Gemini peut analyser des entrées audio et générer des réponses textuelles.
Python
from google import genai
client = genai.Client()
myfile = client.files.upload(file="path/to/sample.mp3")
response = client.models.generate_content(
model="gemini-3-flash-preview", contents=["Describe this audio clip", myfile]
)
print(response.text)
JavaScript
import {
GoogleGenAI,
createUserContent,
createPartFromUri,
} from "@google/genai";
const ai = new GoogleGenAI({});
async function main() {
const myfile = await ai.files.upload({
file: "path/to/sample.mp3",
config: { mimeType: "audio/mp3" },
});
const response = await ai.models.generateContent({
model: "gemini-3-flash-preview",
contents: createUserContent([
createPartFromUri(myfile.uri, myfile.mimeType),
"Describe this audio clip",
]),
});
console.log(response.text);
}
await main();
Go
package main
import (
"context"
"fmt"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
localAudioPath := "/path/to/sample.mp3"
uploadedFile, _ := client.Files.UploadFromPath(
ctx,
localAudioPath,
nil,
)
parts := []*genai.Part{
genai.NewPartFromText("Describe this audio clip"),
genai.NewPartFromURI(uploadedFile.URI, uploadedFile.MIMEType),
}
contents := []*genai.Content{
genai.NewContentFromParts(parts, genai.RoleUser),
}
result, _ := client.Models.GenerateContent(
ctx,
"gemini-3-flash-preview",
contents,
nil,
)
fmt.Println(result.Text())
}
REST
AUDIO_PATH="path/to/sample.mp3"
MIME_TYPE=$(file -b --mime-type "${AUDIO_PATH}")
NUM_BYTES=$(wc -c < "${AUDIO_PATH}")
DISPLAY_NAME=AUDIO
tmp_header_file=upload-header.tmp
# Initial resumable request defining metadata.
# The upload url is in the response headers dump them to a file.
curl "https://generativelanguage.googleapis.com/upload/v1beta/files" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-D upload-header.tmp \
-H "X-Goog-Upload-Protocol: resumable" \
-H "X-Goog-Upload-Command: start" \
-H "X-Goog-Upload-Header-Content-Length: ${NUM_BYTES}" \
-H "X-Goog-Upload-Header-Content-Type: ${MIME_TYPE}" \
-H "Content-Type: application/json" \
-d "{'file': {'display_name': '${DISPLAY_NAME}'}}" 2> /dev/null
upload_url=$(grep -i "x-goog-upload-url: " "${tmp_header_file}" | cut -d" " -f2 | tr -d "\r")
rm "${tmp_header_file}"
# Upload the actual bytes.
curl "${upload_url}" \
-H "Content-Length: ${NUM_BYTES}" \
-H "X-Goog-Upload-Offset: 0" \
-H "X-Goog-Upload-Command: upload, finalize" \
--data-binary "@${AUDIO_PATH}" 2> /dev/null > file_info.json
file_uri=$(jq ".file.uri" file_info.json)
echo file_uri=$file_uri
# Now generate content using that file
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-flash-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"contents": [{
"parts":[
{"text": "Describe this audio clip"},
{"file_data":{"mime_type": "${MIME_TYPE}", "file_uri": '$file_uri'}}]
}]
}' 2> /dev/null > response.json
cat response.json
echo
jq ".candidates[].content.parts[].text" response.json
Présentation
Gemini peut analyser et comprendre des entrées audio, et générer des réponses textuelles. Il permet ainsi d'utiliser des cas d'utilisation tels que les suivants :
- Décrire, résumer ou répondre à des questions sur un contenu audio
- Fournir une transcription et une traduction de l'audio (reconnaissance vocale)
- Détecter les émotions dans la parole et la musique
- Analyser des segments spécifiques de l'audio et fournir des horodatages
Pour le moment, l'API Gemini n'est pas compatible avec les cas d'utilisation de transcription en temps réel. Pour les interactions vocales et vidéo en temps réel, consultez l'API Live. Pour les modèles de reconnaissance vocale dédiés compatibles avec la transcription en temps réel, utilisez l'API Google Cloud Speech-to-Text.
Transcrire la voix en texte
Cet exemple d'application montre comment inviter l'API Gemini à transcrire, traduire et résumer la parole, y compris les horodatages et la détection des émotions à l'aide de sorties structurées.
Python
from google import genai
from google.genai import types
client = genai.Client()
YOUTUBE_URL = "https://www.youtube.com/watch?v=ku-N-eS1lgM"
def main():
prompt = """
Process the audio file and generate a detailed transcription.
