le verdure arrosto sono un ottimo modo per assumere la dose giornaliera di vitamine e minerali, mentre il pollo teriyaki è un'opzione deliziosa e ricca di proteine. Anche questo pasto è semplice da preparare. Cuoci il riso integrale, arrostisci le verdure e prepara il pollo teriyaki. Una volta cotto tutto, dividi il cibo in contenitori per la preparazione dei pasti e conservali in frigorifero. Così potrai prendere un contenitore e andare via nelle mattine più frenetiche. Se stai cercando un pasto sano e delizioso che puoi preparare in anticipo, questa è un'ottima opzione. È ricco di nutrienti e sapore e ti farà sentire sazio e soddisfatto. Brindiamo a una preparazione dei pasti sana e deliziosa. |
Se hai difficoltà a ottenere l'output che desideri dai prompt che utilizzano file multimediali, esistono alcune strategie che possono aiutarti a ottenere i risultati che desideri. Le sezioni seguenti forniscono approcci di progettazione e suggerimenti per la risoluzione dei problemi per migliorare i prompt che utilizzano input multimodali.
Puoi migliorare i prompt multimodali seguendo queste best practice:
-
Principi fondamentali della progettazione dei prompt
- Fornisci istruzioni specifiche: crea istruzioni chiare e concise che lascino poco spazio a interpretazioni errate.
- Aggiungi alcuni esempi al prompt:utilizza esempi few-shot realistici per illustrare ciò che vuoi ottenere.
- Suddividi l'attività passo passo: dividi le attività complesse in sotto-obiettivi gestibili, guidando il modello nel processo.
- Specifica il formato di output: nel prompt, chiedi che l'output sia nel formato che preferisci, ad esempio Markdown, JSON, HTML e altri.
- Inserisci prima l'immagine per i prompt con una sola immagine: anche se Gemini può gestire input di immagini e testo in qualsiasi ordine, per i prompt contenenti una sola immagine, potrebbe funzionare meglio se l'immagine (o il video) viene inserita prima del prompt di testo. Tuttavia, per i prompt che richiedono che le immagini siano altamente intercalate con i testi per avere un senso, utilizza l'ordine più naturale.
-
Risoluzione dei problemi relativi al prompt multimodale
- Se il modello non estrae informazioni dalla parte pertinente dell'immagine:fornisci suggerimenti sugli aspetti dell'immagine da cui vuoi che il prompt estragga informazioni.
- Se l'output del modello è troppo generico (non abbastanza personalizzato in base all'input di immagine/video): all'inizio del prompt, prova a chiedere al modello di descrivere l'immagine o le immagini o il video prima di fornire l'istruzione dell'attività oppure prova a chiedere al modello di fare riferimento a ciò che è presente nell'immagine.
- Per risolvere il problema relativo alla parte non riuscita:chiedi al modello di descrivere l'immagine o di spiegare il suo ragionamento per valutare la comprensione iniziale del modello.
- Se il prompt genera contenuti di allucinazione:prova a ridurre l'impostazione della temperatura o a chiedere al modello descrizioni più brevi, in modo che sia meno probabile che estrapoli ulteriori dettagli.
- Ottimizzazione dei parametri di campionamento:sperimenta diverse impostazioni di temperatura e selezioni top-k per regolare la creatività del modello.
Fornisci istruzioni specifiche
I prompt hanno più successo quando sono chiari e dettagliati. Se hai in mente un output specifico, è meglio includere questo requisito nel prompt per assicurarti di ottenere l'output che desideri.
Per questa immagine di un tabellone di un aeroporto, chiedere al modello di "descrivere questa immagine" potrebbe generare una descrizione generica. Se hai bisogno che il modello analizzi l'ora e la città dall'immagine, puoi includere la richiesta direttamente nel prompt.
| Prompt | Risposta del modello |
|---|---|

