2025 年 4 月 9 日
在 Langbase 上使用 Gemini Flash 构建高吞吐量、低成本的 AI 智能体

构建能够自主管理其运营和外部工具的 AI 代理通常需要克服集成和基础设施方面的障碍。Langbase 消除了管理这些底层复杂性的负担,提供了一个平台来创建和部署由 Gemini 等模型提供支持的无服务器 AI 智能体,而无需框架。
自 Gemini Flash 发布以来,Langbase 用户很快就意识到使用这些轻量级模型来打造智能体体验在性能和成本方面的优势。
利用 Gemini Flash 实现可伸缩性并加快 AI 智能体的运行速度
Langbase 平台通过 Gemini API 提供对 Gemini 模型的访问权限,让用户可以选择能够处理复杂任务和海量数据的快速模型。低延迟对于提供顺畅的实时体验至关重要,因此 Gemini Flash 模型系列特别适合用于构建面向用户的智能体。
除了响应速度提升 28% 之外,平台用户在使用 Gemini 1.5 Flash 时,运营成本降低了 50%,吞吐量提高了 78%。Gemini Flash 模型能够处理大量请求,同时不会影响性能,因此是高需求应用的理想选择,可用于社交媒体内容创作、研究论文总结和医疗文档主动分析等用例。
31.1 个词元/秒
与同类模型相比,Flash 的吞吐量高出 78%
7.8 倍
Flash 与同类模型相比,上下文窗口更大
28%
与同类模型相比,Flash 的响应速度更快
50%
与同类型号相比,Flash 可降低成本
- 来源:Langbase 博客
Langbase 如何简化智能体开发
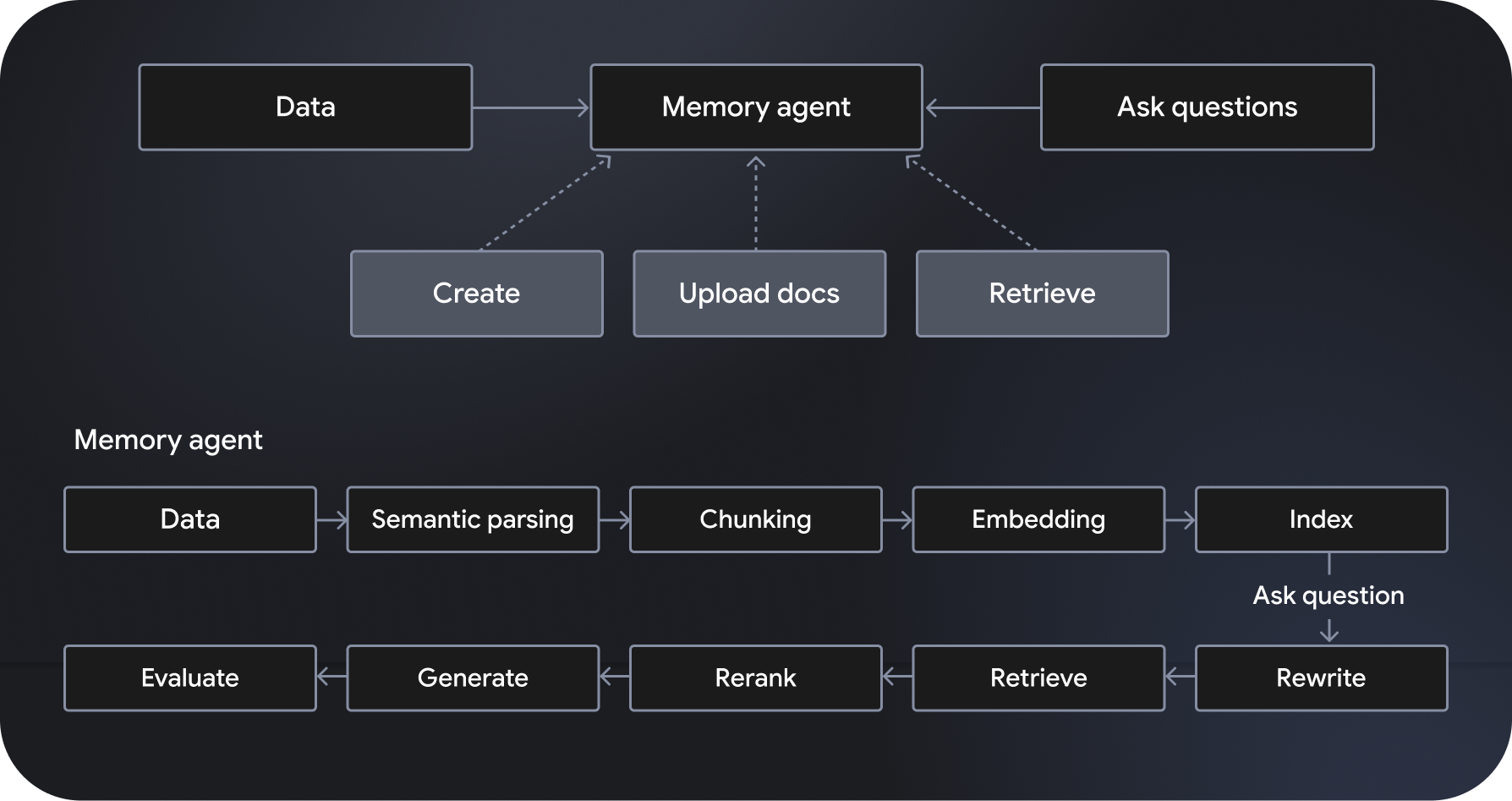
Langbase 是一个无服务器的可组合 AI 智能体开发和部署平台,可用于创建无服务器 AI 智能体。它提供全托管式可扩缩语义检索增强生成 (RAG) 系统,称为“记忆代理”。其他功能包括工作流编排、数据管理、用户互动处理以及与外部服务的集成。
“管道代理”由 Gemini 2.0 Flash 等模型提供支持,遵循并执行指定指令,并可访问强大的工具,包括网页搜索和网页抓取。另一方面,记忆型代理会动态访问相关数据,以生成有事实依据的回答。借助 Langbase 的 Pipe 和 Memory API,开发者可以将强大的推理能力与新的数据源相关联,从而构建强大的功能,扩展 AI 模型的知识和实用性。