Requirements:
1. Provide accurate timestamps for each segment (Format: MM:SS).
2. Detect the primary language of each segment.
3. If the segment is in a language different than English, also provide the English translation.
4. Identify the primary emotion of the speaker in this segment. You MUST choose exactly one of the following: Happy, Sad, Angry, Neutral.
5. Provide a brief summary of the entire audio at the beginning.
"""
response = client.models.generate_content(
model="gemini-3-flash-preview",
contents=[
types.Content(
parts=[
types.Part(
file_data=types.FileData(
file_uri=YOUTUBE_URL
)
),
types.Part(
text=prompt
)
]
)
],
config=types.GenerateContentConfig(
response_mime_type="application/json",
response_schema=types.Schema(
type=types.Type.OBJECT,
properties={
"summary": types.Schema(
type=types.Type.STRING,
description="A concise summary of the audio content.",
),
"segments": types.Schema(
type=types.Type.ARRAY,
description="List of transcribed segments with timestamp.",
items=types.Schema(
type=types.Type.OBJECT,
properties={
"timestamp": types.Schema(type=types.Type.STRING),
"content": types.Schema(type=types.Type.STRING),
"language": types.Schema(type=types.Type.STRING),
"language_code": types.Schema(type=types.Type.STRING),
"translation": types.Schema(type=types.Type.STRING),
"emotion": types.Schema(
type=types.Type.STRING,
enum=["happy", "sad", "angry", "neutral"]
),
},
required=["timestamp", "content", "language", "language_code", "emotion"],
),
),
},
required=["summary", "segments"],
),
),
)
print(response.text)
if __name__ == "__main__":
main()
JavaScript
import {
GoogleGenAI,
Type
} from "@google/genai";
const ai = new GoogleGenAI({});
const YOUTUBE_URL = "https://www.youtube.com/watch?v=ku-N-eS1lgM";
async function main() {
const prompt = `
Process the audio file and generate a detailed transcription.
Requirements:
1. Provide accurate timestamps for each segment (Format: MM:SS).
2. Detect the primary language of each segment.
3. If the segment is in a language different than English, also provide the English translation.
4. Identify the primary emotion of the speaker in this segment. You MUST choose exactly one of the following: Happy, Sad, Angry, Neutral.
5. Provide a brief summary of the entire audio at the beginning.
`;
const Emotion = {
Happy: 'happy',
Sad: 'sad',
Angry: 'angry',
Neutral: 'neutral'
};
const response = await ai.models.generateContent({
model: "gemini-3-flash-preview",
contents: {
parts: [
{
fileData: {
fileUri: YOUTUBE_URL,
},
},
{
text: prompt,
},
],
},
config: {
responseMimeType: "application/json",
responseSchema: {
type: Type.OBJECT,
properties: {
summary: {
type: Type.STRING,
description: "A concise summary of the audio content.",
},
segments: {
type: Type.ARRAY,
description: "List of transcribed segments with timestamp.",
items: {
type: Type.OBJECT,
properties: {
timestamp: { type: Type.STRING },
content: { type: Type.STRING },
language: { type: Type.STRING },
language_code: { type: Type.STRING },
translation: { type: Type.STRING },
emotion: {
type: Type.STRING,
enum: Object.values(Emotion)
},
},
required: ["timestamp", "content", "language", "language_code", "emotion"],
},
},
},
required: ["summary", "segments"],
},
},
});
const json = JSON.parse(response.text);
console.log(json);
}
await main();
REST
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-flash-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"contents": [
{
"parts": [
{
"file_data": {
"file_uri": "https://www.youtube.com/watch?v=ku-N-eS1lgM",
"mime_type": "video/mp4"
}
},
{
"text": "Process the audio file and generate a detailed transcription.\n\nRequirements:\n1. Provide accurate timestamps for each segment (Format: MM:SS).\n2. Detect the primary language of each segment.\n3. If the segment is in a language different than English, also provide the English translation.\n4. Identify the primary emotion of the speaker in this segment. You MUST choose exactly one of the following: Happy, Sad, Angry, Neutral.\n5. Provide a brief summary of the entire audio at the beginning."
}
]
}
],
"generation_config": {
"response_mime_type": "application/json",
"response_schema": {
"type": "OBJECT",
"properties": {
"summary": {
"type": "STRING",
"description": "A concise summary of the audio content."
},
"segments": {
"type": "ARRAY",
"description": "List of transcribed segments with timestamp.",
"items": {
"type": "OBJECT",
"properties": {
"timestamp": { "type": "STRING" },
"content": { "type": "STRING" },
"language": { "type": "STRING" },
"language_code": { "type": "STRING" },
"translation": { "type": "STRING" },
"emotion": {
"type": "STRING",
"enum": ["happy", "sad", "angry", "neutral"]
}
},
"required": ["timestamp", "content", "language", "language_code", "emotion"]
}
}
},
"required": ["summary", "segments"]
}
}
}' 2> /dev/null > response.json
cat response.json
echo
jq ".candidates[].content.parts[].text" response.json
Vous pouvez inviter AI Studio Build à créer une application comme cet exemple d'application de transcription en un seul clic.