Descrivi questa immagine. |
L'immagine mostra un tabellone degli arrivi e delle partenze di un aeroporto. |
| Prompt aggiornato | Risposta migliorata |
|---|---|
Analizza l'ora e la città dal tabellone dell'aeroporto mostrato in questa immagine in un elenco. |
Aggiungi alcuni esempi
Il modello Gemini può accettare più input che può utilizzare come esempi per comprendere l'output che vuoi. L'aggiunta di questi esempi può aiutare il modello a identificare i pattern e applicare la relazione tra le immagini e le risposte fornite al nuovo esempio. Questo metodo è anche chiamato apprendimento "few-shot".
Nell'esempio seguente, l'output iniziale è scritto in forma di frase e contiene anche il paese (Brasile). Supponiamo che tu voglia l'output in un formato o stile diverso e che tu voglia solo la città, non il paese. L'aggiunta di esempi few-shot al prompt può indirizzare il modello a rispondere nel modo che preferisci.
| Prompt | Risposta del modello |
|---|---|
 Determina la città insieme al punto di riferimento. |
Il punto di riferimento è la statua del Cristo Redentore a Rio de Janeiro, in Brasile. |
| Prompt aggiornato | Risposta migliorata |
|---|---|
|
Determina la città insieme al punto di riferimento. 
|
città: Roma, monumento: il Colosseo. |

|
città: Pechino, punto di riferimento: Città Proibita |
|
|
città: Rio de Janeiro, punto di riferimento: statua del Cristo Redentore |
Analizza passo passo
Per attività complesse come quelle che richiedono sia la comprensione visiva sia il ragionamento, può essere utile suddividere l'attività in passaggi più piccoli e semplici. In alternativa, potrebbe essere efficace anche se chiedi direttamente al modello di "pensare passo dopo passo" nel prompt.
| Prompt | Risposta del modello |
|---|---|

Quando finirà la carta igienica? |
A breve, ti rimarranno solo 3 rotoli. |
| Prompt aggiornato | Risposta migliorata |
|---|---|
|
|
I problemi di matematica o altri tipi di problemi con enunciato sono ottimi candidati per chiedere al modello di procedere passo dopo passo.
| Prompt | Risposta |
|---|---|
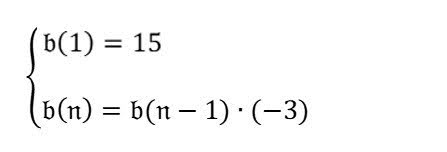
Qual è il quarto termine della sequenza? |
-135 |
La risposta del modello non è corretta. Alcuni modi per migliorare questo aspetto sono chiedere al modello di analizzare il problema prima di rispondere al prompt.
| Prompt | Risposta |
|---|---|
|
Analizza prima la formula nell'immagine. Quindi, in base alla formula, rispondi alla domanda "Qual è il quarto termine della sequenza?". |
Fai clic per espandere il risultato$$ b(n) = b(n-1) * (-3) $$ $$ b(1) = 15 $$
Pertanto, il quarto termine della sequenza è -405. |
La risposta del modello è corretta. Per renderla ancora più snella, puoi chiedere al modello di procedere passo dopo passo.
| Prompt aggiornato | Risposta migliorata |
|---|---|
|
Qual è il quarto termine della sequenza? Pensa passo dopo passo. |
Il primo termine è 15. Il secondo termine è b(1) * (-3) = 15 * (-3) = -45. Il terzo termine è b(2) * (-3) = -45 * (-3) = 135. Il quarto termine è b(3) * (-3) = 135 * (-3) = -405. |
Specifica il formato di output
Un problema comune è la necessità che l'output del modello sia in un determinato formato (ad es. Markdown, JSON, HTML), soprattutto se l'output del modello deve essere inserito in un'attività a valle. Puoi provare a produrre output in questo formato chiedendo al modello di farlo all'interno del prompt. Di seguito sono riportati due esempi:
| Prompt | Risposta del modello |
|---|---|
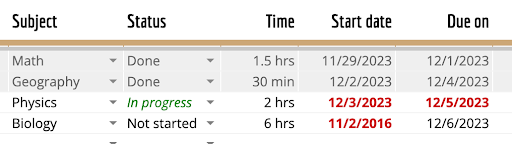
Analizza la tabella in questa immagine nel formato Markdown |
```none | Materia | Stato | Tempo | Data di inizio | Scadenza | | ------- | ------ | ---- | ---------- | ------ | | Matematica | Completato | 1,5 ore | 29/11/2023 | 1/12/2023 | | Geografia | Completato | 30 minuti | 2/12/2023 | 4/12/2023 | | Fisica | In corso | 2 ore | 3/12/2023 | 5/12/2023 | | Biologia | Non iniziato | 6 ore | 2/11/2016 | 6/12/2023 | ``` |
| Prompt | Risposta del modello |
|---|---|

Fornisci un elenco di tutti i seguenti attributi: ingredienti, tipo di cucina, vegetariano o meno, in formato JSON |
```json { "ingredients": [ "rice", "shrimp", "clams", "mussels", "peas", "tomatoes", "onions", "garlic", "olive oil", "paprika", "salt", "pepper" ], "type of cuisine": "Spanish", "vegetarian": false } ``` |
Inserisci prima l'immagine per i prompt con una sola immagine
Sebbene Gemini possa interpretare immagini e testo in qualsiasi ordine all'interno di un prompt, inserire una singola immagine prima del prompt di testo potrebbe portare a risultati migliori. Negli esempi seguenti, noterai che l'immagine viene prima del testo in ogni prompt.
Risolvere i problemi relativi al prompt multimodale
Potresti dover risolvere i problemi relativi al prompt se non ricevi una risposta utile. Ecco alcune strategie che puoi provare.
Se il modello non estrae informazioni dalla parte pertinente dell'immagine
Per ottenere una risposta più specifica, puoi indicare gli aspetti dell'immagine da cui vuoi che il prompt estragga le informazioni per elaborare la risposta.
| Prompt | Risposta del modello |
|---|---|

