
Gemma 3
Eine Sammlung einfacher, hochmoderner offener Modelle, die auf derselben Forschung und Technologie basieren, die auch für die Erstellung unserer Gemini 2.0-Modelle verwendet werden

Komplexe Aufgaben bewältigen
Mit dem 128.000-Token-Kontextfenster von Gemma 3 können Ihre Anwendungen riesige Mengen an Informationen verarbeiten und verstehen, was ausgefeiltere KI-Funktionen ermöglicht.

Sofort weltweit werben
Mit den beispiellosen mehrsprachigen Funktionen von Gemma 3 können Sie mühelos zwischen verschiedenen Sprachen wechseln. Entwickeln Sie Anwendungen, die eine globale Zielgruppe erreichen, mit Unterstützung für über 140 Sprachen.

Wörter und Bilder verstehen
Sie können ganz einfach Anwendungen erstellen, die Bilder, Text und Video analysieren. So eröffnen sich neue Möglichkeiten für interaktive und intelligente Anwendungen.
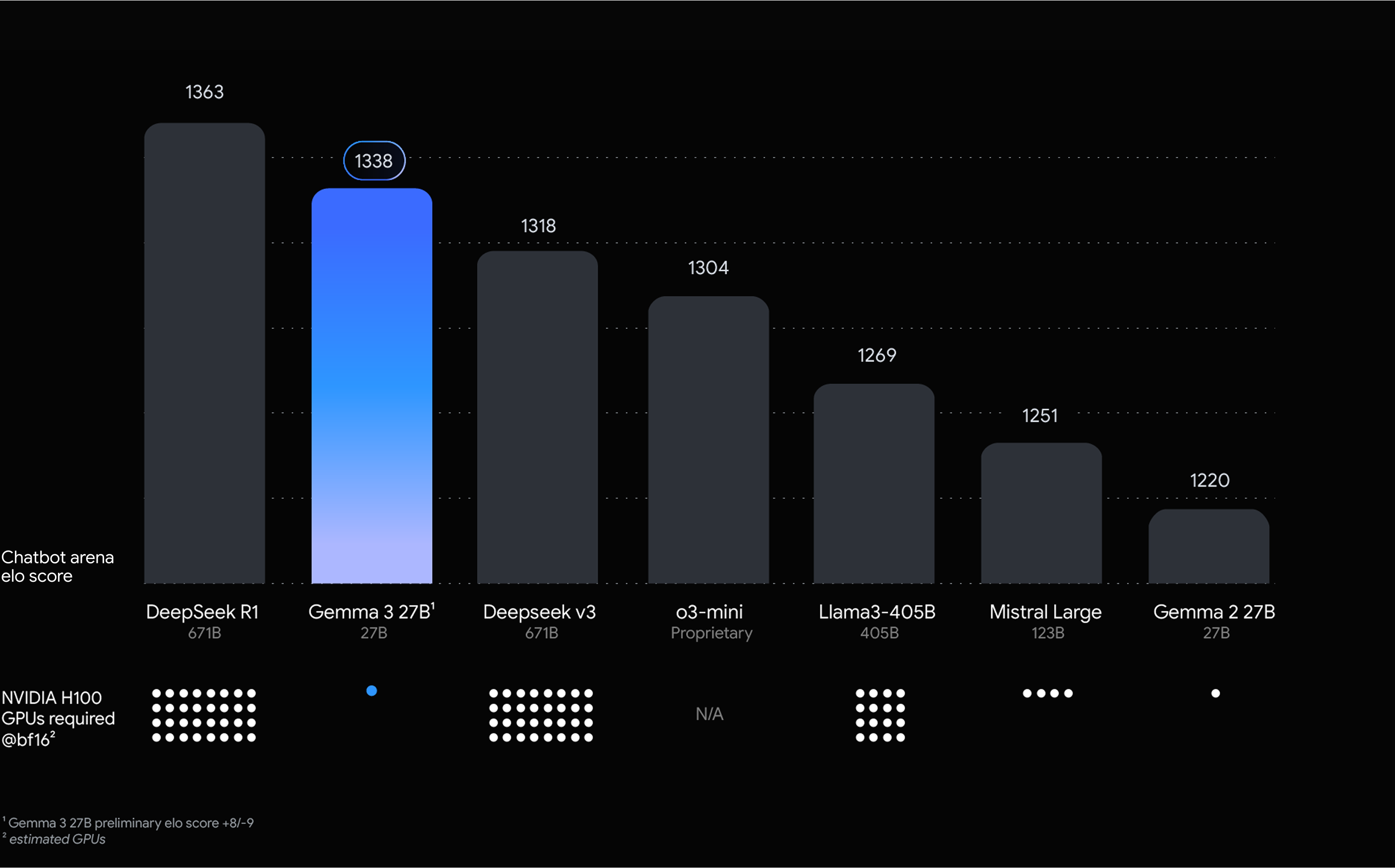
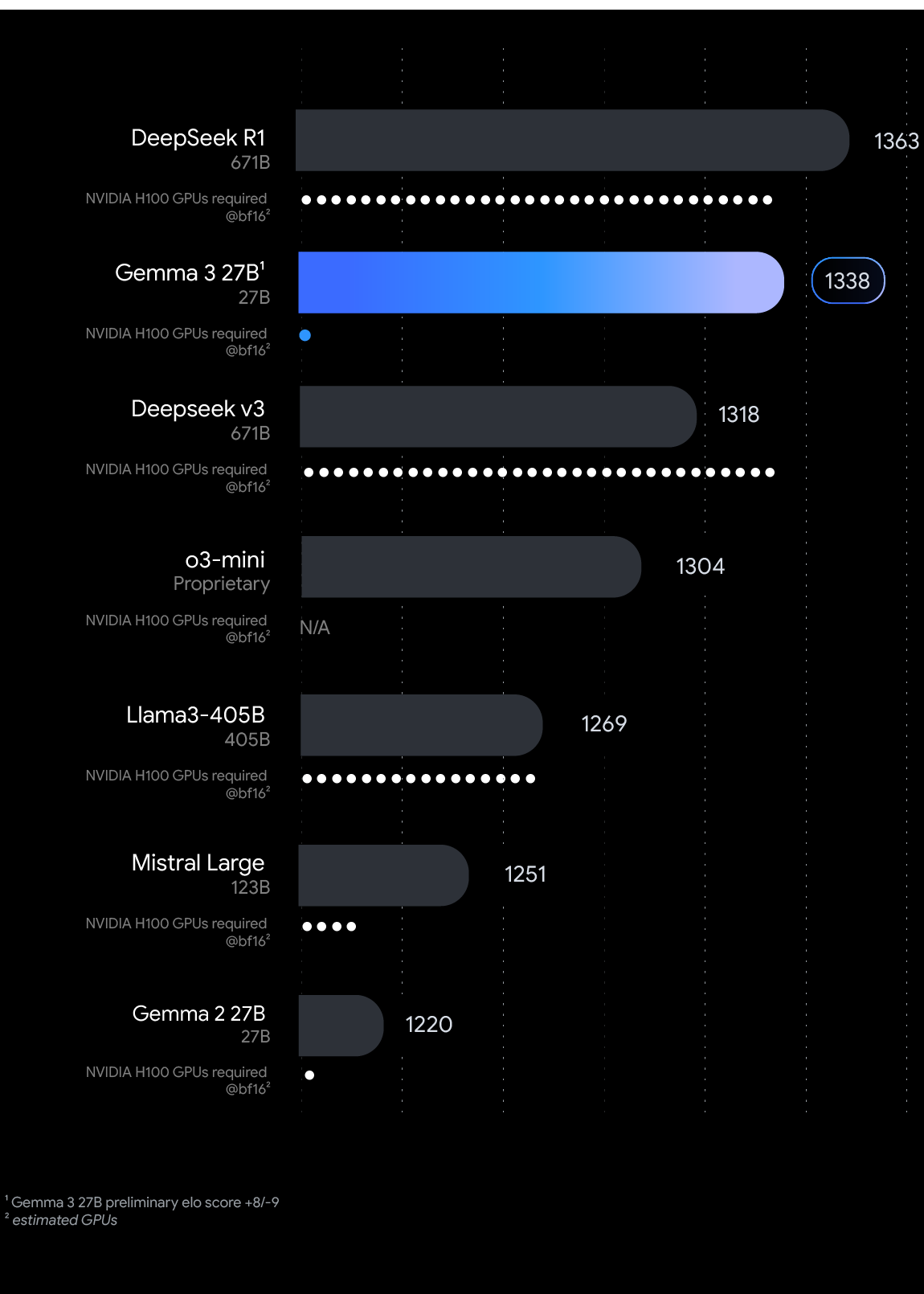
Mit dem weltweit besten Modell mit einem einzelnen Beschleuniger entwickeln
Jetzt mit Gemma loslegen
Gemma-Leitfaden
Praxisbeispiele und Anleitungen für die offenen Modelle von Google
Notebooks ansehen




