
Gemma 3n הוא מודל AI גנרטיבי שמותאם לשימוש במכשירים יומיומיים, כמו טלפונים, מחשבים ניידים וטאבלטים. המודל הזה כולל חידושים בתחום העיבוד היעיל של פרמטרים, כולל שמירת פרמטרים במטמון של Per-Layer Embedding (PLE) וארכיטקטורה של מודל MatFormer שמספקת את הגמישות להפחית את דרישות המחשוב והזיכרון. המודלים האלה כוללים טיפול בקלט אודיו, וגם נתונים חזותיים וטקסט.
Gemma 3n כוללת את התכונות העיקריות הבאות:
- קלט אודיו: עיבוד נתוני אודיו לצורך זיהוי דיבור, תרגום וניתוח נתוני אודיו. מידע נוסף
- קלט חזותי וטקסטואלי: יכולות מולטי-מודאליות מאפשרות לכם לטפל בתמונות, בצליל ובטקסט כדי לעזור לכם להבין ולנתח את העולם שסביבכם. מידע נוסף
- קידוד חזותי: קידוד MobileNet-V5 בעל הביצועים הגבוהים משפר באופן משמעותי את המהירות והדיוק של עיבוד נתונים חזותיים. מידע נוסף
- שמירה במטמון של PLE: אפשר לשמור במטמון אחסון מקומי מהיר את הפרמטרים של הטמעה בכל שכבה (PLE) שמכילים המודלים האלה, כדי לצמצם את עלויות הריצה בזיכרון של המודל. מידע נוסף
- ארכיטקטורת MatFormer: ארכיטקטורת Matryoshka Transformer מאפשרת הפעלה סלקטיבית של הפרמטרים של המודלים לכל בקשה, כדי לצמצם את עלויות המחשוב ואת זמני התגובה. מידע נוסף
- טעינה מותנית של פרמטרים: עקיפת הטעינה של פרמטרים של ראייה וקלט אודיו במודל כדי לצמצם את המספר הכולל של הפרמטרים הנטענים ולשמור על משאבי הזיכרון. מידע נוסף
- תמיכה בשפות רבות: יכולות לשפות רבות, שהוכשרו ביותר מ-140 שפות.
- הקשר של 32 אלף טוקנים: הקשר קלט משמעותי לניתוח נתונים ולטיפול במשימות עיבוד.
לנסות את Gemma 3n להורדה ב-Kaggle להורדה ב-Hugging Face
בדומה למודלים אחרים של Gemma, Gemma 3n כולל משקלים פתוחים ברישיון לשימוש מסחרי אחראי, שמאפשרים לכם לשפר אותו ולפרוס אותו בפרויקטים ובאפליקציות שלכם.
פרמטרים של מודל ופרמטרים אפקטיביים
מודלים של Gemma 3n מפורטים עם מספרי פרמטרים, כמו E2B ו-E4B, שנמוכים ממספר הפרמטרים הכולל שמכילים המודלים. הקידומת E מציינת שהמודלים האלה יכולים לפעול עם קבוצה מוקטנת של פרמטרים יעילים. כדי להפחית את מספר הפרמטרים, אפשר להשתמש בטכנולוגיית הפרמטרים הגמישה שמובנית בדגמי Gemma 3n, כדי לאפשר להם לפעול ביעילות במכשירים עם משאבים מוגבלים.
הפרמטרים במודלים של Gemma 3n מחולקים ל-4 קבוצות עיקריות: טקסט, חזותי, אודיו ו-PLE (הטמעה בכל שכבה). כשמריצים את מודל E2B באופן רגיל, נטענים יותר מ-5 מיליארד פרמטרים בזמן ההרצה. עם זאת, באמצעות טכניקות של דילוג על פרמטרים ואחסון במטמון של PLE, אפשר להפעיל את המודל הזה עם עומס זיכרון יעיל של קצת פחות מ-2 מיליארד (1.91 מיליארד) פרמטרים, כפי שמוצג באיור 1.