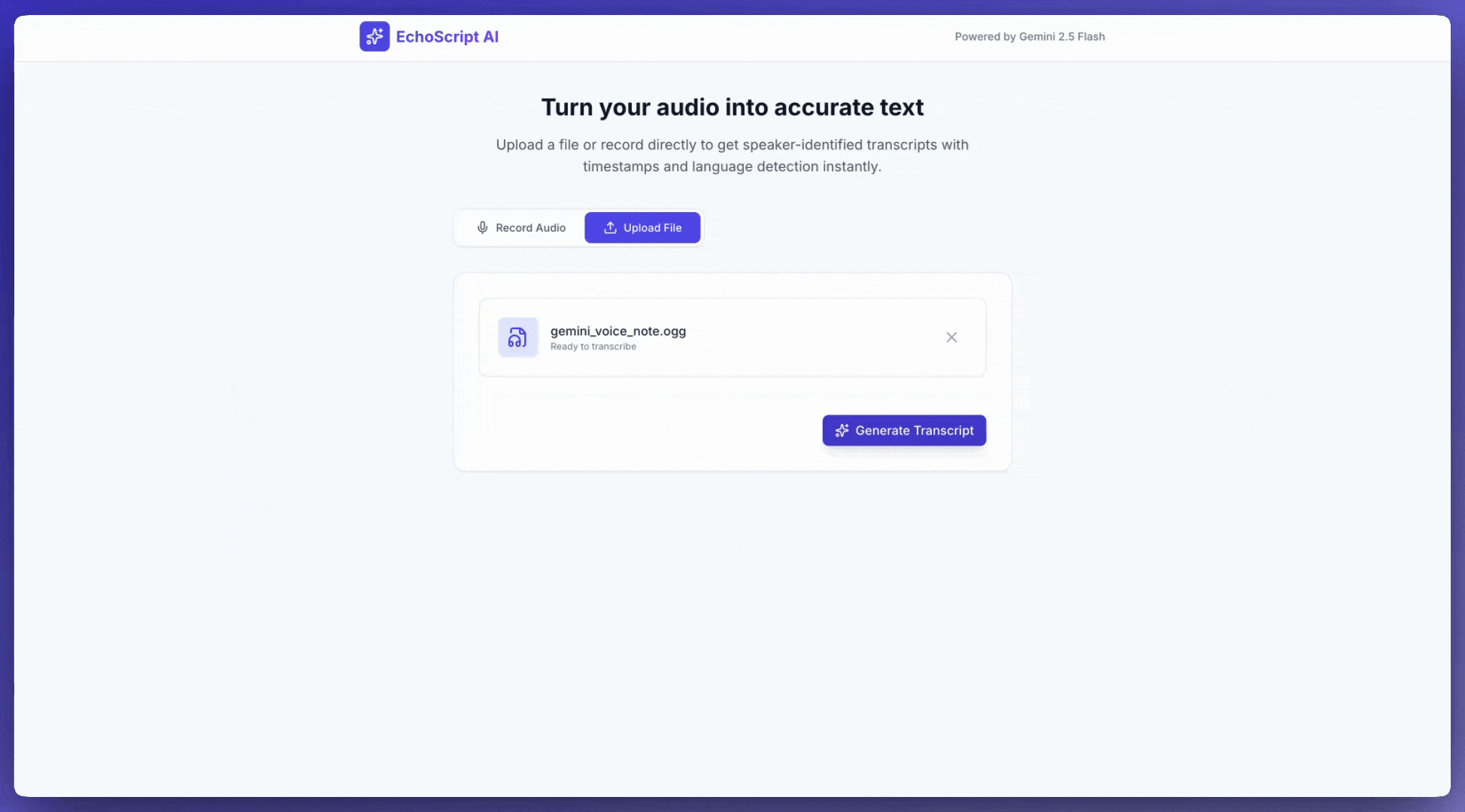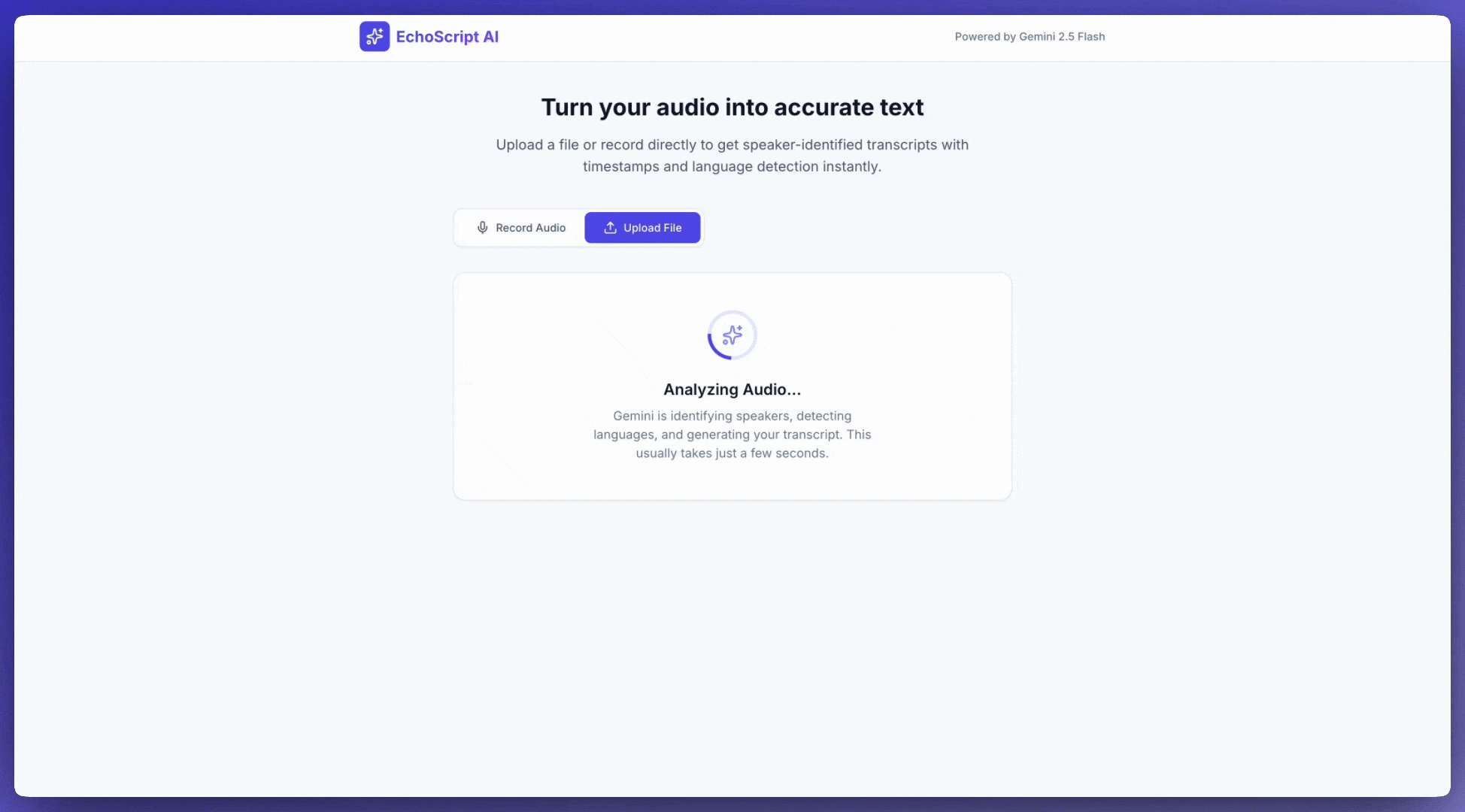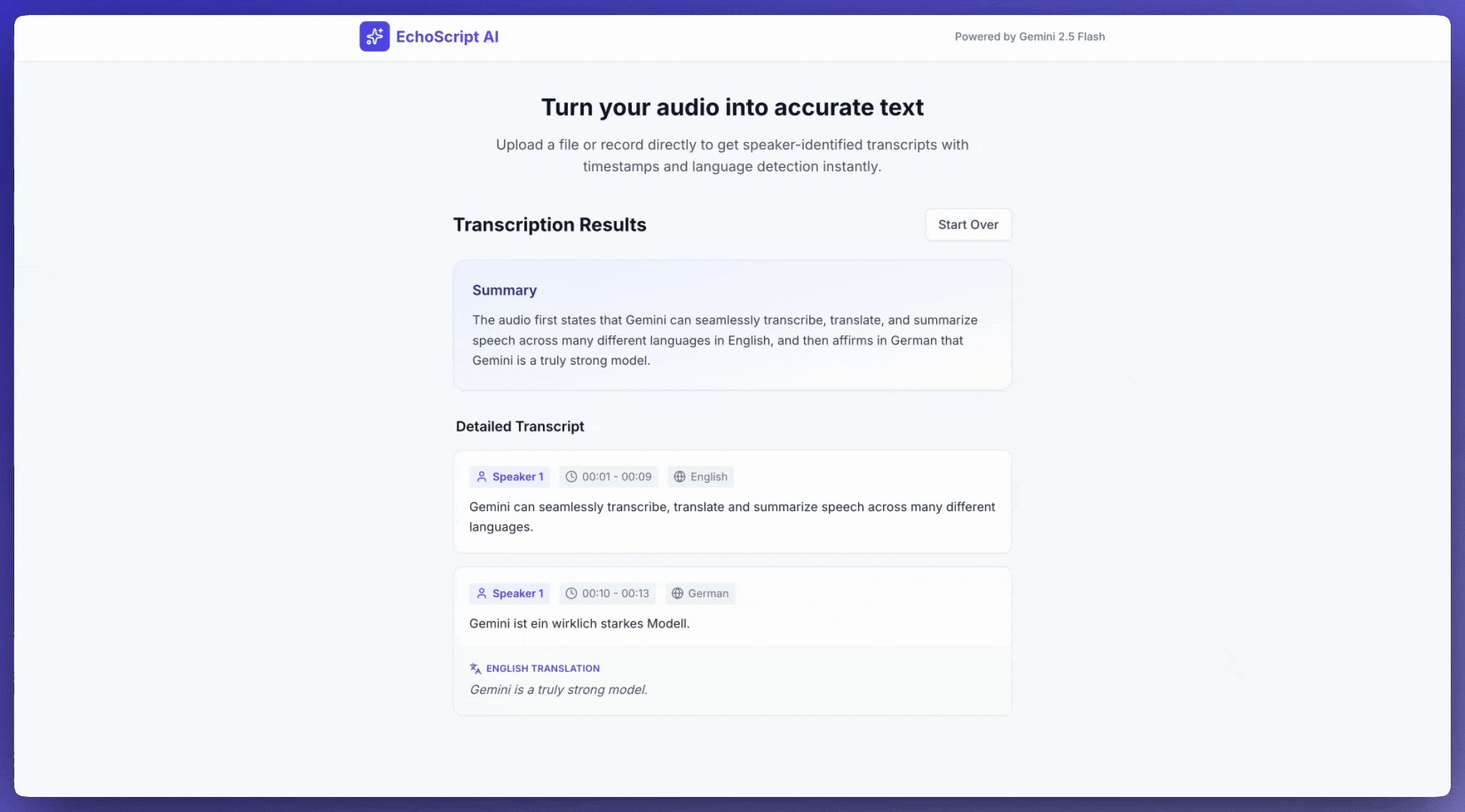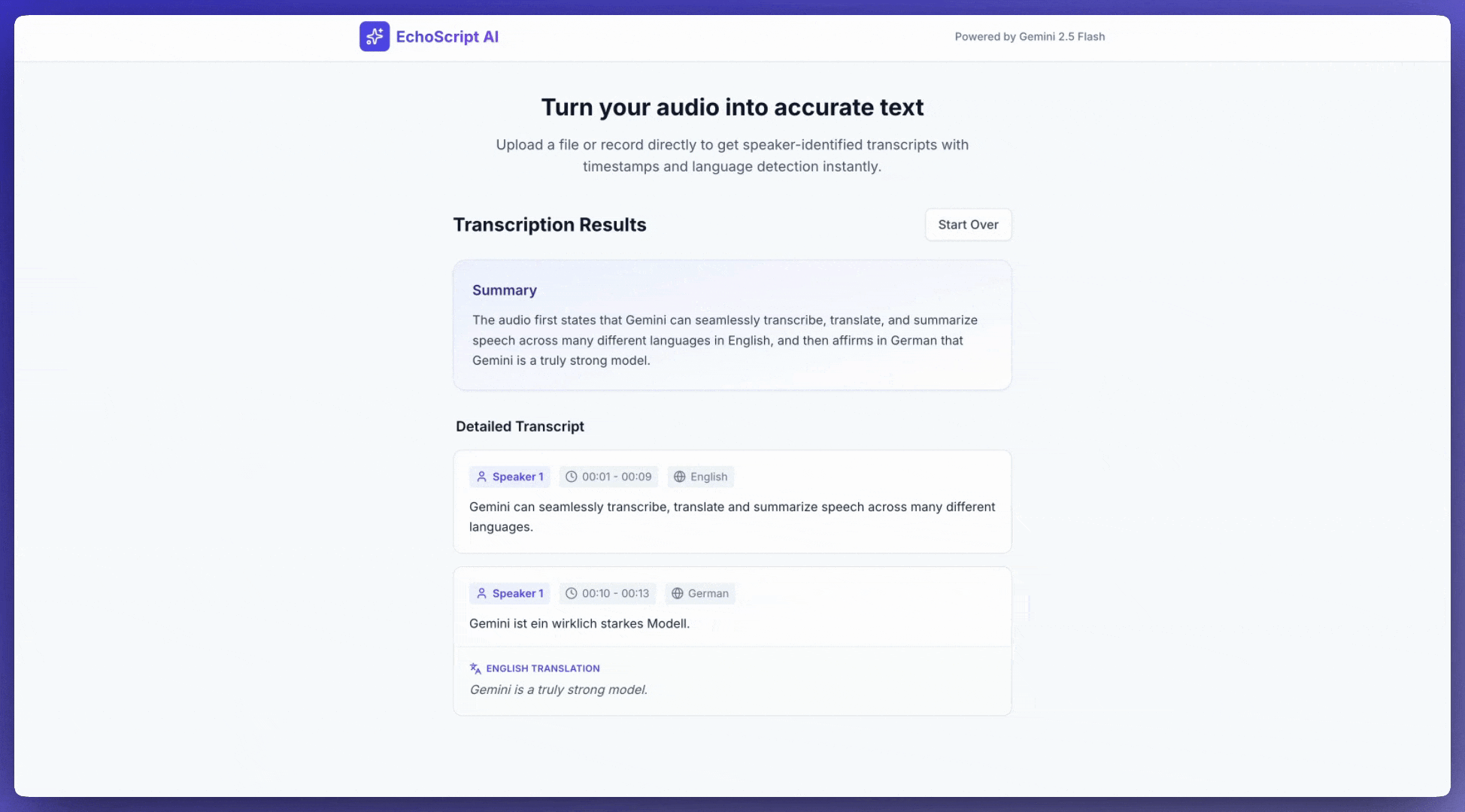
Audio d'entrée
Vous pouvez fournir des données audio à Gemini de plusieurs manières :
- Importez un fichier audio avant d'envoyer une requête à
generateContent. - Transmettez des données audio intégrées avec la requête à
generateContent.
Pour en savoir plus sur les autres méthodes d'entrée de fichier, consultez le guide Méthodes d'entrée de fichier.
Importer un fichier audio
