
7 listopada 2024 r.
Zwiększanie możliwości asystentów AI do kodowania dzięki długiemu kontekstowi modeli Gemini

Jednym z najbardziej obiecujących obszarów zastosowań długich okien kontekstu jest generowanie i rozumienie kodu. Duże bazy kodu wymagają dogłębnego zrozumienia złożonych relacji i zależności, co jest trudne dla tradycyjnych modeli AI. Zwiększając ilość kodu w dużych oknach kontekstowych, możemy osiągnąć nowy poziom dokładności i użyteczności w generowaniu i rozumieniu kodu.
Współpracowaliśmy z firmą Sourcegraph, twórcą asystenta kodowania Cody AI, który obsługuje duże modele językowe, takie jak Gemini 1.5 Pro i Flash, aby zbadać potencjał długich okien kontekstu w rzeczywistych scenariuszach kodowania. Firma Sourcegraph skupia się na integracji wyszukiwania i analizy kodu z generowaniem kodu przez AI. Wdrożyła też z sukcesem narzędzie Cody w przedsiębiorstwach z dużymi i złożonymi bazami kodu, takich jak Palo Alto Networks i Leidos. To sprawiło, że stała się idealnym partnerem do przeprowadzenia tych badań.
Podejście i wyniki Sourcegraph
Firma Sourcegraph porównała wydajność Cody z oknem kontekstu o milionie tokenów (z użyciem modelu Gemini 1.5 Flash od Google) z wersją produkcyjną. To bezpośrednie porównanie pozwoliło im wyodrębnić korzyści wynikające z rozszerzonego