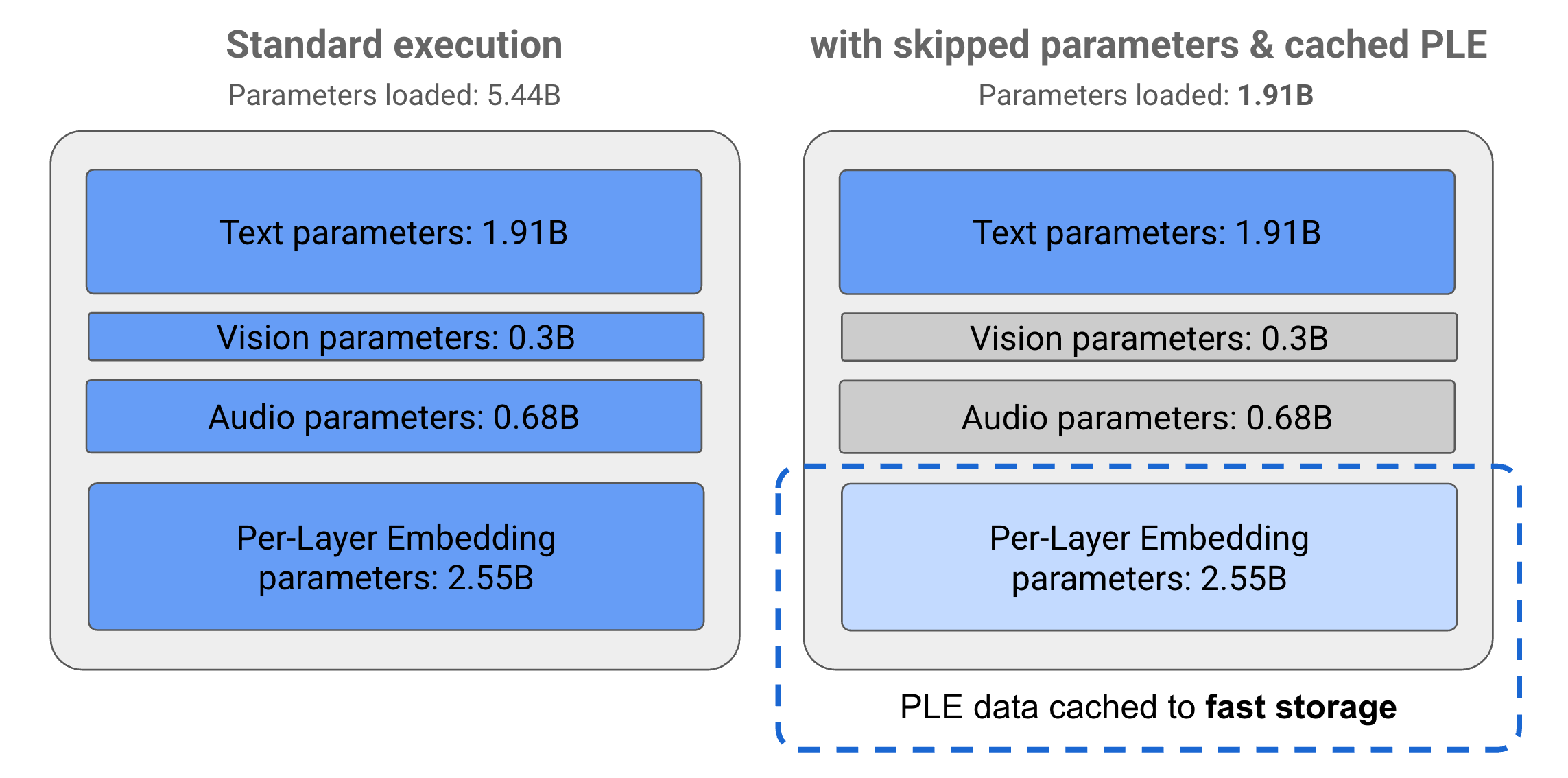
איור 1. פרמטרים של מודל Gemma 3n E2B שפועלים בהרצה רגילה לעומת עומס פרמטרים נמוך יותר בפועל באמצעות טכניקות של שמירת פרמטרים במטמון PLE ודילוג על פרמטרים.