Vous pouvez utiliser l'API Files pour importer un fichier audio. Utilisez toujours l'API Files lorsque la taille totale de la requête (y compris les fichiers, le prompt textuel, les instructions système, etc.) est supérieure à 20 Mo.
Le code suivant importe un fichier audio, puis l'utilise dans un appel à generateContent.
Python
from google import genai
client = genai.Client()
myfile = client.files.upload(file="path/to/sample.mp3")
response = client.models.generate_content(
model="gemini-3-flash-preview", contents=["Describe this audio clip", myfile]
)
print(response.text)
JavaScript
import {
GoogleGenAI,
createUserContent,
createPartFromUri,
} from "@google/genai";
const ai = new GoogleGenAI({});
async function main() {
const myfile = await ai.files.upload({
file: "path/to/sample.mp3",
config: { mimeType: "audio/mp3" },
});
const response = await ai.models.generateContent({
model: "gemini-3-flash-preview",
contents: createUserContent([
createPartFromUri(myfile.uri, myfile.mimeType),
"Describe this audio clip",
]),
});
console.log(response.text);
}
await main();
Go
package main
import (
"context"
"fmt"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
localAudioPath := "/path/to/sample.mp3"
uploadedFile, _ := client.Files.UploadFromPath(
ctx,
localAudioPath,
nil,
)
parts := []*genai.Part{
genai.NewPartFromText("Describe this audio clip"),
genai.NewPartFromURI(uploadedFile.URI, uploadedFile.MIMEType),
}
contents := []*genai.Content{
genai.NewContentFromParts(parts, genai.RoleUser),
}
result, _ := client.Models.GenerateContent(
ctx,
"gemini-3-flash-preview",
contents,
nil,
)
fmt.Println(result.Text())
}
REST
AUDIO_PATH="path/to/sample.mp3"
MIME_TYPE=$(file -b --mime-type "${AUDIO_PATH}")
NUM_BYTES=$(wc -c < "${AUDIO_PATH}")
