
Gemma 3n — это генеративная модель ИИ, оптимизированная для использования в повседневных устройствах, таких как телефоны, ноутбуки и планшеты. Эта модель включает инновации в обработке с эффективными параметрами, включая кэширование параметров Per-Layer Embedding (PLE) и архитектуру модели MatFormer, которая обеспечивает гибкость для снижения требований к вычислениям и памяти. Эти модели включают обработку аудиовхода, а также текстовых и визуальных данных.
Gemma 3n включает в себя следующие основные функции:
- Аудиовход : Обработка звуковых данных для распознавания речи, перевода и анализа аудиоданных. Узнать больше
- Визуальный и текстовый ввод : Мультимодальные возможности позволяют вам обрабатывать зрение, звук и текст, чтобы помочь вам понимать и анализировать мир вокруг вас. Узнать больше
- Кодер Vision: Высокопроизводительный кодер MobileNet-V5 существенно повышает скорость и точность обработки визуальных данных. Узнать больше
- Кэширование PLE : параметры встраивания по слоям (PLE), содержащиеся в этих моделях, могут кэшироваться в быстром локальном хранилище для снижения затрат на запуск памяти модели. Узнать больше
- Архитектура MatFormer: Архитектура Matryoshka Transformer позволяет выборочно активировать параметры моделей по запросу, чтобы сократить затраты на вычисления и время отклика. Узнать больше
- Условная загрузка параметров: Обход загрузки параметров зрения и звука в модели для уменьшения общего количества загружаемых параметров и экономии ресурсов памяти. Узнать больше
- Широкая языковая поддержка : Широкие лингвистические возможности, обучение более чем на 140 языках.
- Контекст токенов 32K : существенный входной контекст для анализа данных и выполнения задач обработки.
Попробуйте Gemma 3n Получите его на Kaggle Получите его на Hugging Face
Как и другие модели Gemma, Gemma 3n поставляется с открытыми весами и лицензирована для ответственного коммерческого использования , что позволяет вам настраивать и использовать ее в собственных проектах и приложениях.
Параметры модели и эффективные параметры
Модели Gemma 3n перечислены с количеством параметров, например E2B и E4B , которое меньше общего количества параметров, содержащихся в моделях. Префикс E указывает на то, что эти модели могут работать с сокращенным набором эффективных параметров. Эта работа с сокращенными параметрами может быть достигнута с помощью гибкой технологии параметров, встроенной в модели Gemma 3n, чтобы помочь им эффективно работать на устройствах с меньшими ресурсами.
Параметры в моделях Gemma 3n делятся на 4 основные группы: текстовые, визуальные, аудио и параметры встраивания на уровне слоя (PLE). При стандартном выполнении модели E2B при выполнении модели загружается более 5 миллиардов параметров. Однако, используя пропуск параметров и методы кэширования PLE, эта модель может работать с эффективной загрузкой памяти чуть менее 2 миллиардов (1,91 Б) параметров, как показано на рисунке 1.
