
O Gemma 3n é um modelo de IA generativa otimizado para uso em dispositivos do dia a dia, como smartphones, laptops e tablets. Esse modelo inclui inovações no processamento eficiente de parâmetros, incluindo o armazenamento em cache de parâmetros por camada (PLE) e uma arquitetura de modelo MatFormer que oferece a flexibilidade para reduzir os requisitos de computação e memória. Esses modelos oferecem processamento de entrada de áudio, além de dados de texto e visuais.
O Gemma 3n inclui os seguintes recursos principais:
- Entrada de áudio: processe dados de som para reconhecimento de fala, tradução e análise de dados de áudio. Saiba mais
- Entrada visual e de texto: os recursos multimodais permitem processar visão, som e texto para ajudar a entender e analisar o mundo ao seu redor. Saiba mais
- Codificador de visão:o codificador MobileNet-V5 de alto desempenho melhora significativamente a velocidade e a precisão do processamento de dados visuais. Saiba mais
- Armazenamento em cache de PLE: os parâmetros de PLE contidos nesses modelos podem ser armazenados em cache no armazenamento local rápido para reduzir os custos de execução de memória do modelo. Saiba mais
- Arquitetura MatFormer:a arquitetura Matryoshka Transformer permite a ativação seletiva dos parâmetros dos modelos por solicitação para reduzir o custo de computação e os tempos de resposta. Saiba mais
- Carregamento de parâmetro condicional:pule o carregamento de parâmetros de visão e áudio no modelo para reduzir o número total de parâmetros carregados e economizar recursos de memória. Saiba mais
- Suporte a vários idiomas: recursos linguísticos amplos, treinados em mais de 140 idiomas.
- Contexto de token de 32K: contexto de entrada substancial para analisar dados e processar tarefas.
Teste o Gemma 3n Acesse no Kaggle Acesse no Hugging Face
Assim como outros modelos do Gemma, o Gemma 3n é fornecido com pesos abertos e licenciado para uso comercial responsável, permitindo que você o ajuste e implante nos seus próprios projetos e aplicativos.
Parâmetros do modelo e parâmetros efetivos
Os modelos Gemma 3n são listados com contagens de parâmetros, como E2B e
E4B, que são menores do que o número total de parâmetros contidos nos
modelos. O prefixo E indica que esses modelos podem operar com um conjunto reduzido
de parâmetros eficazes. Essa operação de parâmetro reduzido pode ser alcançada usando
a tecnologia de parâmetro flexível integrada aos modelos Gemma 3n para ajudar a executar
com eficiência em dispositivos com menos recursos.
Os parâmetros nos modelos Gemma 3n são divididos em quatro grupos principais: parâmetros de texto, visual, áudio e incorporação por camada (PLE). Com a execução padrão do modelo E2B, mais de 5 bilhões de parâmetros são carregados ao executar o modelo. No entanto, usando técnicas de salto de parâmetro e armazenamento em cache de PLE, esse modelo pode ser operado com uma carga de memória eficaz de pouco menos de 2 bilhões (1,91B) de parâmetros, conforme ilustrado na Figura 1.