Forschung mit Gemma voranbringen
Entdecken Sie eine wachsende Sammlung spezialisierter Gemma-Modelle für erweiterte Recherchen.
TxGemma neu

ShieldGemma 2 neu
PaliGemma 2 Neu
Gemma-Umfang
Gemma 3-Benchmarks visualisieren
Interagieren Sie mit dem Diagramm, um die Ergebnisse von Gemma 3 für verschiedene LLM-Benchmarks zu sehen.
MMLU-Pro
Der MMLU-Benchmark ist ein Test, mit dem das Wissen und die Problemlösungsfähigkeiten gemessen werden, die Large Language Models während des Vortrainings erwerben.
LiveCodeBench
Hier werden die Codegenerierungsfunktionen anhand realer Programmierprobleme von Plattformen wie LeetCode und Codeforces bewertet.
dev
Bird-SQL
Hier wird die Fähigkeit eines Modells getestet, Fragen in natürlicher Sprache in komplexe SQL-Abfragen in verschiedenen Bereichen umzuwandeln.
GPQA Diamond
Die Modelle werden mit schwierigen Fragen von Doktoranden aus Biologie, Physik und Chemie herausgefordert.
SimpleQA
Hier wird die Fähigkeit eines Modells bewertet, einfache, sachliche Fragen mit kurzen Sätzen zu beantworten.
FACTS Grounding
Bewertet, ob LLM-Antworten auf der Grundlage der angegebenen Eingabedokumente sachlich korrekt und detailliert genug sind.
MATH
MATH prüft die Fähigkeit eines Sprachmodells, komplexe mathematische Textaufgaben zu lösen, die Schlussfolgerungen, mehrstufige Problemlösungen und das Verständnis mathematischer Konzepte erfordern.
HiddenMath
Ein interner Testsatz mit Mathematikaufgaben für den Wettbewerb.
val
MMMU
Hier wird das multimodale Verständnis und die Argumentation in verschiedenen Disziplinen bewertet, die ein Hochschulwissen erfordern.
100 %
75 %
50 %
25 %
0 %
100 %
75 %
50 %
25 %
0 %
*Im technischen Bericht finden Sie Details zur Leistung mit anderen Methoden. Technischen Bericht lesen



Gemmaverse entdecken
Ein umfangreiches Ökosystem aus von der Community erstellten Gemma-Modellen und ‑Tools, die Sie bei der Entwicklung innovativer Lösungen unterstützen
Bereitstellungsziel auswählen
![]() Mobilgeräte
Mobilgeräte
On-Device-Bereitstellung mit Google AI Edge
Direkt auf Geräten bereitstellen, um eine geringe Latenz und Offlinefunktionen zu ermöglichen. Ideal für Anwendungen, die eine Echtzeitreaktion und Datenschutz erfordern, z. B. mobile Apps, IoT-Geräte und eingebettete Systeme.
![]() Web
Web
Nahtlose Integration in Webanwendungen
Nutzen Sie erweiterte KI-Funktionen für Ihre Websites und Webdienste, um interaktive Funktionen, personalisierte Inhalte und intelligente Automatisierung zu ermöglichen.
![]() Cloud
Cloud
Mühelos mit Cloud-Infrastruktur skalieren
Nutzen Sie die Skalierbarkeit und Flexibilität der Cloud, um große Bereitstellungen, anspruchsvolle Arbeitslasten und komplexe KI-Anwendungen zu bewältigen.