
Gemma 3n là một mô hình AI tạo sinh được tối ưu hoá để sử dụng trong các thiết bị hằng ngày, chẳng hạn như điện thoại, máy tính xách tay và máy tính bảng. Mô hình này bao gồm các điểm cải tiến trong quá trình xử lý thông số hiệu quả, bao gồm cả lưu thông số Lồng ghép theo lớp (PLE) vào bộ nhớ đệm và cấu trúc mô hình MatFormer giúp linh hoạt giảm các yêu cầu về điện toán và bộ nhớ. Các mô hình này có tính năng xử lý đầu vào âm thanh, cũng như dữ liệu văn bản và hình ảnh.
Gemma 3n có các tính năng chính sau:
- Đầu vào âm thanh: Xử lý dữ liệu âm thanh để nhận dạng lời nói, dịch và phân tích dữ liệu âm thanh. Tìm hiểu thêm
- Nhập dữ liệu bằng hình ảnh và văn bản: Các chức năng đa phương thức cho phép bạn xử lý hình ảnh, âm thanh và văn bản để giúp bạn hiểu và phân tích thế giới xung quanh. Tìm hiểu thêm
- Mã hoá hình ảnh: Bộ mã hoá MobileNet-V5 hiệu suất cao cải thiện đáng kể tốc độ và độ chính xác của việc xử lý dữ liệu hình ảnh. Tìm hiểu thêm
- Lưu PLE vào bộ nhớ đệm: Các tham số Nhúng theo lớp (PLE) có trong các mô hình này có thể được lưu vào bộ nhớ đệm để lưu trữ cục bộ nhanh nhằm giảm chi phí chạy bộ nhớ mô hình. Tìm hiểu thêm
- Cấu trúc MatFormer: Cấu trúc Matryoshka Transformer cho phép kích hoạt có chọn lọc các tham số của mô hình theo yêu cầu để giảm chi phí điện toán và thời gian phản hồi. Tìm hiểu thêm
- Tải tham số có điều kiện: Bỏ qua việc tải các tham số hình ảnh và âm thanh trong mô hình để giảm tổng số tham số được tải và tiết kiệm tài nguyên bộ nhớ. Tìm hiểu thêm
- Hỗ trợ nhiều ngôn ngữ: Có nhiều khả năng ngôn ngữ, được huấn luyện bằng hơn 140 ngôn ngữ.
- Ngữ cảnh mã thông báo 32K: Ngữ cảnh đầu vào đáng kể để phân tích dữ liệu và xử lý các tác vụ xử lý.
Dùng thử Gemma 3n Tải trên Kaggle Tải trên Hugging Face
Giống như các mô hình Gemma khác, Gemma 3n được cung cấp trọng số mở và được cấp phép cho mục đích sử dụng thương mại có trách nhiệm, cho phép bạn điều chỉnh và triển khai mô hình này trong các dự án và ứng dụng của riêng mình.
Tham số mô hình và tham số hiệu quả
Các mô hình Gemma 3n được liệt kê cùng với số lượng tham số, chẳng hạn như E2B và E4B, thấp hơn tổng số tham số có trong mô hình. Tiền tố E cho biết các mô hình này có thể hoạt động với một tập hợp tham số Hiệu quả bị giảm. Bạn có thể đạt được hoạt động giảm tham số này bằng cách sử dụng công nghệ tham số linh hoạt được tích hợp vào các mô hình Gemma 3n để giúp các mô hình này chạy hiệu quả trên các thiết bị có tài nguyên thấp hơn.
Các tham số trong mô hình Gemma 3n được chia thành 4 nhóm chính: văn bản, hình ảnh, âm thanh và tham số nhúng theo lớp (PLE). Với phương thức thực thi tiêu chuẩn của mô hình E2B, hơn 5 tỷ tham số sẽ được tải khi thực thi mô hình. Tuy nhiên, bằng cách sử dụng kỹ thuật bỏ qua tham số và lưu vào bộ nhớ đệm PLE, mô hình này có thể hoạt động với mức tải bộ nhớ hiệu quả chỉ dưới 2 tỷ (1,91 tỷ) tham số, như minh hoạ trong Hình 1.