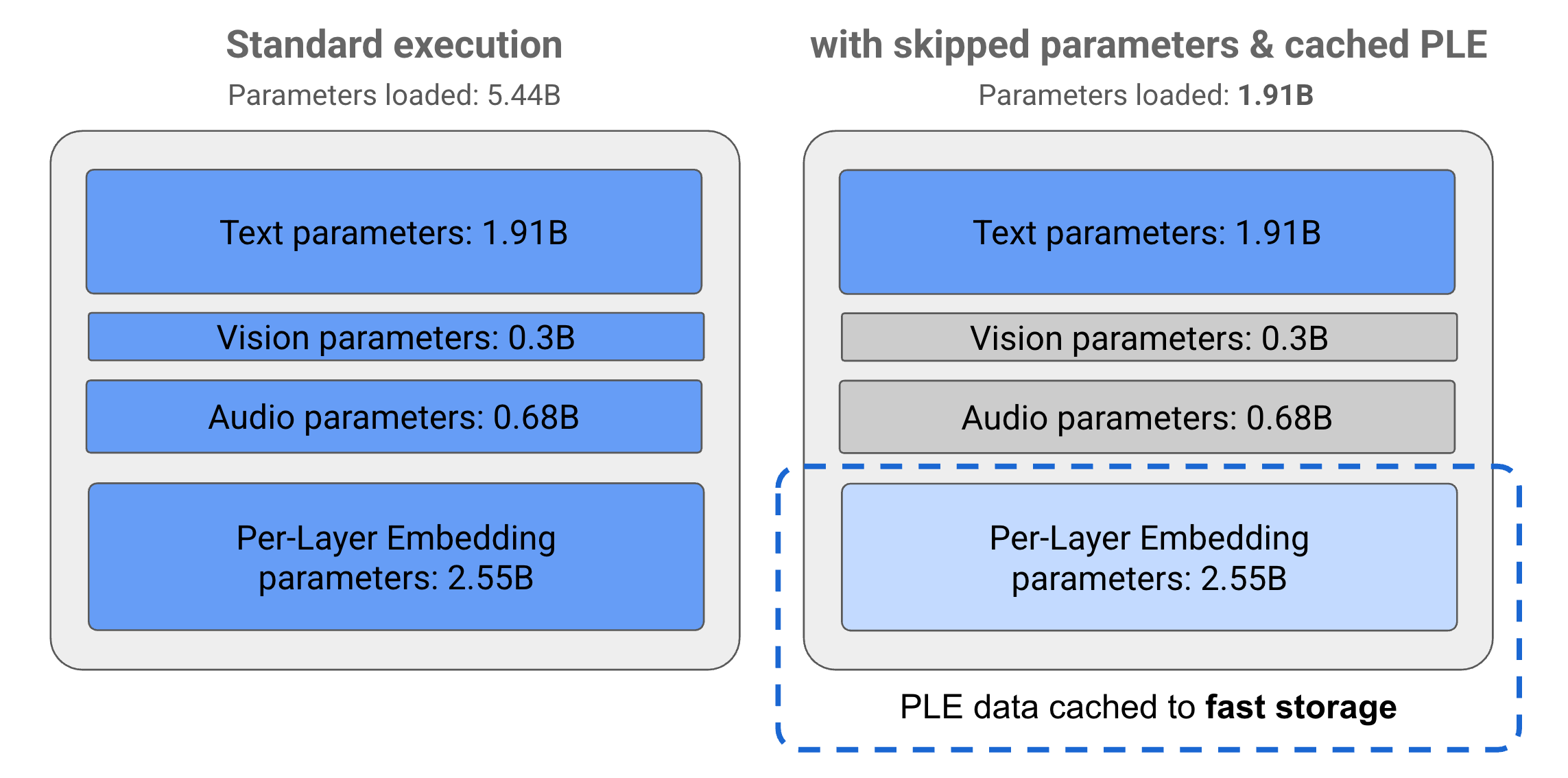
Figura 1. Parâmetros do modelo Gemma 3n E2B em execução na execução padrão comparado a uma carga de parâmetros efetivamente menor usando técnicas de salto e armazenamento em cache de PLE.
Usando essas técnicas de transferência de parâmetros e ativação seletiva, é possível executar o modelo com um conjunto de parâmetros muito enxuto ou ativar outros para processar outros tipos de dados, como visuais e de áudio. Esses recursos permitem aumentar ou diminuir a funcionalidade do modelo com base nos recursos do dispositivo ou nos requisitos da tarefa. As seções a seguir explicam mais sobre as técnicas de eficiência de parâmetro disponíveis nos modelos Gemma 3n.
Armazenamento em cache do PLE
Os modelos Gemma 3n incluem parâmetros de embeddings por camada (PLE, na sigla em inglês), que são usados durante a execução do modelo para criar dados que melhoram o desempenho de cada camada do modelo. Os dados de PLE podem ser gerados separadamente, fora da memória operacional do modelo, armazenados em cache para armazenamento rápido e, em seguida, adicionados ao processo de inferência do modelo à medida que cada camada é executada. Essa abordagem permite que os parâmetros do PLE sejam mantidos fora do espaço de memória do modelo, reduzindo o consumo de recursos e melhorando a qualidade da resposta do modelo.
Arquitetura do MatFormer
Os modelos Gemma 3n usam uma arquitetura de modelo Matryoshka Transformer ou MatFormer que contém modelos menores aninhados em um único modelo maior. Os submodelos aninhados podem ser usados para inferências sem ativar os parâmetros dos modelos que os contêm ao responder às solicitações. Essa capacidade de executar apenas os modelos principais menores em um modelo do MatFormer pode reduzir o custo de computação, o tempo de resposta e a pegada energética do modelo. No caso da Gemma 3n, o modelo E4B contém os parâmetros do modelo E2B. Essa arquitetura também permite selecionar parâmetros e montar modelos em tamanhos intermediários entre 2B e 4B. Para mais detalhes sobre essa abordagem, consulte o artigo de pesquisa do MatFormer (em inglês). Tente usar técnicas do MatFormer para reduzir o tamanho de um modelo Gemma 3n com o guia MatFormer Lab.
Carregamento de parâmetros condicionais
Assim como nos parâmetros de PLE, é possível pular o carregamento de alguns parâmetros na memória, como parâmetros de áudio ou visual, no modelo Gemma 3n para reduzir a carga de memória. Esses parâmetros podem ser carregados dinamicamente no momento da execução se o dispositivo tiver os recursos necessários. No geral, o salto de parâmetro pode reduzir ainda mais a memória operacional necessária para um modelo Gemma 3n, permitindo a execução em uma gama mais ampla de dispositivos e permitindo que os desenvolvedores aumentem a eficiência dos recursos para tarefas menos exigentes.
Tudo pronto para começar a criar?
Comece a usar
os modelos do Gemma.