
Gemma 3n 是一种生成式 AI 模型,经过优化,可在手机、笔记本电脑和平板电脑等日常设备上使用。此模型在参数高效处理方面进行了创新,包括每层嵌入 (PLE) 参数缓存和 MatFormer 模型架构,可灵活地降低计算和内存要求。这些模型支持音频输入处理,以及文本和视觉数据。
Gemma 3n 具有以下主要功能:
- 音频输入:处理声音数据以进行语音识别、翻译和音频数据分析。了解详情
- 视觉和文本输入:借助多模态功能,您可以处理视觉、声音和文本,从而帮助您了解和分析周围环境。了解详情
- 视觉编码器:高性能 MobileNet-V5 编码器显著提高了处理视觉数据的速度和准确性。了解详情
- PLE 缓存:这些模型中包含的每层嵌入 (PLE) 参数可以缓存在快速的本地存储空间中,以降低模型内存运行开销。了解详情
- MatFormer 架构:Matryoshka Transformer 架构支持按请求选择性激活模型参数,以降低计算费用和响应时间。了解详情
- 有条件的参数加载:绕过模型中的视觉和音频参数加载,以减少加载的参数总数并节省内存资源。了解详情
- 支持众多语言:具备广泛的语言能力,可处理超过 140 种语言。
- 32K 个令牌上下文:用于分析数据和处理处理任务的大量输入上下文。
试用 Gemma 3n 在 Kaggle 上获取 在 Hugging Face 上获取
与其他 Gemma 模型一样,Gemma 3n 提供开放式权重,并已获许可进行负责任的商业用途,您可以在自己的项目和应用中对其进行调优和部署。
模型参数和有效参数
Gemma 3n 模型的列表中会显示参数数量(例如 E2B 和 E4B),该数量低于模型中包含的参数总数。E 前缀表示这些模型可以使用更少的有效参数运行。为了实现这种减少参数操作的功能,Gemma 3n 模型内置了灵活的参数技术,以帮助它们在资源较少的设备上高效运行。
Gemma 3n 模型中的参数分为 4 个主要组:文本、视觉、音频和每层嵌入 (PLE) 参数。标准执行 E2B 模型时,执行模型时会加载超过 50 亿个参数。不过,通过使用参数跳过和 PLE 缓存技术,此模型的有效内存负载仅略低于 20 亿 (19.1 亿) 个参数,如图 1 所示。
