
Gemma 3n ist ein generatives KI-Modell, das für die Verwendung auf Alltagsgeräten wie Smartphones, Laptops und Tablets optimiert ist. Dieses Modell enthält Innovationen in der parametereffizienten Verarbeitung, darunter das Parameter-Caching für Per-Layer Embedding (PLE) und eine MatFormer-Modellarchitektur, die die Flexibilität bietet, die Rechen- und Arbeitsspeicheranforderungen zu reduzieren. Diese Modelle unterstützen die Verarbeitung von Audioeingaben sowie Text- und visuelle Daten.
Gemma 3n bietet folgende Hauptfunktionen:
- Audioeingabe: Verarbeitung von Audiodaten für Spracherkennung, Übersetzung und Audiodatenanalyse. Weitere Informationen
- Visuelle und Texteingaben: Mit multimodalen Funktionen können Sie Bilder, Ton und Text verarbeiten, um die Welt um Sie herum besser zu verstehen und zu analysieren. Weitere Informationen
- Vision-Encoder:Der leistungsstarke MobileNet-V5-Encoder verbessert die Geschwindigkeit und Genauigkeit der Verarbeitung visueller Daten erheblich. Weitere Informationen
- PLE-Caching: Die in diesen Modellen enthaltenen PLE-Parameter (Per-Layer Embedding) können im schnellen lokalen Speicher zwischengespeichert werden, um die Kosten für die Ausführung im Arbeitsspeicher des Modells zu senken. Weitere Informationen
- MatFormer-Architektur: Die Matryoshka-Transformer-Architektur ermöglicht die selektive Aktivierung der Modellparameter pro Anfrage, um die Rechenkosten und Antwortzeiten zu senken. Weitere Informationen
- Bedingtes Laden von Parametern:Sie können das Laden von Bild- und Audioparametern im Modell umgehen, um die Gesamtzahl der geladenen Parameter zu reduzieren und Arbeitsspeicherressourcen zu sparen. Weitere Informationen
- Umfangreiche Sprachunterstützung: Umfangreiche Sprachfunktionen, trainiert in über 140 Sprachen.
- 32.000-Token-Kontext: Umfangreicher Eingabekontext für die Analyse von Daten und die Verarbeitung von Aufgaben.
Gemma 3n testen Auf Kaggle herunterladen Auf Hugging Face herunterladen
Wie bei anderen Gemma-Modellen werden für Gemma 3n offene Gewichte bereitgestellt und es ist für die verantwortungsvolle kommerzielle Nutzung lizenziert. Sie können es also optimieren und in Ihren eigenen Projekten und Anwendungen einsetzen.
Modellparameter und effektive Parameter
Gemma 3n-Modelle werden mit Parameterzahlen wie E2B und E4B aufgeführt, die niedriger als die Gesamtzahl der Parameter in den Modellen sind. Das Präfix E gibt an, dass diese Modelle mit einer reduzierten Anzahl effektiver Parameter ausgeführt werden können. Dieser reduzierte Parameterbetrieb kann mit der flexiblen Parametertechnologie erreicht werden, die in Gemma 3n-Modellen integriert ist, um sie effizient auf Geräten mit weniger Ressourcen auszuführen.
Die Parameter in Gemma 3n-Modellen sind in vier Hauptgruppen unterteilt: Text-, visuelle, Audio- und PLE-Parameter (Embedding pro Ebene). Bei der Standardausführung des E2B-Modells werden bei der Ausführung des Modells über 5 Milliarden Parameter geladen. Mithilfe von Parameter-Überspringen und PLE-Caching-Techniken kann dieses Modell jedoch mit einer effektiven Speicherauslastung von knapp 2 Milliarden (1,91 Milliarden) Parametern betrieben werden, wie in Abbildung 1 dargestellt.
