
Gemma 3n to generatywny model AI zoptymalizowany pod kątem korzystania na urządzeniach codziennego użytku, takich jak telefony, laptopy i tablety. Model ten zawiera innowacje w zakresie przetwarzania z wydajnym wykorzystaniem parametrów, w tym buforowania parametrów PLE (Per-Layer Embedding) i architektury modelu MatFormer, która zapewnia elastyczność w zakresie zmniejszania wymagań dotyczących pamięci i obliczeń. Modele te obsługują dane wejściowe audio, a także dane tekstowe i wizualne.
Gemma 3n zawiera te najważniejsze funkcje:
- Wejście audio: przetwarzanie danych dźwiękowych na potrzeby rozpoznawania mowy, tłumaczenia i analizy danych audio. Więcej informacji
- Wizualne i tekstowe dane wejściowe: funkcje multimodalne umożliwiają przetwarzanie obrazu, dźwięku i tekstu, aby ułatwić zrozumienie i analizowanie otaczającego Cię świata. Więcej informacji
- Koderek widzenia: wydajny koder MobileNet-V5 znacznie zwiększa szybkość i dokładność przetwarzania danych wizualnych. Więcej informacji
- Pamięć podręczna PLE: parametry PLE zawarte w tych modelach można zapisać w pamięci podręcznej, aby zmniejszyć koszty związane z wykorzystywaniem pamięci przez model. Więcej informacji
- Architektura MatFormer: architektura Matryoshka Transformer umożliwia selektywną aktywację parametrów modeli na podstawie żądania, co pozwala zmniejszyć koszt obliczeń i czas odpowiedzi. Więcej informacji
- Warunkowe wczytywanie parametrów: pomiń wczytywanie parametrów wizualnych i dźwiękowych w modelu, aby zmniejszyć łączną liczbę wczytywanych parametrów i oszczędzać zasoby pamięci. Więcej informacji
- Obsługa wielu języków: szerokie możliwości językowe, wytrenowane w ponad 140 językach.
- Kontekst 32 tys. tokenów: obszerny kontekst wejściowy do analizowania danych i wykonywania zadań przetwarzania.
Wypróbuj Gemma 3n Pobierz na Kaggle Pobierz na Hugging Face
Podobnie jak inne modele Gemma, Gemma 3n jest dostarczana z otwartymi wagami i licencją na odpowiedzialne wykorzystanie komercyjne, co pozwala na jej dostosowanie i wdrożenie w własnych projektach i aplikacjach.
Parametry modelu i parametry skuteczności
Modele Gemma 3n są wymienione z liczbą parametrów, np. E2B i E4B, która jest niższa od łącznej liczby parametrów zawartych w modelach. Współczynnik E wskazuje, że te modele mogą działać z obniżonym zestawem parametrów skuteczności. Zmniejszoną liczbę parametrów można uzyskać dzięki elastycznej technologii parametrów wbudowanej w modele Gemma 3n, która pozwala na wydajne działanie na urządzeniach o mniejszych zasobach.
Parametry w modelach Gemma 3n są podzielone na 4 główne grupy: tekst, obraz, dźwięk i parametry PLE (embedding na poszczególnych warstwach). Podczas standardowego wykonywania modelu E2B ładowanych jest ponad 5 mld parametrów. Jednak dzięki pomijaniu parametrów i technikom pamięci podręcznej PLE model może działać z efektywnym obciążeniem pamięci wynoszącym niecałe 2 mld (1,91 mln) parametrów, jak pokazano na rysunku 1.