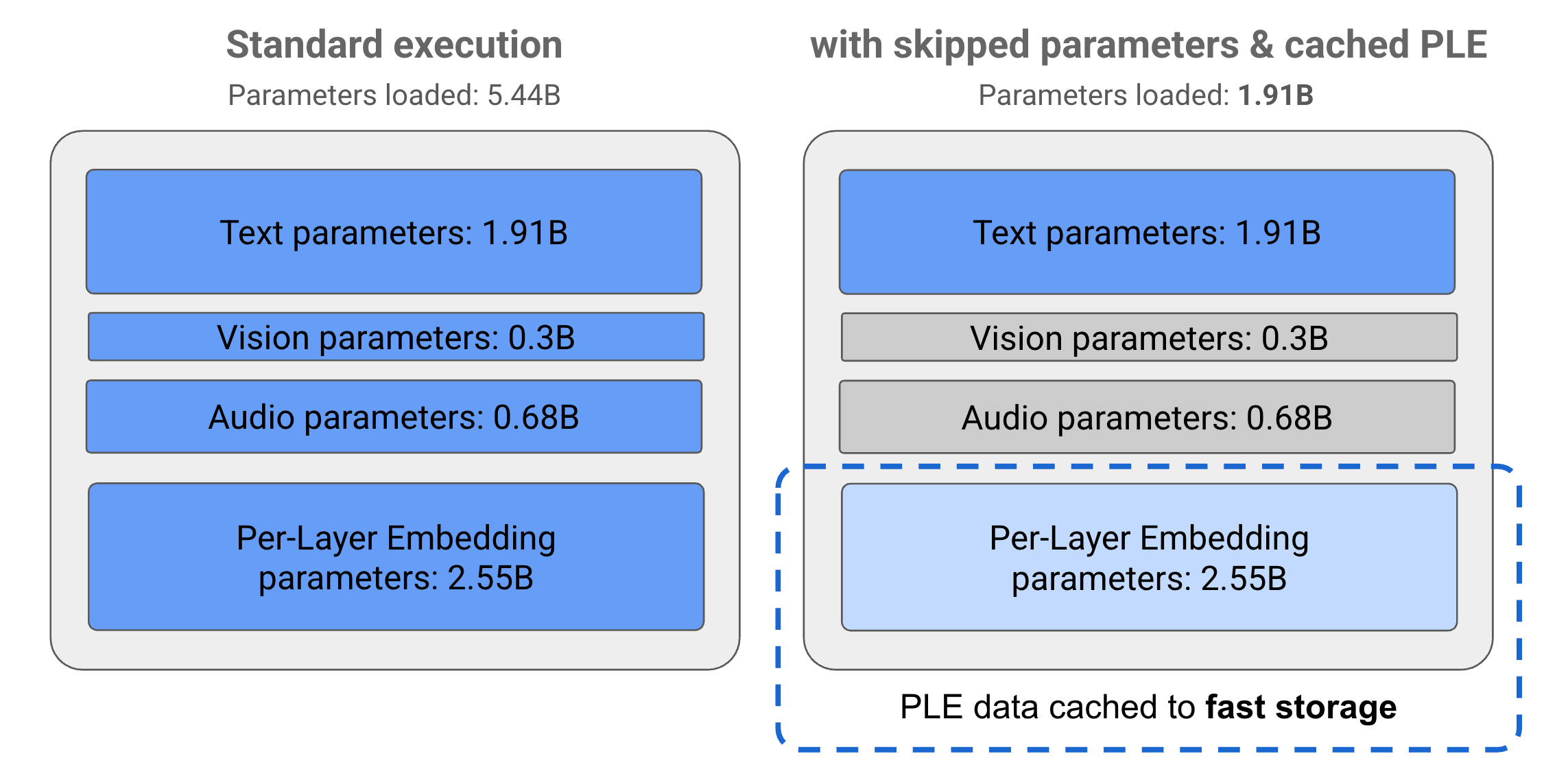
Hình 1. Các tham số mô hình Gemma 3n E2B chạy trong quá trình thực thi tiêu chuẩn so với tải tham số thấp hơn một cách hiệu quả bằng cách sử dụng kỹ thuật lưu vào bộ nhớ đệm PLE và bỏ qua tham số.
