
Gemma 3n は、スマートフォン、ノートパソコン、タブレットなどの日常的なデバイスでの使用向けに最適化された生成 AI モデルです。このモデルには、パラメータ効率的な処理の革新が含まれています。これには、Per-Layer Embedding(PLE)パラメータ キャッシュや、コンピューティングとメモリ要件を柔軟に削減できる MatFormer モデル アーキテクチャが含まれます。これらのモデルは、音声入力の処理、テキストデータ、画像データを特徴としています。
Gemma 3n の主な機能は次のとおりです。
- 音声入力: 音声認識、翻訳、音声データ分析のために音声データを処理します。詳細
- 画像とテキストの入力: マルチモーダル機能により、ビジョン、音声、テキストを処理して、周囲の状況を理解して分析できます。詳細
- ビジョン エンコーダ: 高性能の MobileNet-V5 エンコーダにより、画像データの処理速度と精度が大幅に向上します。詳細
- PLE キャッシュ保存: これらのモデルに含まれる Per-Layer Embedding(PLE)パラメータを高速なローカル ストレージにキャッシュに保存することで、モデルのメモリ実行コストを削減できます。詳細
- MatFormer アーキテクチャ: Matryoshka Transformer アーキテクチャでは、リクエストごとにモデル パラメータを個別に有効にすることで、コンピューティング費用とレスポンス時間を削減できます。詳細
- 条件付きパラメータの読み込み: モデル内のビジョン パラメータと音声パラメータの読み込みをバイパスして、読み込まれるパラメータの合計数を減らし、メモリ リソースを節約します。詳細
- 幅広い言語サポート: 140 を超える言語でトレーニングされた幅広い言語機能。
- 32,000 トークンのコンテキスト: データの分析と処理タスクの処理に必要な大量の入力コンテキスト。
Gemma 3n を試す Kaggle で入手する Hugging Face で入手する
他の Gemma モデルと同様に、Gemma 3n はオープン重み付きで提供され、責任ある商用利用が許可されています。これにより、独自のプロジェクトやアプリケーションにチューニングしてデプロイできます。
モデル パラメータと有効なパラメータ
Gemma 3n モデルは、モデルに含まれるパラメータの合計数よりも少ないパラメータ数(E2B や E4B など)とともに一覧表示されます。接頭辞 E は、これらのモデルが有効なパラメータのセットが少なくても動作できることを示します。このパラメータ操作の削減は、Gemma 3n モデルに組み込まれた柔軟なパラメータ技術を使用して実現できます。これにより、リソースの少ないデバイスで効率的に実行できます。
Gemma 3n モデルのパラメータは、テキスト、ビジュアリゼーション、オーディオ、レイヤごとのエンベディング(PLE)パラメータの 4 つの主要なグループに分かれています。E2B モデルの標準実行では、モデルの実行時に 50 億を超えるパラメータが読み込まれます。ただし、パラメータ スキップと PLE キャッシュ テクニックを使用すると、このモデルは 20 億(19.1 億)パラメータ未満の実効メモリ負荷で動作できます(図 1 を参照)。
