
Gemma 3n adalah model AI generatif yang dioptimalkan untuk digunakan di perangkat sehari-hari, seperti ponsel, laptop, dan tablet. Model ini mencakup inovasi dalam pemrosesan yang efisien parameter, termasuk cache parameter Per-Layer Embedding (PLE) dan arsitektur model MatFormer yang memberikan fleksibilitas untuk mengurangi persyaratan komputasi dan memori. Model ini menampilkan penanganan input audio, serta data teks dan visual.
Gemma 3n mencakup fitur utama berikut:
- Input audio: Memproses data suara untuk pengenalan ucapan, terjemahan, dan analisis data audio. Pelajari lebih lanjut
- Input visual dan teks: Kemampuan multimodal memungkinkan Anda menangani penglihatan, suara, dan teks untuk membantu Anda memahami dan menganalisis dunia di sekitar Anda. Pelajari lebih lanjut
- Encoder visi: Encoder MobileNet-V5 berperforma tinggi secara signifikan meningkatkan kecepatan dan akurasi pemrosesan data visual. Pelajari lebih lanjut
- Pemcachean PLE: Parameter Per-Layer Embedding (PLE) yang terdapat dalam model ini dapat di-cache ke penyimpanan lokal yang cepat untuk mengurangi biaya operasi memori model. Pelajari lebih lanjut
- Arsitektur MatFormer: Arsitektur Matryoshka Transformer memungkinkan aktivasi selektif parameter model per permintaan untuk mengurangi biaya komputasi dan waktu respons. Pelajari lebih lanjut
- Pemuatan parameter bersyarat: Mengabaikan pemuatan parameter visi dan audio dalam model untuk mengurangi jumlah total parameter yang dimuat dan menghemat resource memori. Pelajari lebih lanjut
- Dukungan bahasa yang luas: Kemampuan linguistik yang luas, dilatih dalam lebih dari 140 bahasa.
- Konteks token 32K: Konteks input yang substansial untuk menganalisis data dan menangani tugas pemrosesan.
Coba Gemma 3n Dapatkan di Kaggle Dapatkan di Hugging Face
Seperti model Gemma lainnya, Gemma 3n dilengkapi dengan bobot terbuka dan dilisensikan untuk penggunaan komersial yang bertanggung jawab, sehingga Anda dapat menyesuaikan dan men-deploy-nya di project dan aplikasi Anda sendiri.
Parameter model dan parameter efektif
Model Gemma 3n dicantumkan dengan jumlah parameter, seperti E2B dan
E4B, yang lebih rendah dari jumlah total parameter yang terdapat dalam
model. Awalan E menunjukkan bahwa model ini dapat beroperasi dengan kumpulan parameter Efektif yang dikurangi. Pengurangan operasi parameter ini dapat dicapai menggunakan
teknologi parameter fleksibel yang terintegrasi dalam model Gemma 3n untuk membantunya berjalan
secara efisien di perangkat dengan resource lebih rendah.
Parameter dalam model Gemma 3n dibagi menjadi 4 grup utama: parameter teks, visual, audio, dan penyematan per lapisan (PLE). Dengan eksekusi standar model E2B, lebih dari 5 miliar parameter dimuat saat menjalankan model. Namun, dengan menggunakan teknik caching PLE dan lewati parameter, model ini dapat dioperasikan dengan beban memori efektif yang hanya kurang dari 2 miliar (1,91 miliar) parameter, seperti yang diilustrasikan dalam Gambar 1.