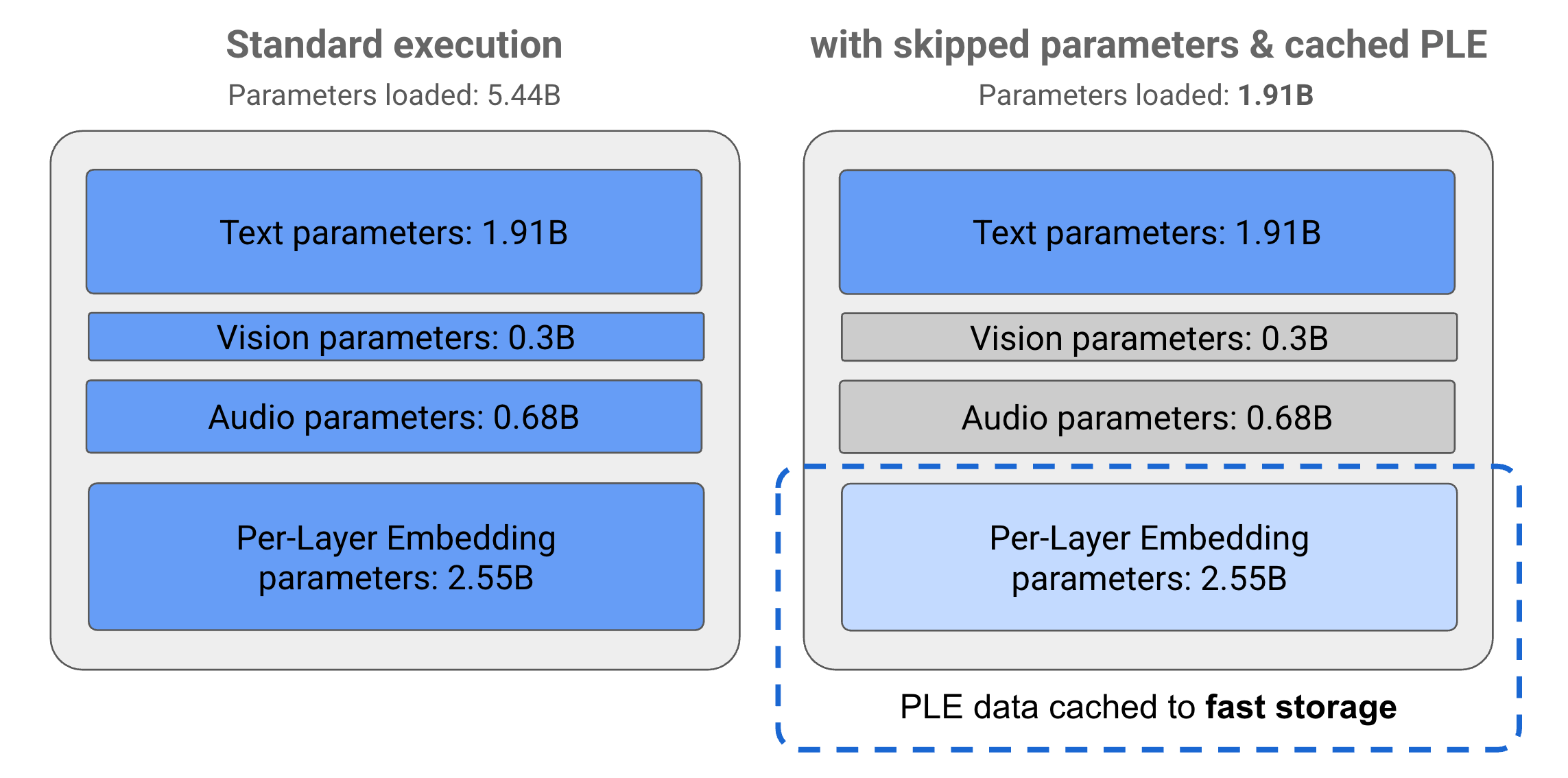
Рисунок 1. Параметры модели Gemma 3n E2B, работающие в стандартном исполнении по сравнению с эффективно более низкой нагрузкой параметров с использованием кэширования PLE и методов пропуска параметров.
Используя эти методы разгрузки параметров и выборочной активации, вы можете запустить модель с очень скудным набором параметров или активировать дополнительные параметры для обработки других типов данных, таких как визуальные и аудио. Эти функции позволяют вам наращивать функциональность модели или сворачивать возможности на основе возможностей устройства или требований задачи. В следующих разделах более подробно описываются эффективные методы параметров, доступные в моделях Gemma 3n.
Кэширование PLE
Модели Gemma 3n включают параметры Per-Layer Embedding (PLE), которые используются во время выполнения модели для создания данных, которые повышают производительность каждого слоя модели. Данные PLE могут быть сгенерированы отдельно, вне оперативной памяти модели, кэшированы в быстром хранилище, а затем добавлены в процесс вывода модели по мере выполнения каждого слоя. Такой подход позволяет хранить параметры PLE вне пространства памяти модели, что снижает потребление ресурсов и при этом улучшает качество отклика модели.
Архитектура MatFormer
Модели Gemma 3n используют архитектуру модели Matryoshka Transformer или MatFormer , которая содержит вложенные, меньшие модели внутри одной, большей модели. Вложенные подмодели можно использовать для выводов без активации параметров вложенных моделей при ответе на запросы. Эта возможность запускать только меньшие, основные модели в модели MatFormer может снизить стоимость вычислений, время отклика и энергопотребление модели. В случае Gemma 3n модель E4B содержит параметры модели E2B. Эта архитектура также позволяет выбирать параметры и собирать модели в промежуточных размерах между 2B и 4B. Более подробную информацию об этом подходе см. в исследовательской статье MatFormer . Попробуйте использовать методы MatFormer для уменьшения размера модели Gemma 3n с помощью руководства MatFormer Lab .
Условная загрузка параметров
Подобно параметрам PLE, вы можете пропустить загрузку некоторых параметров в память, таких как аудио- или визуальные параметры, в модели Gemma 3n, чтобы уменьшить нагрузку на память. Эти параметры могут быть динамически загружены во время выполнения, если устройство имеет необходимые ресурсы. В целом, пропуск параметров может дополнительно сократить требуемую оперативную память для модели Gemma 3n, позволяя выполнять ее на более широком диапазоне устройств и позволяя разработчикам повысить эффективность использования ресурсов для менее требовательных задач.
Готовы начать строить? Начните с моделей Gemma!