
Gemma 3n è un modello di IA generativa ottimizzato per l'utilizzo su dispositivi di uso quotidiano, come smartphone, laptop e tablet. Questo modello include innovazioni nell'elaborazione con un numero ridotto di parametri, tra cui la memorizzazione nella cache dei parametri PLE (Per-Layer Embedding) e un'architettura del modello MatFormer che offre la flessibilità necessaria per ridurre i requisiti di calcolo e memoria. Questi modelli gestiscono l'input audio, nonché i dati di testo e visivi.
Gemma 3n include le seguenti funzionalità principali:
- Input audio: elabora i dati audio per il riconoscimento vocale, la traduzione e l'analisi dei dati audio. Scopri di più
- Input visivo e di testo: le funzionalità multimodali ti consentono di gestire visione, suono e testo per aiutarti a comprendere e analizzare il mondo che ti circonda. Scopri di più
- Codificatore di visione: l'encoder MobileNet-V5 ad alte prestazioni migliora notevolmente la velocità e l'accuratezza dell'elaborazione dei dati visivi. Scopri di più
- Memorizzazione nella cache PLE: i parametri di embedding per livello (PLE) contenuti in questi modelli possono essere memorizzati nella cache in uno spazio di archiviazione locale veloce per ridurre i costi di esecuzione della memoria del modello. Scopri di più
- Architettura MatFormer: l'architettura Matryoshka Transformer consente di attivare in modo selettivo i parametri dei modelli per richiesta per ridurre i costi di calcolo e i tempi di risposta. Scopri di più
- Caricamento dei parametri condizionali:ignora il caricamento dei parametri di visione e audio nel modello per ridurre il numero totale di parametri caricati e risparmiare risorse di memoria. Scopri di più
- Ampio supporto linguistico: ampie funzionalità linguistiche, addestrate in oltre 140 lingue.
- Contesto token da 32.000: contesto di input sostanziale per analizzare i dati e gestire le attività di elaborazione.
Prova Gemma 3n Scaricalo su Kaggle Scaricalo su Hugging Face
Come per gli altri modelli Gemma, Gemma 3n viene fornito con pesi aperti e concesso in licenza per uso commerciale responsabile, il che ti consente di ottimizzarlo e di implementarlo nei tuoi progetti e nelle tue applicazioni.
Parametri del modello e parametri efficaci
I modelli Gemma 3n sono elencati con conteggi di parametri, ad esempio E2B e
E4B, inferiori al numero totale di parametri contenuti nei
modelli. Il prefisso E indica che questi modelli possono funzionare con un insieme ridotto di parametri efficaci. Questa operazione con un numero ridotto di parametri può essere eseguita utilizzando la tecnologia dei parametri flessibili integrata nei modelli Gemma 3n per consentirne il funzionamento efficiente su dispositivi con risorse inferiori.
I parametri nei modelli Gemma 3n sono suddivisi in 4 gruppi principali: testo, visivo, audio e embedding per livello (PLE). Con l'esecuzione standard del modello E2B, vengono caricati oltre 5 miliardi di parametri durante l'esecuzione del modello. Tuttavia, utilizzando le tecniche di salto dei parametri e di memorizzazione nella cache PLE, questo modello può essere gestito con un carico di memoria effettivo di poco meno di 2 miliardi (1,91 miliardi) di parametri, come illustrato nella Figura 1.