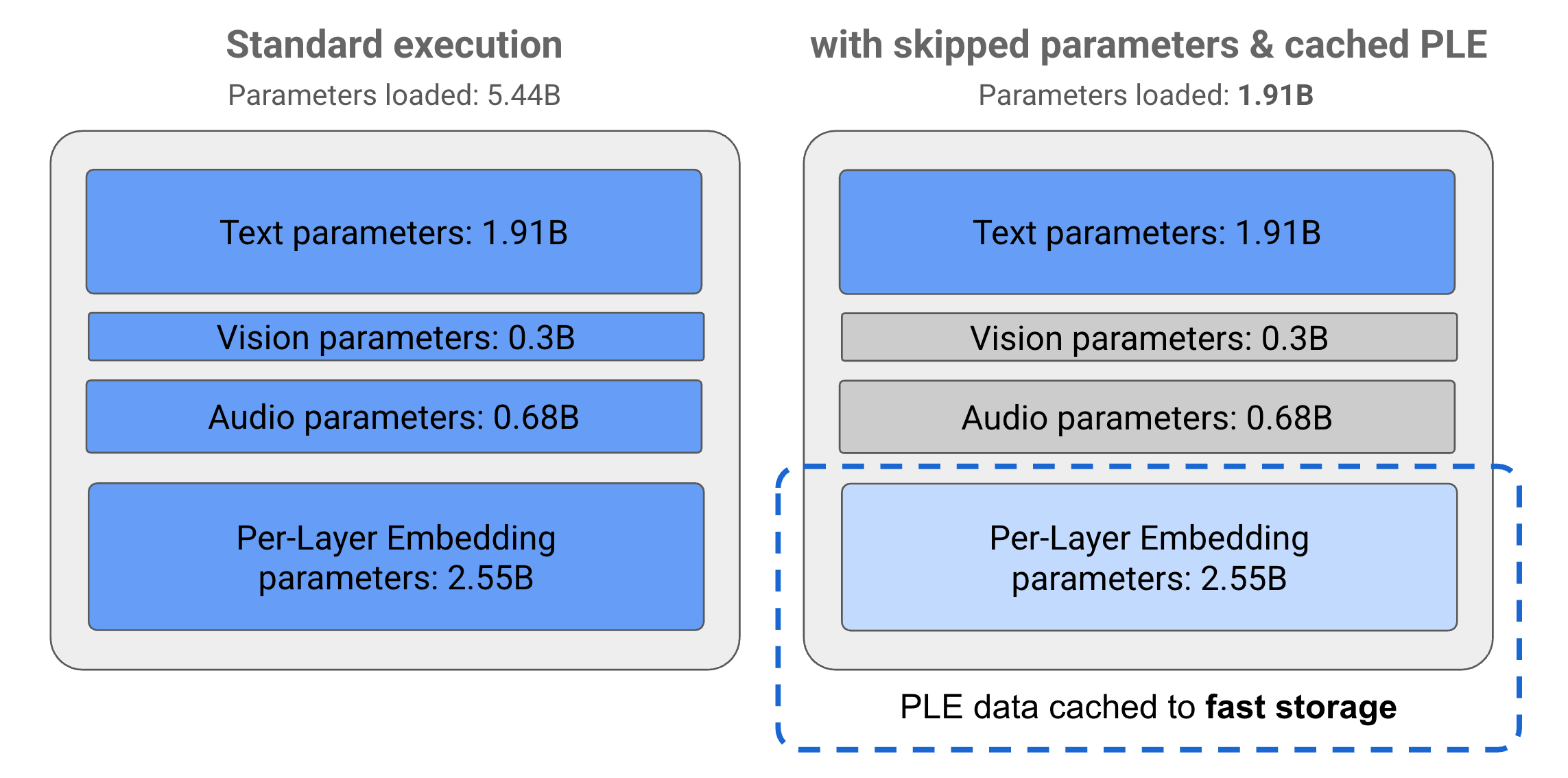
Gambar 1. Parameter model Gemma 3n E2B yang berjalan dalam eksekusi standar dibandingkan dengan pemuatan parameter yang lebih rendah secara efektif menggunakan teknik cache PLE dan lewati parameter.
Dengan menggunakan teknik penghentian parameter dan aktivasi selektif ini, Anda dapat menjalankan model dengan kumpulan parameter yang sangat ramping atau mengaktifkan parameter tambahan untuk menangani jenis data lain seperti visual dan audio. Fitur ini memungkinkan Anda meningkatkan fungsi model atau mengurangi kemampuan berdasarkan kemampuan perangkat atau persyaratan tugas. Bagian berikut menjelaskan lebih lanjut teknik parameter yang efisien yang tersedia di model Gemma 3n.
Pembuatan cache PLE
Model Gemma 3n menyertakan parameter Per-Layer Embedding (PLE) yang digunakan selama eksekusi model untuk membuat data yang meningkatkan performa setiap lapisan model. Data PLE dapat dibuat secara terpisah, di luar memori operasi model, di-cache ke penyimpanan cepat, lalu ditambahkan ke proses inferensi model saat setiap lapisan berjalan. Pendekatan ini memungkinkan parameter PLE tetap berada di luar ruang memori model, sehingga mengurangi penggunaan resource sekaligus meningkatkan kualitas respons model.
Arsitektur MatFormer
Model Gemma 3n menggunakan arsitektur model Matryoshka Transformer atau MatFormer yang berisi model bertingkat yang lebih kecil dalam satu model yang lebih besar. Sub-model bertingkat dapat digunakan untuk inferensi tanpa mengaktifkan parameter model yang melingkupi saat merespons permintaan. Kemampuan untuk hanya menjalankan model inti yang lebih kecil dalam model MatFormer dapat mengurangi biaya komputasi, dan waktu respons, serta jejak energi untuk model. Dalam kasus Gemma 3n, model E4B berisi parameter model E2B. Arsitektur ini juga memungkinkan Anda memilih parameter dan menyusun model dalam ukuran menengah antara 2B dan 4B. Untuk mengetahui detail selengkapnya tentang pendekatan ini, lihat makalah riset MatFormer. Coba gunakan teknik MatFormer untuk mengurangi ukuran model Gemma 3n dengan panduan MatFormer Lab.
Pemuatan parameter bersyarat
Serupa dengan parameter PLE, Anda dapat melewati pemuatan beberapa parameter ke dalam memori, seperti parameter audio atau visual, dalam model Gemma 3n untuk mengurangi beban memori. Parameter ini dapat dimuat secara dinamis saat runtime jika perangkat memiliki resource yang diperlukan. Secara keseluruhan, lewati parameter dapat lebih lanjut mengurangi memori operasi yang diperlukan untuk model Gemma 3n, sehingga memungkinkan eksekusi di berbagai perangkat dan memungkinkan developer meningkatkan efisiensi resource untuk tugas yang tidak terlalu memakan waktu.
Siap untuk mulai membangun?
Mulai
menggunakan model Gemma.