Per quanti giorni dureranno questi pannolini per un bambino? |
I pannolini dureranno 198 giorni prima di esaurirsi. |
| Prompt aggiornato | Risposta migliorata |
|---|---|
|
Per quanto tempo dureranno questi pannolini prima che finiscano? Utilizza il peso indicato sulla confezione per determinare l'età del bambino e il numero totale di pannolini nella confezione. Dividi il numero totale per il numero di pannolini che il bambino usa al giorno. |
La confezione contiene 198 pannolini. La confezione indica che i pannolini sono adatti a un bambino di peso compreso tra 10 e 17 kg. Il bambino medio in questa fascia di peso ha probabilmente un'età compresa tra 1 e 2 anni. Un bambino di 2 anni in genere usa 6 pannolini al giorno, quindi i pannolini dureranno circa 33 giorni (198/6). |
Se l'output del modello è troppo generico e non sufficientemente personalizzato in base all'input dell'immagine
Per aiutare il modello a personalizzare la risposta in base alle immagini, prova a chiedergli di descriverle prima di eseguire il compito di ragionamento.
| Prompt | Risposta del modello |
|---|---|



Cosa hanno in comune queste immagini? |
Tutte e quattro le immagini sono esempi di fotografia paesaggistica. |
| Prompt aggiornato | Risposta migliorata |
|---|---|
|
Per prima cosa, descrivi in dettaglio i contenuti di ogni immagine. Che cosa hanno in comune queste immagini? |
La prima immagine mostra una persona che prepara una valigia. La seconda immagine mostra un corridoio vuoto in un centro commerciale. La terza immagine mostra un rotolo di carta igienica. La quarta immagine mostra un mare scuro e tempestoso. Il punto in comune tra queste immagini è che sono tutti esempi di spazi liminali. Gli spazi liminali sono luoghi o situazioni che si trovano tra due altri luoghi o situazioni. Sono spesso caratterizzati da un senso di incertezza o ambiguità. La prima immagine mostra la persona tra la casa e il viaggio. La seconda immagine mostra il corridoio tra due negozi. La terza immagine è di carta igienica, che può rappresentare un bagno. Il bagno è uno spazio di transizione tra la sfera privata e quella pubblica. È un luogo in cui ci prepariamo a entrare o uscire dal mondo esterno. La quarta immagine mostra il mare in una condizione intermedia tra calma e tempesta. Gli spazi liminali possono essere sia entusiasmanti che inquietanti. Possono essere un luogo di nuovi inizi o di fine. Possono essere un luogo di riflessione o di azione. |
Puoi anche provare a chiedere esplicitamente al modello di fare riferimento a ciò che è presente nell'immagine.
| Prompt aggiornato | Risposta migliorata |
|---|---|
|
Cosa hanno in comune queste immagini? Fai riferimento al contenuto delle immagini nella risposta. |