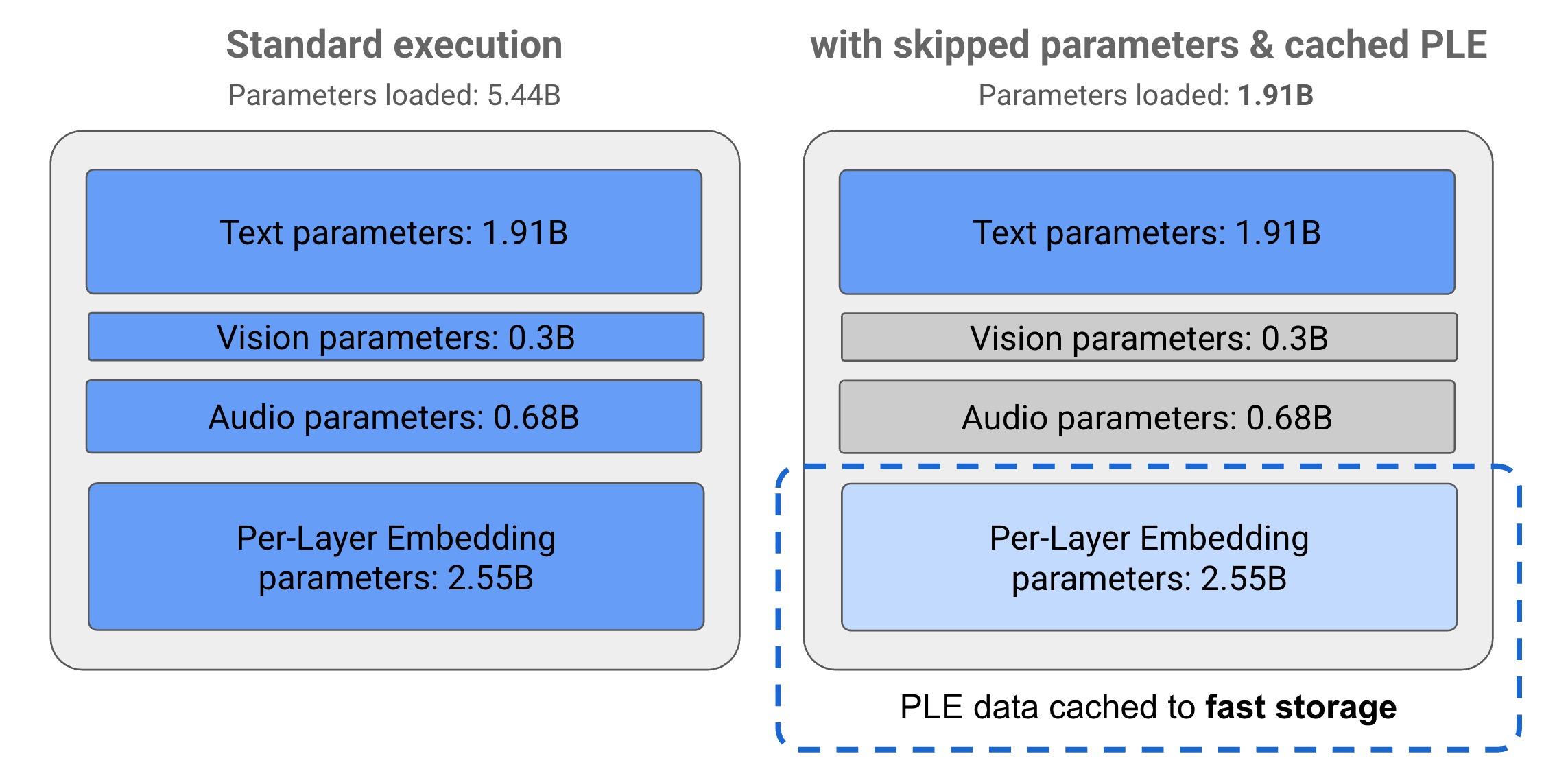
图 1. 在标准执行中运行的 Gemma 3n E2B 模型参数,与使用 PLE 缓存和参数跳过技术有效降低的参数加载量。
借助这些参数分流和选择性激活技术,您可以使用一组非常精简的参数运行模型,也可以激活其他参数来处理其他数据类型(例如视觉和音频)。借助这些功能,您可以根据设备功能或任务要求来增强或降低模型功能。以下部分详细介绍了 Gemma 3n 模型中可用的参数高效技术。
PLE 缓存
Gemma 3n 模型包含每层嵌入 (PLE) 参数,这些参数在模型执行期间用于创建数据,以提升每个模型层的性能。PLE 数据可以在模型的操作内存之外单独生成,缓存到快速存储空间,然后在每个层运行时添加到模型推理流程中。这种方法可将 PLE 参数保留在模型内存空间之外,从而减少资源消耗,同时仍能提高模型响应质量。
MatFormer 架构
Gemma 3n 模型使用 Matryoshka Transformer 或 MatFormer 模型架构,该架构在单个较大的模型中包含嵌套的较小模型。嵌套的子模型可用于推理,而无需在响应请求时激活封闭模型的参数。这种仅在 MatFormer 模型中运行较小核心模型的功能可以降低模型的计算开销、响应时间和能耗。对于 Gemma 3n,E4B 模型包含 E2B 模型的参数。借助这种架构,您还可以选择参数,并组装大小介于 2B 和 4B 之间的中间大小的模型。如需详细了解此方法,请参阅 MatFormer 研究论文。请尝试使用 MatFormer Lab 指南中的 MatFormer 技术来缩减 Gemma 3n 模型的大小。
条件式参数加载
与 PLE 参数类似,您可以在 Gemma 3n 模型中跳过将某些参数(例如音频或视觉参数)加载到内存中的操作,以减少内存负载。如果设备具有所需资源,则可以在运行时动态加载这些参数。总体而言,参数跳过可以进一步减少 Gemma 3n 模型所需的操作内存,从而支持在更多类型的设备上执行,并让开发者能够提高资源效率,以便处理要求较低的任务。
准备好开始构建了吗?
开始使用 Gemma 模型!