
Gemma 3n es un modelo de IA generativa optimizado para su uso en dispositivos cotidianos, como teléfonos, laptops y tablets. Este modelo incluye innovaciones en el procesamiento eficiente de parámetros, incluida la caché de parámetros de la incorporación por capa (PLE) y una arquitectura de modelo de MatFormer que proporciona la flexibilidad para reducir los requisitos de procesamiento y memoria. Estos modelos incluyen el manejo de entradas de audio, así como datos visuales y de texto.
Gemma 3n incluye las siguientes funciones clave:
- Entrada de audio: Procesa datos de sonido para el reconocimiento de voz, la traducción y el análisis de datos de audio. Más información
- Entrada visual y de texto: Las capacidades multimodales te permiten controlar la visión, el sonido y el texto para ayudarte a comprender y analizar el mundo que te rodea. Más información
- Codificación de visión: El codificador MobileNet-V5 de alto rendimiento mejora de manera significativa la velocidad y la precisión del procesamiento de datos visuales. Más información
- Almacenamiento en caché de PLE: Los parámetros de incorporación por capa (PLE) contenidos en estos modelos se pueden almacenar en caché en un almacenamiento local y rápido para reducir los costos de ejecución de la memoria del modelo. Más información
- Arquitectura de MatFormer: La arquitectura de Matryoshka Transformer permite la activación selectiva de los parámetros de los modelos por solicitud para reducir el costo de procesamiento y los tiempos de respuesta. Más información
- Carga de parámetros condicionales: Omite la carga de parámetros de visión y audio en el modelo para reducir la cantidad total de parámetros cargados y ahorrar recursos de memoria. Más información
- Compatibilidad con varios idiomas: Amplias capacidades lingüísticas, entrenadas en más de 140 idiomas.
- Contexto de tokens de 32,000: Es un contexto de entrada sustancial para analizar datos y controlar tareas de procesamiento.
Probar Gemma 3n Obtén en Kaggle Obtén en Hugging Face
Al igual que con otros modelos de Gemma, Gemma 3n se proporciona con pesos abiertos y con licencia para uso comercial responsable, lo que te permite ajustarlo y, luego, implementarlo en tus propios proyectos y aplicaciones.
Parámetros del modelo y parámetros efectivos
Los modelos Gemma 3n se enumeran con recuentos de parámetros, como E2B y E4B, que son más bajos que la cantidad total de parámetros contenidos en los modelos. El prefijo E indica que estos modelos pueden operar con un conjunto reducido de parámetros efectivos. Esta operación de parámetros reducidos se puede lograr con la tecnología de parámetros flexibles integrada en los modelos Gemma 3n para ayudarlos a ejecutarse de manera eficiente en dispositivos con menos recursos.
Los parámetros de los modelos de Gemma 3n se dividen en 4 grupos principales: texto, visual, audio y parámetros de incorporación por capa (PLE). Con la ejecución estándar del modelo E2B, se cargan más de 5,000 millones de parámetros cuando se ejecuta el modelo. Sin embargo, con las técnicas de omisión de parámetros y almacenamiento en caché de PLE, este modelo se puede operar con una carga de memoria efectiva de poco menos de 2,000 millones (1,910 millones) de parámetros, como se ilustra en la Figura 1.