kontekstu. Skupili się na odpowiadaniu na pytania techniczne, co jest kluczowym zadaniem dla programistów pracujących z dużymi bazami kodu. Użyli zbioru danych zawierającego trudne pytania, które wymagały dogłębnego zrozumienia kodu.
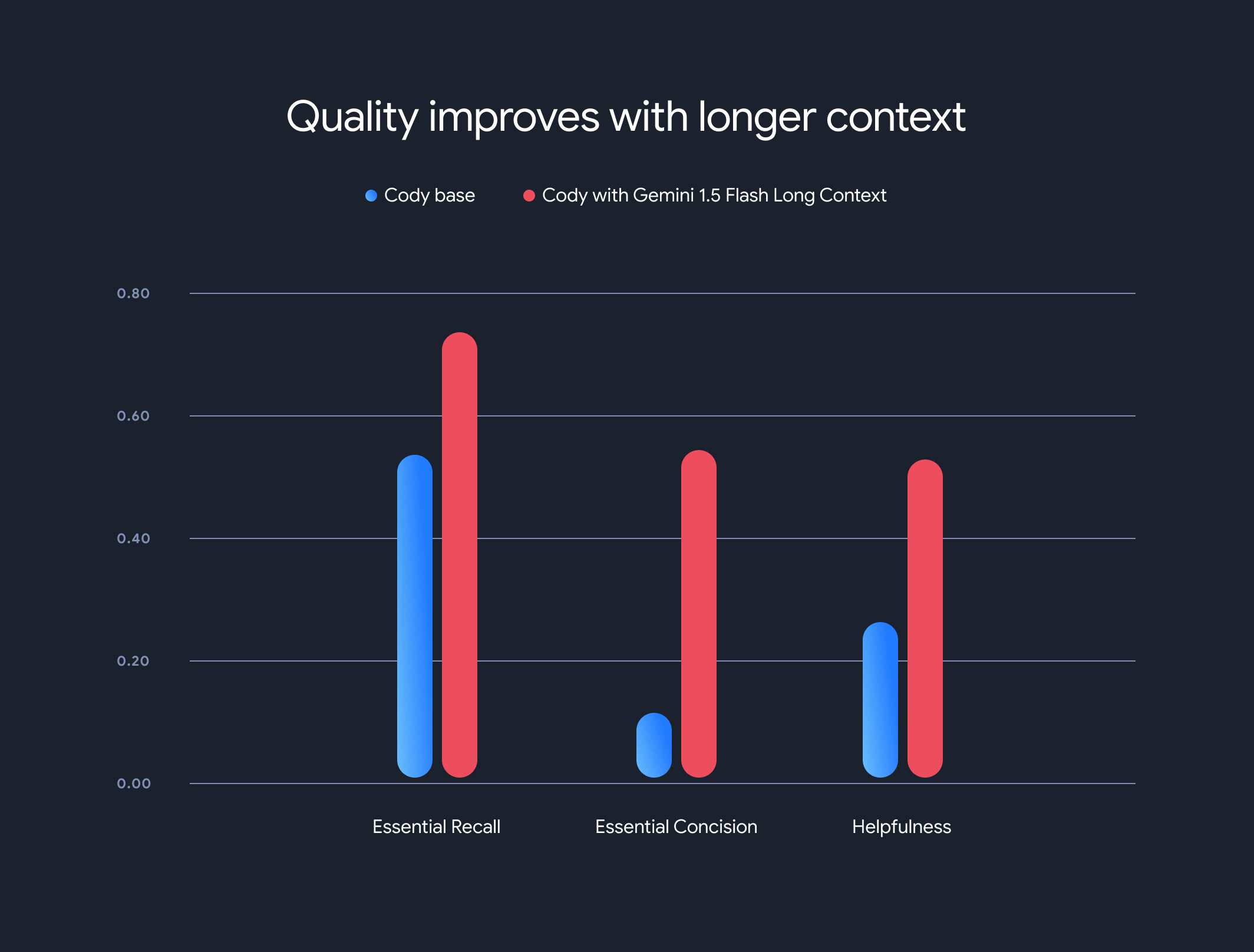
Wyniki były zaskakujące. Trzy kluczowe wskaźniki Sourcegraph – Essential Recall, Essential Concision i Helpfulness – wykazały znaczną poprawę w przypadku użycia dłuższego kontekstu.
Essential Recall: odsetek kluczowych faktów w odpowiedzi znacznie wzrósł.
Istotna zwięzłość: poprawił się też odsetek istotnych faktów znormalizowany przez długość odpowiedzi, co wskazuje na bardziej zwięzłe i trafne odpowiedzi.
Pomocność: ogólny wynik pomocności, znormalizowany pod względem długości odpowiedzi, znacznie wzrósł, co wskazuje na większą przyjazność dla użytkownika.
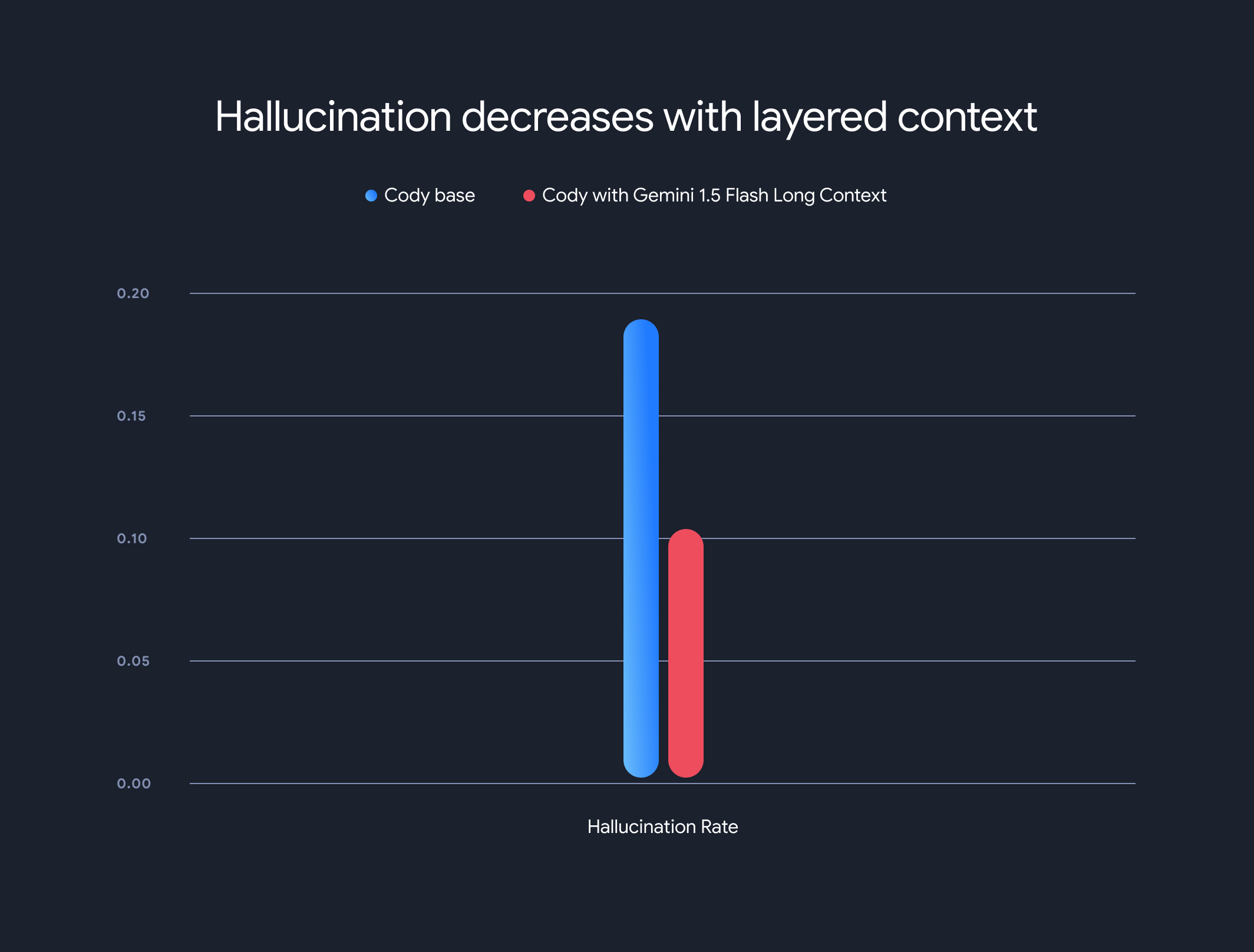
Dodatkowo użycie modeli z długim kontekstem znacznie zmniejszyło ogólny odsetek halucynacji (generowania nieprawdziwych informacji). Odsetek halucynacji spadł z 18,97% do 10,48%, co oznacza znaczną poprawę dokładności i wiarygodności.
Kompromisy i kierunek rozwoju
