
Gemma 3n은 휴대전화, 노트북, 태블릿과 같은 일상적인 기기에서 사용하기에 최적화된 생성형 AI 모델입니다. 이 모델에는 레이어별 임베딩 (PLE) 매개변수 캐싱, 계산 및 메모리 요구사항을 줄이는 유연성을 제공하는 MatFormer 모델 아키텍처를 비롯한 매개변수 효율적인 처리의 혁신이 포함되어 있습니다. 이러한 모델은 텍스트 및 시각적 데이터뿐만 아니라 오디오 입력 처리 기능도 제공합니다.
Gemma 3n에는 다음과 같은 주요 기능이 포함되어 있습니다.
- 오디오 입력: 음성 인식, 번역, 오디오 데이터 분석을 위해 소리 데이터를 처리합니다. 자세히 알아보기
- 시각 및 텍스트 입력: 멀티모달 기능을 사용하면 시각, 소리, 텍스트를 처리하여 주변 환경을 이해하고 분석할 수 있습니다. 자세히 알아보기
- 비전 인코더: 고성능 MobileNet-V5 인코더는 시각적 데이터 처리 속도와 정확성을 크게 개선합니다. 자세히 알아보기
- PLE 캐싱: 이러한 모델에 포함된 레이어별 임베딩 (PLE) 매개변수를 빠른 로컬 스토리지에 캐시하여 모델 메모리 실행 비용을 줄일 수 있습니다. 자세히 알아보기
- MatFormer 아키텍처: Matryoshka Transformer 아키텍처를 사용하면 요청별로 모델 매개변수를 선택적으로 활성화하여 계산 비용과 응답 시간을 줄일 수 있습니다. 자세히 알아보기
- 조건부 매개변수 로드: 모델에서 비전 및 오디오 매개변수 로드를 우회하여 로드된 총 매개변수 수를 줄이고 메모리 리소스를 절약합니다. 자세히 알아보기
- 다양한 언어 지원: 140개가 넘는 언어로 학습된 광범위한 언어 기능
- 32,000개 토큰 컨텍스트: 데이터를 분석하고 처리 태스크를 처리하기 위한 상당한 양의 입력 컨텍스트입니다.
Gemma 3n 사용해 보기 Kaggle에서 사용하기 Hugging Face에서 사용하기
다른 Gemma 모델과 마찬가지로 Gemma 3n은 공개 가중치와 함께 제공되며 책임감 있는 상업적 사용에 대한 라이선스가 부여되어 있으므로 자체 프로젝트 및 애플리케이션에서 조정하고 배포할 수 있습니다.
모델 매개변수 및 유효 매개변수
Gemma 3n 모델은 모델에 포함된 총 파라미터 수보다 작은 E2B 및 E4B과 같은 매개변수 개수와 함께 표시됩니다. E 접두사는 이러한 모델이 감소된 효과적인 매개변수 집합으로 작동할 수 있음을 나타냅니다. Gemma 3n 모델에 내장된 유연한 매개변수 기술을 사용하여 이러한 감소된 매개변수 작업을 실행할 수 있으므로 리소스가 부족한 기기에서 효율적으로 실행할 수 있습니다.
Gemma 3n 모델의 매개변수는 텍스트, 시각적, 오디오, 레이어별 임베딩 (PLE) 매개변수라는 4가지 기본 그룹으로 나뉩니다. E2B 모델을 표준적으로 실행하면 모델을 실행할 때 50억 개가 넘는 매개변수가 로드됩니다. 그러나 매개변수 건너뛰기 및 PLE 캐싱 기법을 사용하면 이 모델을 그림 1과 같이 20억 (19억 1,000만) 미만의 매개변수로 효과적으로 메모리 로드할 수 있습니다.