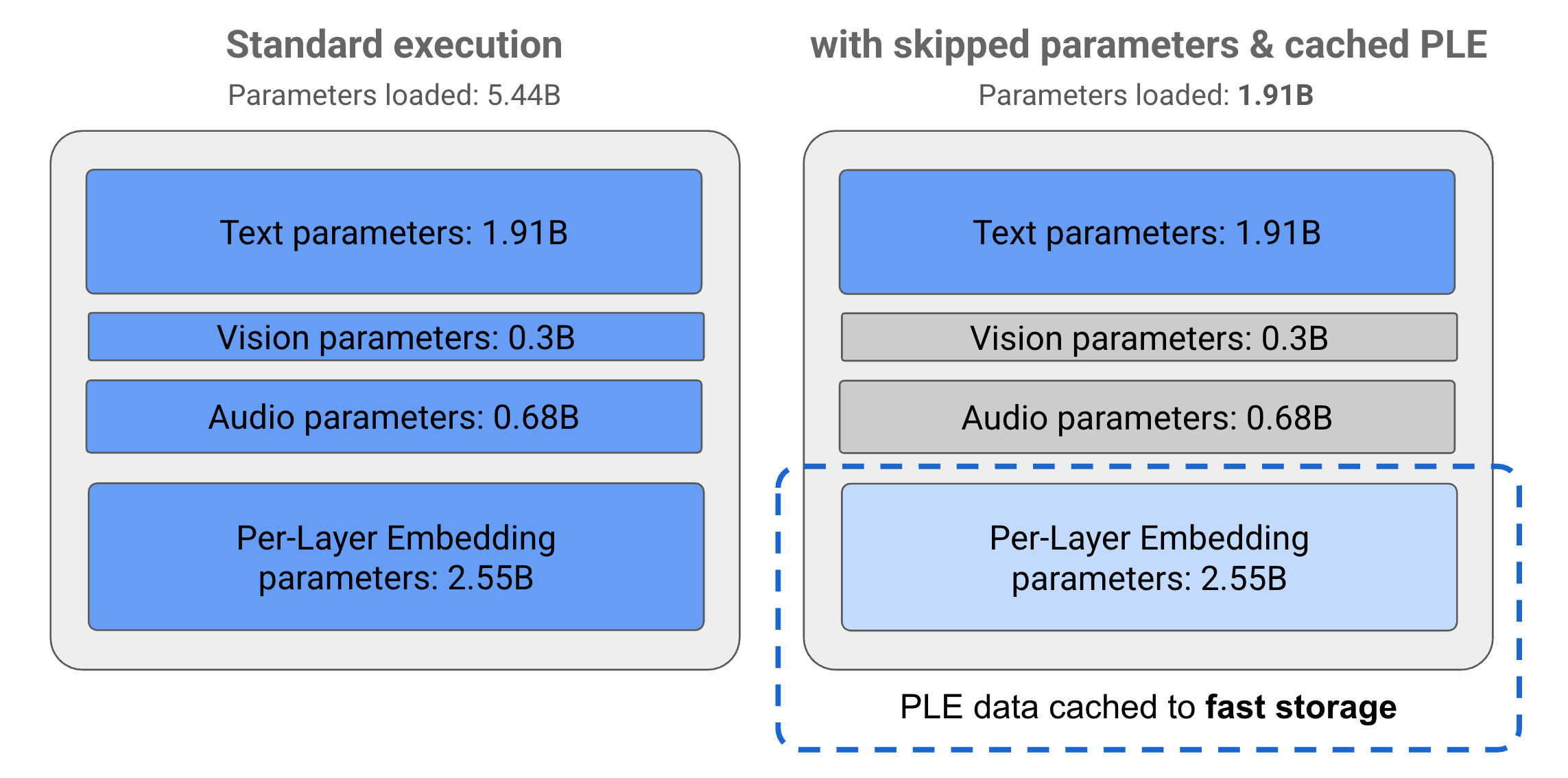
Figura 1: Parámetros del modelo E2B de Gemma 3n que se ejecutan en una ejecución estándar en comparación con una carga de parámetros efectivamente más baja mediante el almacenamiento en caché de PLE y técnicas de omisión de parámetros.
Con estas técnicas de descarga de parámetros y activación selectiva, puedes ejecutar el modelo con un conjunto muy reducido de parámetros o activar parámetros adicionales para controlar otros tipos de datos, como los visuales y de audio. Estas funciones te permiten aumentar o disminuir la funcionalidad del modelo según las funciones del dispositivo o los requisitos de la tarea. En las siguientes secciones, se explica más sobre las técnicas de parámetros eficientes disponibles en los modelos de Gemma 3n.
Almacenamiento en caché de PLE
Los modelos de Gemma 3n incluyen parámetros de incorporación por capa (PLE) que se usan durante la ejecución del modelo para crear datos que mejoran el rendimiento de cada capa del modelo. Los datos de PLE se pueden generar por separado, fuera de la memoria operativa del modelo, almacenarse en caché para el almacenamiento rápido y, luego, agregarse al proceso de inferencia del modelo a medida que se ejecuta cada capa. Este enfoque permite que los parámetros de PLE se mantengan fuera del espacio de memoria del modelo, lo que reduce el consumo de recursos y, al mismo tiempo, mejora la calidad de la respuesta del modelo.
Arquitectura de MatFormer
Los modelos de Gemma 3n usan una arquitectura de modelo de Matryoshka Transformer o MatFormer que contiene modelos anidados más pequeños dentro de un solo modelo más grande. Los submodelos anidados se pueden usar para inferencias sin activar los parámetros de los modelos envolventes cuando se responden las solicitudes. Esta capacidad de ejecutar solo los modelos principales más pequeños dentro de un modelo de MatFormer puede reducir el costo de procesamiento, el tiempo de respuesta y la huella de energía del modelo. En el caso de Gemma 3n, el modelo E4B contiene los parámetros del modelo E2B. Esta arquitectura también te permite seleccionar parámetros y ensamblar modelos en tamaños intermedios entre 2B y 4B. Para obtener más detalles sobre este enfoque, consulta el artículo de investigación de MatFormer. Intenta usar técnicas de MatFormer para reducir el tamaño de un modelo Gemma 3n con la guía de MatFormer Lab.
Carga de parámetros condicionales
Al igual que con los parámetros de PLE, puedes omitir la carga de algunos parámetros en la memoria, como los parámetros de audio o visuales, en el modelo Gemma 3n para reducir la carga de memoria. Estos parámetros se pueden cargar de forma dinámica en el tiempo de ejecución si el dispositivo tiene los recursos necesarios. En general, el omitición de parámetros puede reducir aún más la memoria operativa requerida para un modelo Gemma 3n, lo que permite la ejecución en una gama más amplia de dispositivos y permite a los desarrolladores aumentar la eficiencia de los recursos para tareas menos exigentes.
¿Todo listo para comenzar a compilar?
Comienza a usar
los modelos de Gemma.