בעזרת שיטות ההעברה של הפרמטרים וההפעלה הסלקטיבית, אפשר להריץ את המודל עם קבוצה מצומצמת מאוד של פרמטרים או להפעיל פרמטרים נוספים כדי לטפל בסוגי נתונים אחרים, כמו נתונים חזותיים או אודיו. התכונות האלה מאפשרות לכם להגדיל את הפונקציונליות של המודל או לצמצם את היכולות שלו בהתאם ליכולות המכשיר או לדרישות המשימה. בקטעים הבאים מוסבר בהרחבה על השיטות היעילות לבחירת פרמטרים שזמינות במודלים של Gemma 3n.
שמירת PLE במטמון
מודלים של Gemma 3n כוללים פרמטרים של הטמעה בכל שכבה (PLE) שמשמשים במהלך ביצוע המודל ליצירת נתונים שמשפרים את הביצועים של כל שכבת מודל. אפשר ליצור את נתוני ה-PLE בנפרד, מחוץ לזיכרון התפעול של המודל, לשמור אותם במטמון באחסון מהיר ולאחר מכן להוסיף אותם לתהליך ההסקה של המודל כשכל שכבה פועלת. הגישה הזו מאפשרת לשמור את הפרמטרים של PLE מחוץ למרחב הזיכרון של המודל, וכך לצמצם את צריכת המשאבים ועדיין לשפר את איכות התשובות של המודל.
הארכיטקטורה של MatFormer
במודלים של Gemma 3n נעשה שימוש בארכיטקטורת מודל של Matryoshka Transformer או MatFormer, שמכילה מודלים קטנים יותר בתוך מודל גדול אחד. אפשר להשתמש במודלים המשניים המוטמעים להסקת מסקנות בלי להפעיל את הפרמטרים של המודלים המקיפים כשמשיבים לבקשות. היכולת להריץ רק את המודלים הקטנים יותר של הליבה בתוך מודל MatFormer יכולה לצמצם את עלויות המחשוב, זמן התגובה ואת טביעת האנרגיה של המודל. במקרה של Gemma 3n, המודל E4B מכיל את הפרמטרים של המודל E2B. הארכיטקטורה הזו מאפשרת גם לבחור פרמטרים ולהרכיב מודלים בגדלים בטווח הביניים של 2 מיליארד עד 4 מיליארד. למידע נוסף על הגישה הזו, אפשר לעיין במאמר המחקר על MatFormer. כדאי לנסות להשתמש בשיטות של MatFormer כדי לצמצם את הגודל של מודל Gemma 3n באמצעות המדריך ב-MatFormer Lab.
טעינת פרמטרים מותנים
בדומה לפרמטרים של PLE, אפשר לדלג על טעינת פרמטרים מסוימים לזיכרון, כמו פרמטרים של אודיו או חזותיים, במודל Gemma 3n כדי להפחית את עומס הזיכרון. אפשר לטעון את הפרמטרים האלה באופן דינמי בזמן הריצה, אם יש במכשיר את המשאבים הנדרשים. באופן כללי, דילוג על פרמטרים יכול לצמצם עוד יותר את נפח הזיכרון הנדרש לפעולה במודל Gemma 3n, וכך לאפשר הפעלה במגוון רחב יותר של מכשירים ולאפשר למפתחים לשפר את יעילות השימוש במשאבים במשימות פחות תובעניות.
רוצים להתחיל לפתח?
מתחילים לעבוד עם מודלים של Gemma