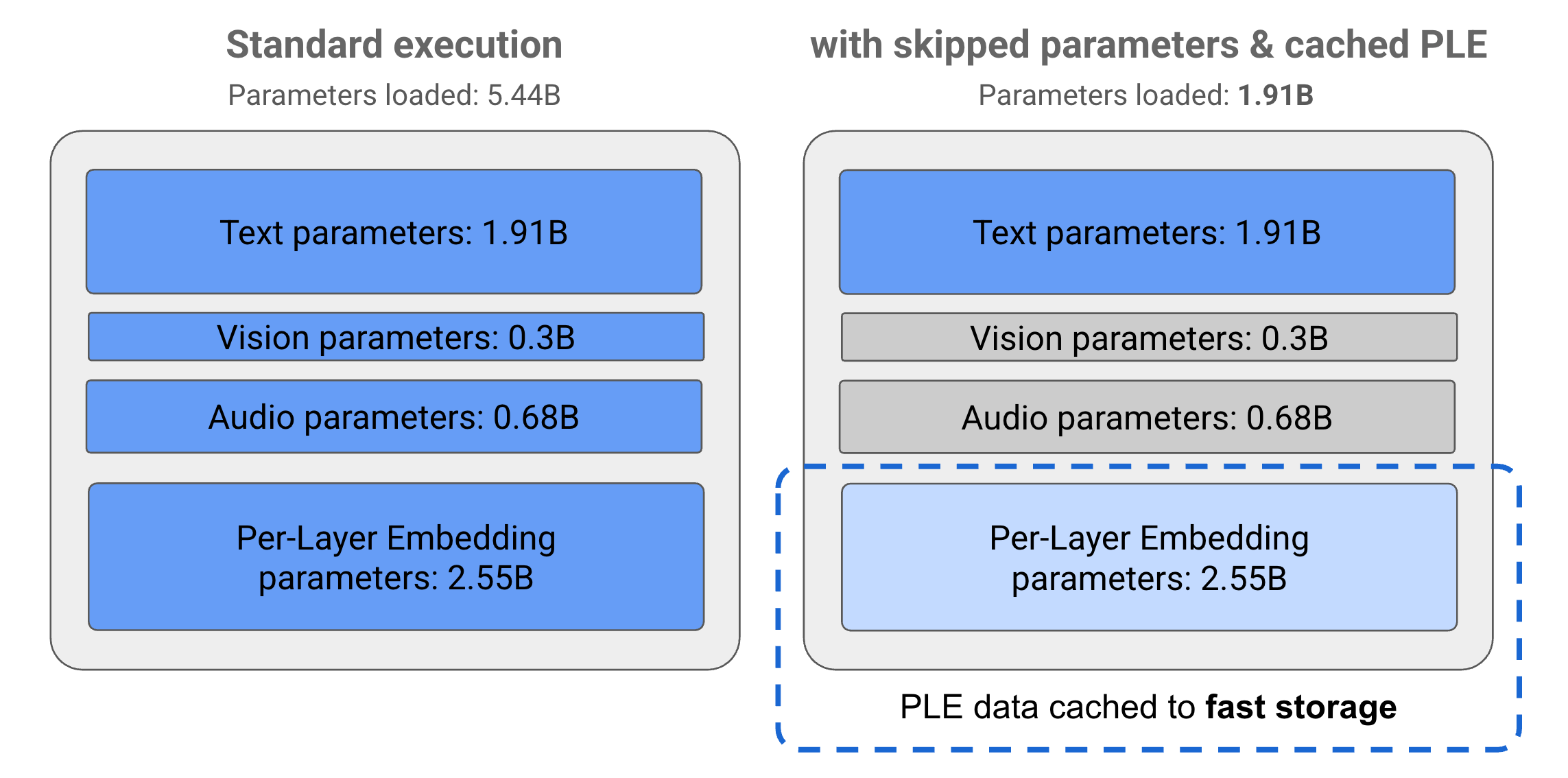
그림 1. 표준 실행에서 실행되는 Gemma 3n E2B 모델 매개변수와 PLE 캐싱 및 매개변수 건너뛰기 기법을 사용하여 효과적으로 낮은 매개변수 로드를 비교합니다.
이러한 매개변수 오프로드 및 선택적 활성화 기법을 사용하면 매우 간소한 매개변수 세트로 모델을 실행하거나 추가 매개변수를 활성화하여 시각적 데이터, 오디오와 같은 다른 데이터 유형을 처리할 수 있습니다. 이러한 기능을 사용하면 기기 기능 또는 작업 요구사항에 따라 모델 기능을 늘리거나 줄일 수 있습니다. 다음 섹션에서는 Gemma 3n 모델에서 사용할 수 있는 매개변수 효율적인 기술에 대해 자세히 설명합니다.
PLE 캐싱
Gemma 3n 모델에는 모델 실행 중에 각 모델 레이어의 성능을 개선하는 데이터를 만드는 데 사용되는 레이어별 임베딩 (PLE) 매개변수가 포함됩니다. PLE 데이터는 모델의 운영 메모리 외부에서 별도로 생성되고 빠른 저장소에 캐시된 후 각 레이어가 실행될 때 모델 추론 프로세스에 추가될 수 있습니다. 이 접근 방식을 사용하면 PLE 매개변수를 모델 메모리 공간 외부에 유지할 수 있으므로 리소스 소비를 줄이면서도 모델 응답 품질을 개선할 수 있습니다.
MatFormer 아키텍처
Gemma 3n 모델은 단일의 더 큰 모델 내에 중첩된 더 작은 모델이 포함된 Matryoshka Transformer 또는 MatFormer 모델 아키텍처를 사용합니다. 중첩된 하위 모델은 요청에 응답할 때 포함 모델의 매개변수를 활성화하지 않고도 추론에 사용할 수 있습니다. MatFormer 모델 내에서 더 작은 핵심 모델만 실행할 수 있으므로 모델의 컴퓨팅 비용, 응답 시간, 에너지 사용량을 줄일 수 있습니다. Gemma 3n의 경우 E4B 모델에 E2B 모델의 매개변수가 포함됩니다. 또한 이 아키텍처를 사용하면 2B와 4B 사이의 중간 크기로 파라미터를 선택하고 모델을 조합할 수 있습니다. 이 접근 방식에 관한 자세한 내용은 MatFormer 연구 논문을 참고하세요. MatFormer 실험실 가이드에 따라 MatFormer 기법을 사용하여 Gemma 3n 모델의 크기를 줄여 보세요.
조건부 매개변수 로드
PLE 매개변수와 마찬가지로 Gemma 3n 모델에서 오디오 또는 시각적 매개변수와 같은 일부 매개변수를 메모리에 로드하는 작업을 건너뛰어 메모리 부하를 줄일 수 있습니다. 이러한 매개변수는 기기에 필요한 리소스가 있는 경우 런타임에 동적으로 로드될 수 있습니다. 전반적으로 파라미터 건너뛰기를 사용하면 Gemma 3n 모델에 필요한 운영 메모리를 더욱 줄일 수 있으므로 더 다양한 기기에서 실행할 수 있고 개발자는 덜 까다로운 작업에 리소스 효율성을 높일 수 있습니다.
빌드 준비가 되셨나요?
Gemma 모델로 시작해 보세요.