Tutte le immagini sono correlate ai viaggi. La prima immagine mostra una persona che prepara una valigia, la seconda mostra un corridoio vuoto in un centro commerciale, la terza mostra una pila di carta igienica e la quarta mostra un mare scuro e tempestoso. Queste immagini sono tutte correlate ai viaggi perché sono tutte cose che le persone hanno bisogno o usano quando viaggiano. La prima immagine mostra una persona che prepara una valigia, un'attività che si svolge prima di un viaggio. La seconda immagine mostra un corridoio vuoto in un centro commerciale, un luogo in cui le persone vanno spesso per comprare cose per i loro viaggi. La terza immagine mostra una pila di carta igienica, un oggetto che le persone usano spesso quando sono in viaggio. La quarta immagine mostra un mare scuro e tempestoso, che è qualcosa che le persone incontrano spesso quando viaggiano. |
Gli stessi suggerimenti valgono per l'output creativo delle immagini. Nel seguente esempio con il coniglio, chiedere esplicitamente al modello di includere aspetti dell'immagine può migliorare l'output.
| Prompt | Risposta del modello |
|---|---|

Puoi scrivermi una poesia su questa immagine? |
Coniglietto, così morbido e marrone, Mangi l'erba, così verde e dolce, |
| Prompt aggiornato | Risposta migliorata |
|---|---|
|
Puoi scrivermi una poesia descrittiva e drammatica su questa immagine e includere la posizione? |
Coniglietto sul prato, È il blu dell'oceano, Coniglietto, dimmi la verità, Forse è la sua vastità, Coniglietto, mi chiedo cosa sogni, Qualunque cosa sia, coniglietto, |
Risoluzione dei problemi relativi alla parte del prompt non riuscita
Può essere difficile capire se un prompt non è riuscito perché il modello non ha compreso l'immagine fin dall'inizio o se ha compreso l'immagine ma non ha eseguito i passaggi di ragionamento corretti in seguito. Per distinguere tra questi motivi, chiedi al modello di descrivere il contenuto dell'immagine.
Nell'esempio seguente, se il modello risponde con uno snack che sembra sorprendente se abbinato al tè (ad es. popcorn), puoi prima risolvere il problema per determinare se il modello ha riconosciuto correttamente che l'immagine contiene tè.
| Prompt | Richiesta di risoluzione dei problemi |
|---|---|

Qual è uno snack che posso preparare in un minuto e che si abbini bene a questo? |
Descrivi i contenuti di questa immagine. |
Un'altra strategia consiste nel chiedere al modello di spiegare il suo ragionamento. In questo modo puoi restringere la parte del ragionamento che non ha funzionato, se presente.
| Prompt | Richiesta di risoluzione dei problemi |
|---|---|
|
Qual è uno snack che posso preparare in un minuto e che si abbini bene a questo? |
Qual è uno snack che posso preparare in un minuto e che si abbini bene a questo? Spiega perché. |
Passaggi successivi
- Prova a scrivere i tuoi prompt multimodali utilizzando Google AI Studio.
- Per informazioni sull'utilizzo dell'API Gemini Files per caricare file multimediali e includerli nei prompt, consulta le guide Vision, Audio ed Elaborazione dei documenti.
- Per ulteriori indicazioni sulla progettazione dei prompt, ad esempio sulla regolazione dei parametri di campionamento, consulta la pagina Strategie per i prompt.