Długi kontekst ma wiele zalet, ale wiąże się też z pewnymi kompromisami. Czas do pierwszego tokena rośnie liniowo wraz z długością kontekstu. Aby temu zapobiec, Sourcegraph wdrożył mechanizm wstępnego pobierania i architekturę warstwowego modelu kontekstu do buforowania stanu wykonywania modelu. W przypadku modeli Gemini 1.5 Flash i Pro z długim kontekstem zoptymalizowaliśmy czas do pierwszego tokena z 30–40 sekund do około 5 sekund w przypadku kontekstów o rozmiarze 1 MB. To znaczne ulepszenie w zakresie generowania kodu w czasie rzeczywistym i pomocy technicznej.
Ta współpraca pokazuje potencjał modeli długiego kontekstu w rewolucjonizowaniu rozumienia i generowania kodu. Cieszymy się, że możemy współpracować z firmami takimi jak Sourcegraph, aby nadal udostępniać jeszcze bardziej innowacyjne aplikacje i paradygmaty z dużymi oknami kontekstu.
Aby dowiedzieć się więcej o szczegółowych metodach oceny, testach porównawczych i analizach Sourcegraph, w tym o przykładach, przeczytaj szczegółowy post na blogu.
Powiązane studia przypadków

AgentOps
Dowiedz się, jak AgentOps zapewnia opłacalną i skuteczną dostrzegalność agentów opartych na LLM dla firm korzystających z interfejsu Gemini API.

Podwarstwa
Dowiedz się, jak platforma agentów AI oparta na języku Ruby zwiększa produktywność zespołów programistów dzięki możliwościom modeli Gemini.

Pokoje
Odblokowywanie bogatszych interakcji z avatarami dzięki funkcjom tekstowym i audio Gemini 2.0