Bằng cách sử dụng các kỹ thuật giảm tải tham số và kích hoạt có chọn lọc này, bạn có thể chạy mô hình bằng một tập hợp tham số rất tinh giản hoặc kích hoạt các tham số bổ sung để xử lý các loại dữ liệu khác như hình ảnh và âm thanh. Các tính năng này cho phép bạn tăng cường chức năng của mô hình hoặc giảm chức năng dựa trên chức năng của thiết bị hoặc yêu cầu của tác vụ. Các phần sau đây giải thích thêm về các kỹ thuật hiệu quả về tham số có trong mô hình Gemma 3n.
Lưu PLE vào bộ nhớ đệm
Mô hình Gemma 3n bao gồm các thông số Nhúng theo lớp (PLE) được sử dụng trong quá trình thực thi mô hình để tạo dữ liệu giúp nâng cao hiệu suất của từng lớp mô hình. Dữ liệu PLE có thể được tạo riêng biệt, bên ngoài bộ nhớ hoạt động của mô hình, lưu vào bộ nhớ đệm để lưu trữ nhanh, sau đó thêm vào quy trình suy luận mô hình khi mỗi lớp chạy. Phương pháp này cho phép các tham số PLE được giữ ra khỏi không gian bộ nhớ mô hình, giảm mức tiêu thụ tài nguyên trong khi vẫn cải thiện chất lượng phản hồi của mô hình.
Cấu trúc MatFormer
Các mô hình Gemma 3n sử dụng cấu trúc mô hình Matryoshka Transformer hoặc MatFormer chứa các mô hình lồng nhau, nhỏ hơn trong một mô hình lớn hơn. Bạn có thể sử dụng các mô hình con được lồng ghép để suy luận mà không cần kích hoạt các tham số của mô hình bao bọc khi phản hồi các yêu cầu. Khả năng chỉ chạy các mô hình nhỏ hơn, cốt lõi trong mô hình MatFormer có thể làm giảm chi phí điện toán, thời gian phản hồi và mức tiêu thụ năng lượng cho mô hình. Trong trường hợp Gemma 3n, mô hình E4B chứa các thông số của mô hình E2B. Cấu trúc này cũng cho phép bạn chọn các tham số và tập hợp các mô hình ở kích thước trung gian từ 2B đến 4B. Để biết thêm thông tin chi tiết về phương pháp này, hãy xem bài báo nghiên cứu về MatFormer. Hãy thử sử dụng các kỹ thuật MatFormer để giảm kích thước của mô hình Gemma 3n bằng hướng dẫn về MatFormer Lab.
Tải tham số có điều kiện
Tương tự như các tham số PLE, bạn có thể bỏ qua việc tải một số tham số vào bộ nhớ, chẳng hạn như tham số âm thanh hoặc hình ảnh, trong mô hình Gemma 3n để giảm tải bộ nhớ. Các tham số này có thể được tải động trong thời gian chạy nếu thiết bị có tài nguyên cần thiết. Nhìn chung, tính năng bỏ qua tham số có thể làm giảm thêm bộ nhớ hoạt động cần thiết cho mô hình Gemma 3n, cho phép thực thi trên nhiều thiết bị hơn và cho phép nhà phát triển tăng hiệu quả sử dụng tài nguyên cho các tác vụ ít đòi hỏi hơn.
Bạn đã sẵn sàng bắt đầu xây dựng chưa?
Bắt đầu sử dụng các mô hình Gemma!