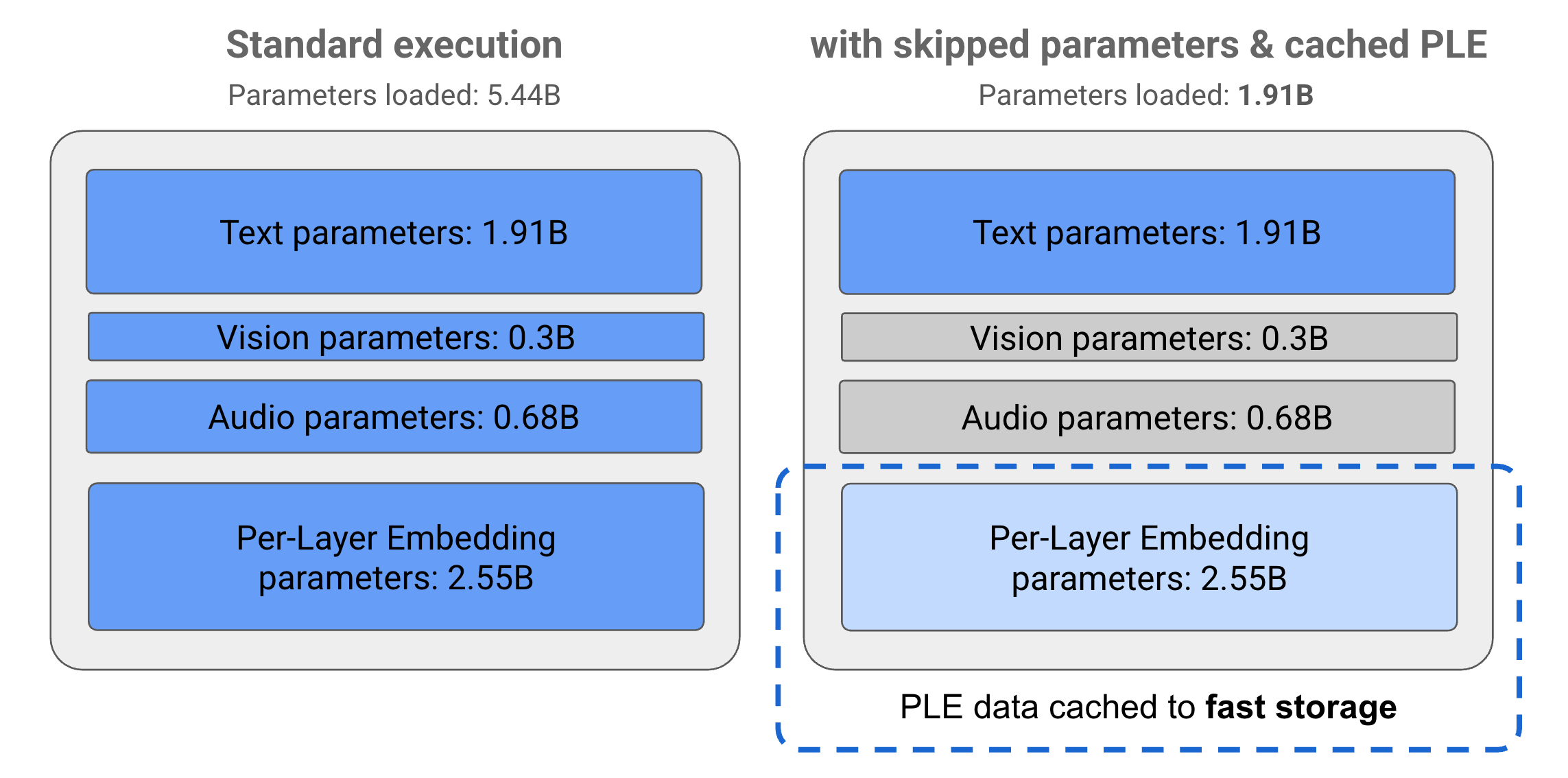
Figura 1. Parametri del modello E2B di Gemma 3n in esecuzione con esecuzione standard rispetto a un carico di parametri effettivamente inferiore utilizzando la memorizzazione nella cache PLE e le tecniche di eliminazione dei parametri.
Utilizzando queste tecniche di offload dei parametri e di attivazione selettiva, puoi eseguire il modello con un insieme molto ridotto di parametri o attivare parametri aggiuntivi per gestire altri tipi di dati, come quelli visivi e audio. Queste funzionalità consentono di aumentare o diminuire la funzionalità del modello in base alle funzionalità del dispositivo o ai requisiti delle attività. Le sezioni seguenti forniscono maggiori dettagli sulle tecniche di ottimizzazione dei parametri disponibili nei modelli Gemma 3n.
Memorizzazione nella cache PLE
I modelli Gemma 3n includono parametri di embedding per livello (PLE) che vengono utilizzati durante l'esecuzione del modello per creare dati che migliorano le prestazioni di ogni livello del modello. I dati PLE possono essere generati separatamente, al di fuori della memoria operativa del modello, memorizzati nella cache in un'unità di archiviazione rapida e poi aggiunti al processo di inferenza del modello durante l'esecuzione di ogni livello. Questo approccio consente di mantenere i parametri PLE al di fuori dello spazio di memoria del modello, riducendo il consumo di risorse e migliorando al contempo la qualità della risposta del modello.
Architettura di MatFormer
I modelli Gemma 3n utilizzano un'architettura del modello Matryoshka Transformer o MatFormer che contiene modelli più piccoli nidificati all'interno di un singolo modello più grande. I submodelli nidificati possono essere utilizzati per le deduzioni senza attivare i parametri dei modelli di contenimento quando si risponde alle richieste. Questa capacità di eseguire solo i modelli di base più piccoli all'interno di un modello MatFormer può ridurre il costo di calcolo, il tempo di risposta e l'impronta energetica del modello. Nel caso di Gemma 3n, il modello E4B contiene i parametri del modello E2B. Questa architettura consente inoltre di selezionare i parametri e assemblare modelli di dimensioni intermedie tra 2 e 4 miliardi. Per maggiori dettagli su questo approccio, consulta il documento di ricerca MatFormer. Prova a utilizzare le tecniche MatFormer per ridurre le dimensioni di un modello Gemma 3n con la guida di MatFormer Lab.
Caricamento dei parametri condizionali
Analogamente ai parametri PLE, puoi saltare il caricamento di alcuni parametri in memoria, come quelli audio o visivi, nel modello Gemma 3n per ridurre il carico della memoria. Questi parametri possono essere caricati dinamicamente in fase di runtime se il dispositivo dispone delle risorse richieste. In generale, l'omissione dei parametri può ridurre ulteriormente la memoria operativa richiesta per un modello Gemma 3n, consentendo l'esecuzione su una gamma più ampia di dispositivi e consentendo agli sviluppatori di aumentare l'efficienza delle risorse per attività meno impegnative.
Vuoi iniziare a creare?
Inizia
a utilizzare i modelli Gemma.