DISPLAY_NAME=AUDIO
tmp_header_file=upload-header.tmp
# Initial resumable request defining metadata.
# The upload url is in the response headers dump them to a file.
curl "https://generativelanguage.googleapis.com/upload/v1beta/files" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-D upload-header.tmp \
-H "X-Goog-Upload-Protocol: resumable" \
-H "X-Goog-Upload-Command: start" \
-H "X-Goog-Upload-Header-Content-Length: ${NUM_BYTES}" \
-H "X-Goog-Upload-Header-Content-Type: ${MIME_TYPE}" \
-H "Content-Type: application/json" \
-d "{'file': {'display_name': '${DISPLAY_NAME}'}}" 2> /dev/null
upload_url=$(grep -i "x-goog-upload-url: " "${tmp_header_file}" | cut -d" " -f2 | tr -d "\r")
rm "${tmp_header_file}"
# Upload the actual bytes.
curl "${upload_url}" \
-H "Content-Length: ${NUM_BYTES}" \
-H "X-Goog-Upload-Offset: 0" \
-H "X-Goog-Upload-Command: upload, finalize" \
--data-binary "@${AUDIO_PATH}" 2> /dev/null > file_info.json
file_uri=$(jq ".file.uri" file_info.json)
echo file_uri=$file_uri
# Now generate content using that file
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-flash-preview:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"contents": [{
"parts":[
{"text": "Describe this audio clip"},
{"file_data":{"mime_type": "${MIME_TYPE}", "file_uri": '$file_uri'}}]
}]
}' 2> /dev/null > response.json
cat response.json
echo
jq ".candidates[].content.parts[].text" response.json
Pour en savoir plus sur l'utilisation des fichiers multimédias, consultez API Files.
Transmettre des données audio intégrées
Au lieu d'importer un fichier audio, vous pouvez transmettre des données audio intégrées dans la requête à generateContent :
Python
from google import genai
from google.genai import types
with open('path/to/small-sample.mp3', 'rb') as f:
audio_bytes = f.read()
client = genai.Client()
response = client.models.generate_content(
model='gemini-3-flash-preview',
contents=[
'Describe this audio clip',
types.Part.from_bytes(
data=audio_bytes,
mime_type='audio/mp3',
)
]
)
print(response.text)
JavaScript
import { GoogleGenAI } from "@google/genai";
import * as fs from "node:fs";
const ai = new GoogleGenAI({});
const base64AudioFile = fs.readFileSync("path/to/small-sample.mp3", {
encoding: "base64",
});
const contents = [
{ text: "Please summarize the audio." },
{
inlineData: {
mimeType: "audio/mp3",
data: base64AudioFile,
},
},
];
const response = await ai.models.generateContent({
model: "gemini-3-flash-preview",
contents: contents,
});
console.log(response.text);
Go
package main
import (
"context"
"fmt"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
audioBytes, _ := os.ReadFile("/path/to/small-sample.mp3")
parts := []*genai.Part{
genai.NewPartFromText("Describe this audio clip"),
&genai.Part{
InlineData: &genai.Blob{
MIMEType: "audio/mp3",
Data: audioBytes,
},
},
}
contents := []*genai.Content{
genai.NewContentFromParts(parts, genai.RoleUser),
}
result, _ := client.Models.GenerateContent(
ctx,
"gemini-3-flash-preview",
contents,
nil,
)
fmt.Println(result.Text())
}
Voici quelques points à retenir concernant les données audio intégrées :
- La taille maximale de la requête est de 20 Mo, ce qui inclut les prompts textuels, les instructions système et les fichiers fournis de manière intégrée. Si la taille de votre fichier dépasse la taille totale de la requête de 20 Mo, alors utilisez l'API Files pour importer un fichier audio à utiliser dans la requête.
- Si vous utilisez un échantillon audio plusieurs fois, il est plus efficace de télécharger un fichier audio.
Obtenir une transcription
Pour obtenir une transcription des données audio, il vous suffit de la demander dans le prompt :
Python
from google import genai
client = genai.Client()
myfile = client.files.upload(file='path/to/sample.mp3')
prompt = 'Generate a transcript of the speech.'
response = client.models.generate_content(
model='gemini-3-flash-preview',
contents=[prompt, myfile]
)
print(response.text)
JavaScript
import {
GoogleGenAI,
createUserContent,
createPartFromUri,
} from "@google/genai";
const ai = new GoogleGenAI({});
const myfile = await ai.files.upload({
file: "path/to/sample.mp3",
config: { mimeType: "audio/mpeg" },
});
const result = await ai.models.generateContent({
model: "gemini-3-flash-preview",
contents: createUserContent([
createPartFromUri(myfile.uri, myfile.mimeType),
"Generate a transcript of the speech.",
]),
});
console.log("result.text=", result.text);
Go
package main
import (
"context"
"fmt"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
localAudioPath := "/path/to/sample.mp3"
uploadedFile, _ := client.Files.UploadFromPath(
ctx,
localAudioPath,
nil,
)
parts := []*genai.Part{
genai.NewPartFromText("Generate a transcript of the speech."),
genai.NewPartFromURI(uploadedFile.URI, uploadedFile.MIMEType),
}
contents := []*genai.Content{
genai.NewContentFromParts(parts, genai.RoleUser),
}
result, _ := client.Models.GenerateContent(
ctx,
"gemini-3-flash-preview",
contents,
nil,
)
fmt.Println(result.Text())
}
Faire référence à des horodatages
Vous pouvez faire référence à des sections spécifiques d'un fichier audio à l'aide d'horodatages au format MM:SS. Par exemple, le prompt suivant demande une transcription qui
- commence à 2 minutes et 30 secondes à partir du début du fichier ;
se termine à 3 minutes et 29 secondes à partir du début du fichier.