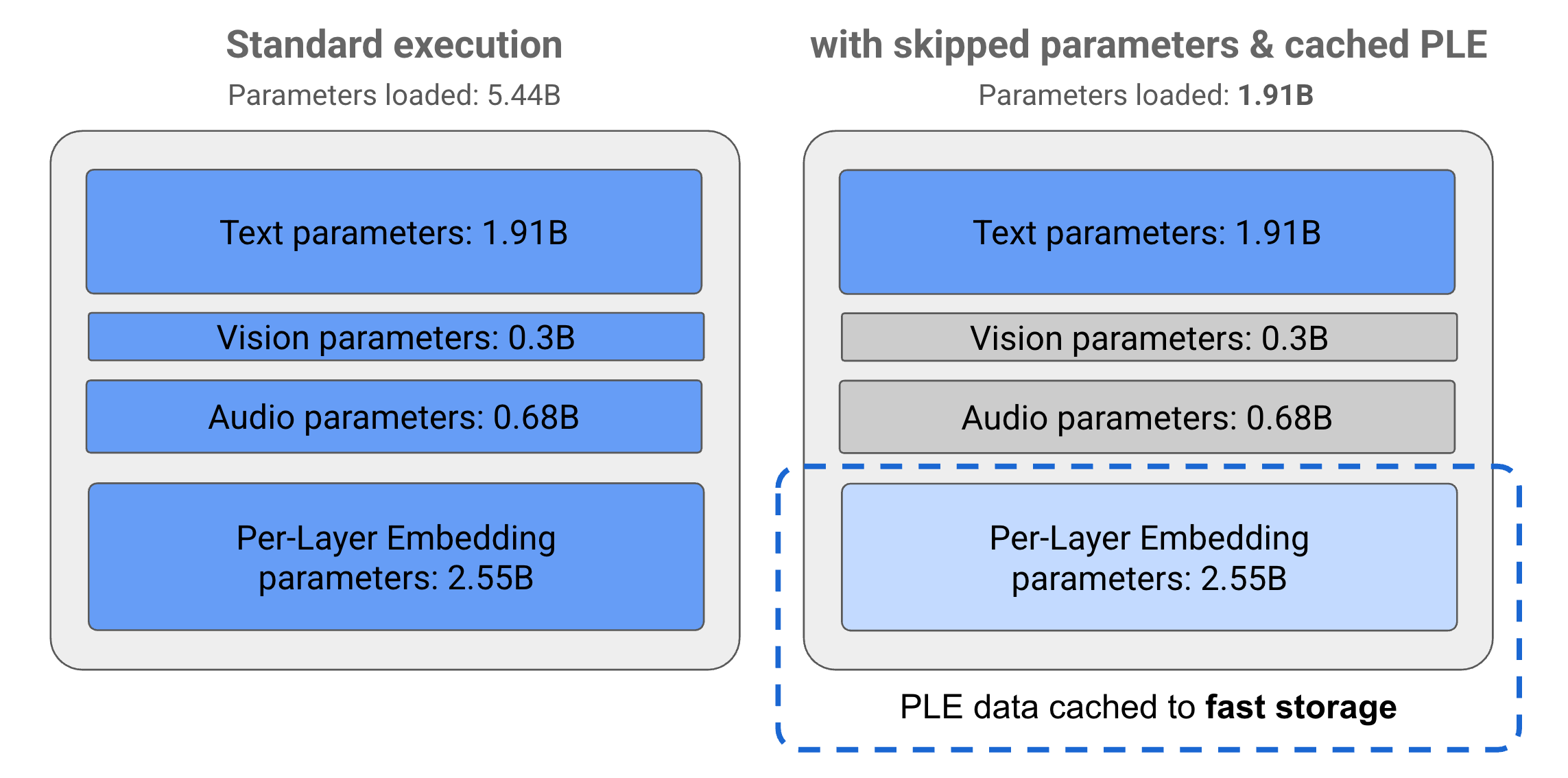
図 1. 標準実行で実行される Gemma 3n E2B モデル パラメータと、PLE キャッシュとパラメータ スキップ手法を使用してパラメータ負荷を効果的に低減した場合のパラメータ負荷。
これらのパラメータのオフロードと選択的な有効化手法を使用すると、非常にシンプルなパラメータセットでモデルを実行できます。また、追加のパラメータを有効にして、画像や音声などの他のデータ型を処理することもできます。これらの機能を使用すると、デバイスの機能やタスクの要件に基づいてモデルの機能を増強または減らすことができます。以降のセクションでは、Gemma 3n モデルで使用できるパラメータ効率的な手法について詳しく説明します。
PLE キャッシュ
Gemma 3n モデルには、モデルの実行中に各モデルレイヤのパフォーマンスを向上させるデータを作成するために使用されるレイヤごとのエンベディング(PLE)パラメータが含まれています。PLE データは、モデルのオペレーティング メモリ外で個別に生成し、高速ストレージにキャッシュに保存してから、各レイヤの実行時にモデル推論プロセスに追加できます。このアプローチにより、PLE パラメータをモデルのメモリ空間外に保持できるため、モデルのレスポンス品質を向上させながらリソース消費を削減できます。
MatFormer のアーキテクチャ
Gemma 3n モデルは、Matryoshka Transformer または MatFormer モデル アーキテクチャを使用します。このアーキテクチャでは、単一の大規模なモデル内にネストされた小規模なモデルが含まれています。ネストされたサブモデルは、リクエストに応答するときに、包含モデルのパラメータを有効にせずに推論に使用できます。MatFormer モデル内の小さなコアモデルのみを実行できるため、コンピューティング コスト、レスポンス時間、モデルのエネルギー フットプリントを削減できます。Gemma 3n の場合、E4B モデルには E2B モデルのパラメータが含まれています。このアーキテクチャでは、パラメータを選択して、2B と 4B の中間サイズのモデルをアセンブルすることもできます。このアプローチの詳細については、MatFormer に関する研究論文をご覧ください。MatFormer Lab ガイドで、MatFormer の手法を使用して Gemma 3n モデルのサイズを小さくしてみてください。
条件付きパラメータの読み込み
PLE パラメータと同様に、Gemma 3n モデルでは、音声パラメータや画像パラメータなど、一部のパラメータをメモリに読み込むことをスキップして、メモリ負荷を軽減できます。これらのパラメータは、デバイスに必要なリソースがある場合に、実行時に動的に読み込むことができます。全体として、パラメータ スキップにより Gemma 3n モデルに必要なオペレーティング メモリをさらに削減できるため、幅広いデバイスで実行できるようになり、デベロッパーは負荷の低いタスクでリソース効率を高めることができます。