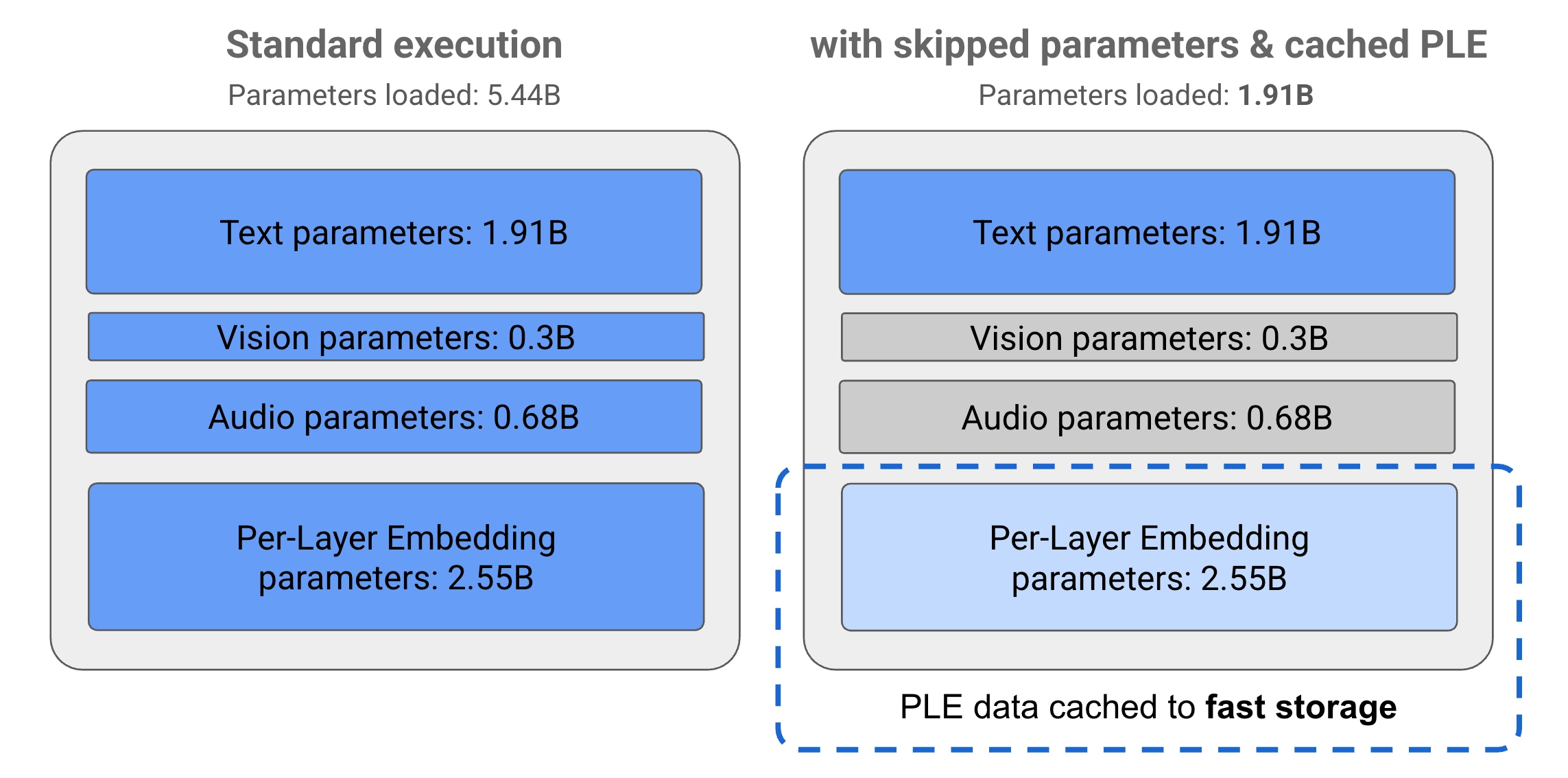
Rysunek 1. Parametry modelu Gemma 3n E2B podczas standardowego wykonywania w porównaniu z efektywnie niższym wczytywaniem parametrów przy użyciu technik PLE, takich jak buforowanie i pomijanie parametrów.
Dzięki tym technikom przenoszenia i selektywnej aktywacji parametrów możesz uruchomić model z bardzo skromnym zestawem parametrów lub aktywować dodatkowe parametry do obsługi innych typów danych, takich jak obraz i dźwięk. Te funkcje umożliwiają zwiększanie lub zmniejszanie funkcjonalności modelu w zależności od możliwości urządzenia lub wymagań związanych z zadaniem. W następnych sekcjach znajdziesz więcej informacji o technikach optymalizacji parametrów dostępnych w modelach Gemma 3n.
Buforowanie PLE
Modele Gemma 3n zawierają parametry PLE (embedding na poziomie warstwy), które są używane podczas wykonywania modelu do tworzenia danych, które zwiększają wydajność każdej warstwy modelu. Dane PLE można generować osobno, poza pamięcią operacyjną modelu, przechowywać w pamięci podręcznej w szybkiej pamięci, a następnie dodawać do procesu wnioskowania modelu podczas wykonywania poszczególnych warstw. Dzięki temu parametry PLE nie zajmują miejsca w pamięci modelu, co pozwala ograniczyć zużycie zasobów i jednocześnie poprawić jakość odpowiedzi modelu.
Architektura MatFormer
Modele Gemma 3n korzystają z architektury modelu Matryoshka Transformer lub MatFormer, która zawiera zagnieżdżone mniejsze modele w ramach jednego większego modelu. Zagnieżdżone podmodele można używać do wnioskowania bez aktywowania parametrów otaczających je modeli podczas odpowiadania na żądania. Ta możliwość uruchamiania w ramach modelu MatFormer tylko mniejszych, podstawowych modeli może zmniejszyć koszty obliczeniowe, czas reakcji i ślad węglowy modelu. W przypadku Gemma 3n model E4B zawiera parametry modelu E2B. Ta architektura umożliwia też wybór parametrów i złożenie modeli o rozmiarach pośrednich (2B–4B). Więcej informacji o tym podejściu znajdziesz w artykule MatFormer research paper (w języku angielskim). Aby zmniejszyć rozmiar modelu Gemma 3n, spróbuj użyć technik MatFormer. W tym celu skorzystaj z pomocy w MatFormer Lab.
Warunkowe wczytywanie parametrów
Podobnie jak w przypadku parametrów PLE, w modelu Gemma 3n możesz pominąć wczytywanie niektórych parametrów do pamięci, na przykład parametrów dźwięku lub wizualnych, aby zmniejszyć obciążenie pamięci. Te parametry mogą być wczytywane dynamicznie w czasie wykonywania, jeśli urządzenie ma wymagane zasoby. Ogólnie pomijanie parametrów może jeszcze bardziej zmniejszyć wymaganą ilość pamięci operacyjnej w przypadku modelu Gemma 3n, umożliwiając wykonywanie kodu na szerszym zakresie urządzeń i zwiększając wydajność wykorzystania zasobów w przypadku mniej wymagających zadań.
Gotowy do tworzenia?
Zacznij korzystać z modeli Gemma.