Python
# Create a prompt containing timestamps.
prompt = "Provide a transcript of the speech from 02:30 to 03:29."
JavaScript
// Create a prompt containing timestamps.
const prompt = "Provide a transcript of the speech from 02:30 to 03:29."
Go
package main
import (
"context"
"fmt"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
localAudioPath := "/path/to/sample.mp3"
uploadedFile, _ := client.Files.UploadFromPath(
ctx,
localAudioPath,
nil,
)
parts := []*genai.Part{
genai.NewPartFromText("Provide a transcript of the speech " +
"between the timestamps 02:30 and 03:29."),
genai.NewPartFromURI(uploadedFile.URI, uploadedFile.MIMEType),
}
contents := []*genai.Content{
genai.NewContentFromParts(parts, genai.RoleUser),
}
result, _ := client.Models.GenerateContent(
ctx,
"gemini-3-flash-preview",
contents,
nil,
)
fmt.Println(result.Text())
}
Compter les jetons
Appelez la méthode countTokens pour obtenir le nombre de jetons dans un fichier audio. Exemple :
Python
from google import genai
client = genai.Client()
response = client.models.count_tokens(
model='gemini-3-flash-preview',
contents=[myfile]
)
print(response)
JavaScript
import {
GoogleGenAI,
createUserContent,
createPartFromUri,
} from "@google/genai";
const ai = new GoogleGenAI({});
const myfile = await ai.files.upload({
file: "path/to/sample.mp3",
config: { mimeType: "audio/mpeg" },
});
const countTokensResponse = await ai.models.countTokens({
model: "gemini-3-flash-preview",
contents: createUserContent([
createPartFromUri(myfile.uri, myfile.mimeType),
]),
});
console.log(countTokensResponse.totalTokens);
Go
package main
import (
"context"
"fmt"
"os"
"google.golang.org/genai"
)
func main() {
ctx := context.Background()
client, err := genai.NewClient(ctx, nil)
if err != nil {
log.Fatal(err)
}
localAudioPath := "/path/to/sample.mp3"
uploadedFile, _ := client.Files.UploadFromPath(
ctx,
localAudioPath,
nil,
)
parts := []*genai.Part{
genai.NewPartFromURI(uploadedFile.URI, uploadedFile.MIMEType),
}
contents := []*genai.Content{
genai.NewContentFromParts(parts, genai.RoleUser),
}
tokens, _ := client.Models.CountTokens(
ctx,
"gemini-3-flash-preview",
contents,
nil,
)
fmt.Printf("File %s is %d tokens\n", localAudioPath, tokens.TotalTokens)
}
Formats audio acceptés
Gemini est compatible avec les types MIME de format audio suivants :
- WAV :
audio/wav - MP3 :
audio/mp3 - AIFF :
audio/aiff - AAC :
audio/aac - OGG Vorbis :
audio/ogg - FLAC :
audio/flac
Détails techniques sur l'audio
- Gemini représente chaque seconde d'audio par 32 jetons. Par exemple, une minute d'audio est représentée par 1 920 jetons.
- Gemini peut "comprendre" les composants non vocaux, tels que le chant des oiseaux ou les sirènes.
- La durée maximale acceptée pour les données audio dans un seul prompt est de 9,5 heures. Gemini ne limite pas le nombre de fichiers audio dans un seul prompt.Toutefois, la durée totale combinée de tous les fichiers audio dans un seul prompt ne peut pas dépasser 9,5 heures.
- Gemini sous-échantillonne les fichiers audio à une résolution de données de 16 kbit/s.
- Si la source audio contient plusieurs canaux, Gemini les combine en un seul canal.
Étape suivante
Ce guide explique comment générer du texte en réponse à des données audio. Pour en savoir plus, consultez les ressources suivantes :
- Stratégies de prompt de fichier : l' API Gemini est compatible avec les prompts contenant des données textuelles, d'image, audio et vidéo, également appelés prompts multimodaux.
- Instructions système : les instructions système vous permettent d'orienter le comportement du modèle en fonction de vos besoins et de vos cas d'utilisation spécifiques.
- Conseils de sécurité : les modèles d'IA générative produisent parfois des résultats inattendus, tels que des résultats inexacts, biaisés ou choquants. Le post-traitement et l'évaluation humaine sont essentiels pour limiter le risque de préjudice lié à ces résultats.