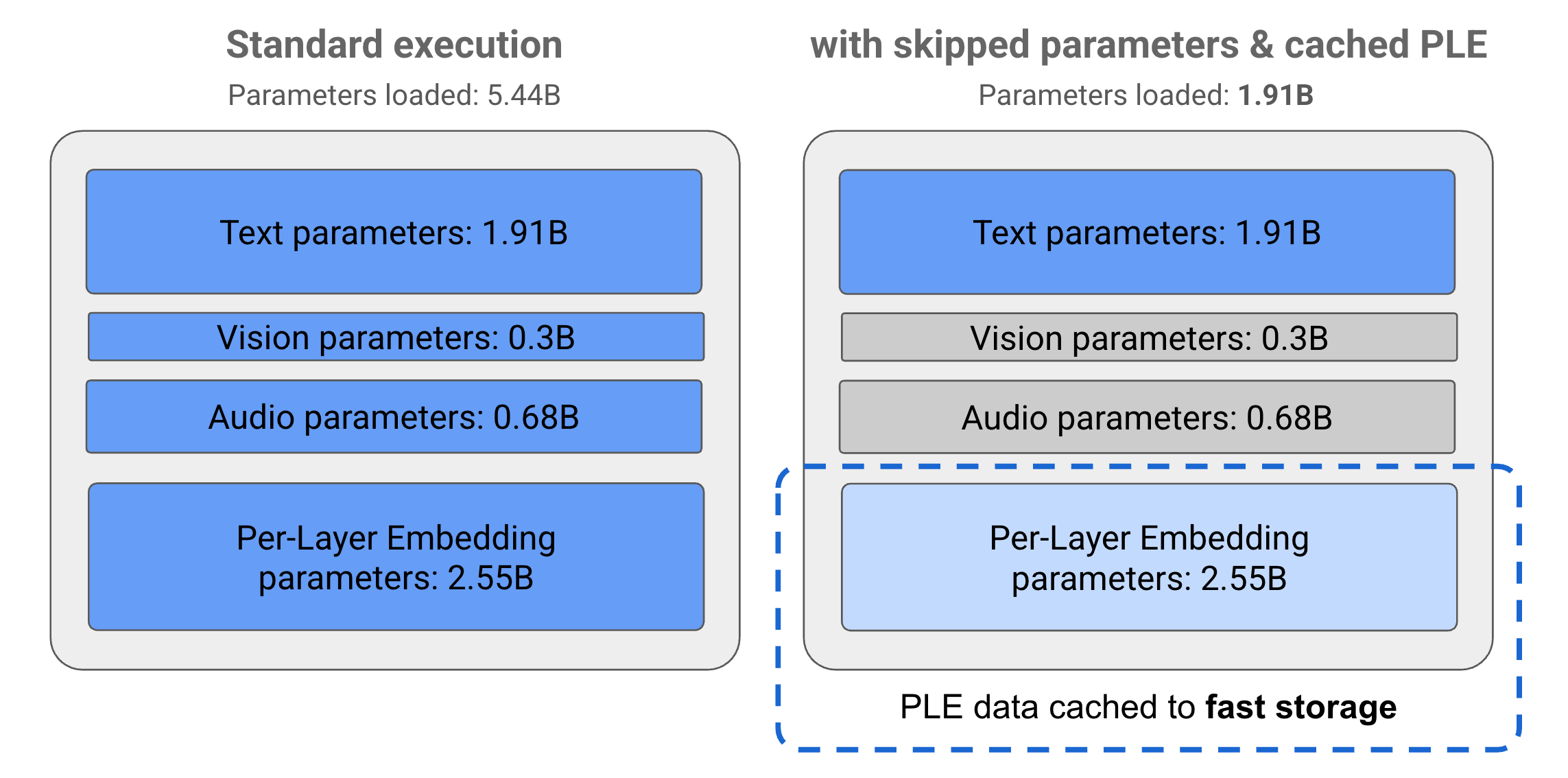
Abbildung 1. Gemma-3n-E2B-Modellparameter bei der Standardausführung im Vergleich zu einer effektiv niedrigeren Parameterlast mit PLE-Caching und Parameter-Überspringungstechniken.
Mit diesen Techniken zum Auslagern von Parametern und zur selektiven Aktivierung können Sie das Modell mit einer sehr schlanken Gruppe von Parametern ausführen oder zusätzliche Parameter aktivieren, um andere Datentypen wie visuelle und Audiodaten zu verarbeiten. Mit diesen Funktionen können Sie die Modellfunktionen je nach Gerätefunktionen oder Aufgabenanforderungen hoch- oder herunterfahren. In den folgenden Abschnitten erfahren Sie mehr über die parametereffizienten Verfahren, die in Gemma 3n-Modellen verfügbar sind.
PLE-Caching
Gemma 3n-Modelle enthalten Parameter für die schichtweise Einbettung (Per-Layer Embedding, PLE), die während der Modellausführung verwendet werden, um Daten zu erstellen, die die Leistung jeder Modellschicht verbessern. Die PLE-Daten können separat außerhalb des Arbeitsspeichers des Modells generiert, im schnellen Speicher zwischengespeichert und dann dem Modellinferenzprozess hinzugefügt werden, während jede Schicht ausgeführt wird. Mit diesem Ansatz können PLE-Parameter aus dem Modellspeicherplatz ferngehalten werden, wodurch der Ressourcenverbrauch reduziert wird und gleichzeitig die Qualität der Modellantworten verbessert wird.
MatFormer-Architektur
Gemma 3n-Modelle verwenden eine Matryoshka-Transformer- oder MatFormer-Modellarchitektur, die verschachtelte, kleinere Modelle in einem einzelnen, größeren Modell enthält. Die verschachtelten Untermodelle können für Inferenzen verwendet werden, ohne dass die Parameter der übergeordneten Modelle bei der Beantwortung von Anfragen aktiviert werden müssen. Die Möglichkeit, nur die kleineren Kernmodelle innerhalb eines MatFormer-Modells auszuführen, kann die Rechenkosten, die Reaktionszeit und den Energieverbrauch des Modells senken. Bei Gemma 3n enthält das E4B-Modell die Parameter des E2B-Modells. Mit dieser Architektur können Sie auch Parameter auswählen und Modelle in mittleren Größen zwischen 2 und 4 Billionen Parametern zusammenstellen. Weitere Informationen zu diesem Ansatz finden Sie im Forschungspapier zu MatFormer. Mithilfe von MatFormer-Techniken können Sie die Größe eines Gemma 3n-Modells mit dem Leitfaden MatFormer Lab reduzieren.
Bedingtes Laden von Parametern
Ähnlich wie bei PLE-Parametern können Sie das Laden einiger Parameter in den Arbeitsspeicher des Gemma 3n-Modells überspringen, z. B. Audio- oder visuelle Parameter, um die Arbeitsspeicherbelastung zu reduzieren. Diese Parameter können zur Laufzeit dynamisch geladen werden, wenn das Gerät die erforderlichen Ressourcen hat. Insgesamt kann das Überspringen von Parametern den erforderlichen Arbeitsspeicher für ein Gemma 3n-Modell weiter reduzieren. So ist die Ausführung auf einer größeren Anzahl von Geräten möglich und Entwickler können die Ressourceneffizienz bei weniger anspruchsvollen Aufgaben steigern.
Sind Sie bereit?
Erste Schritte mit Gemma-Modellen