
Gemma 3n est un modèle d'IA générative optimisé pour les appareils du quotidien, tels que les téléphones, les ordinateurs portables et les tablettes. Ce modèle inclut des innovations en matière de traitement efficace des paramètres, y compris le stockage en cache des paramètres PLE (Per-Layer Embedding) et une architecture de modèle MatFormer qui offre la flexibilité nécessaire pour réduire les exigences en termes de calcul et de mémoire. Ces modèles incluent la gestion des entrées audio, ainsi que des données textuelles et visuelles.
Gemma 3n inclut les principales fonctionnalités suivantes :
- Entrée audio : permet de traiter les données audio pour la reconnaissance vocale, la traduction et l'analyse des données audio. En savoir plus
- Saisie visuelle et textuelle : les fonctionnalités multimodales vous permettent de gérer la vision, le son et le texte pour vous aider à comprendre et à analyser le monde qui vous entoure. En savoir plus
- Encodage de vision : l'encodeur MobileNet-V5 hautes performances améliore considérablement la vitesse et la précision du traitement des données visuelles. En savoir plus
- Mise en cache PLE : les paramètres PLE (Per-Layer Embedding) contenus dans ces modèles peuvent être mis en cache dans un stockage local rapide afin de réduire les coûts d'exécution de la mémoire du modèle. En savoir plus
- Architecture MatFormer : l'architecture Matryoshka Transformer permet d'activer de manière sélective les paramètres des modèles par requête afin de réduire les coûts de calcul et les temps de réponse. En savoir plus
- Chargement de paramètres conditionnel : contournez le chargement des paramètres de vision et audio dans le modèle pour réduire le nombre total de paramètres chargés et économiser des ressources de mémoire. En savoir plus
- Compatibilité avec de nombreuses langues : capacités linguistiques étendues, entraînées dans plus de 140 langues.
- Contexte de jeton 32 000 : contexte d'entrée important pour analyser les données et gérer les tâches de traitement.
Essayer Gemma 3n Obtenir Gemma sur Kaggle Obtenir Gemma sur Hugging Face
Comme pour les autres modèles Gemma, Gemma 3n est fourni avec des poids ouverts et sous licence pour une utilisation commerciale responsable, ce qui vous permet de l'ajuster et de le déployer dans vos propres projets et applications.
Paramètres de modèle et paramètres efficaces
Les modèles Gemma 3n sont listés avec des nombres de paramètres, tels que E2B et E4B, qui sont inférieurs au nombre total de paramètres contenus dans les modèles. Le préfixe E indique que ces modèles peuvent fonctionner avec un ensemble réduit de paramètres efficaces. Cette réduction du nombre de paramètres peut être obtenue à l'aide de la technologie de paramètres flexibles intégrée aux modèles Gemma 3n pour les aider à fonctionner efficacement sur des appareils à ressources limitées.
Les paramètres des modèles Gemma 3n sont divisés en quatre groupes principaux : les paramètres de texte, visuel, audio et d'encapsulation par couche (PLE, per-layer embedding). Lors de l'exécution standard du modèle E2B, plus de cinq milliards de paramètres sont chargés. Toutefois, en utilisant les techniques de saut de paramètres et de mise en cache PLE, ce modèle peut être exploité avec une charge de mémoire efficace d'un peu moins de deux milliards (1,91 milliards) de paramètres, comme illustré à la figure 1.
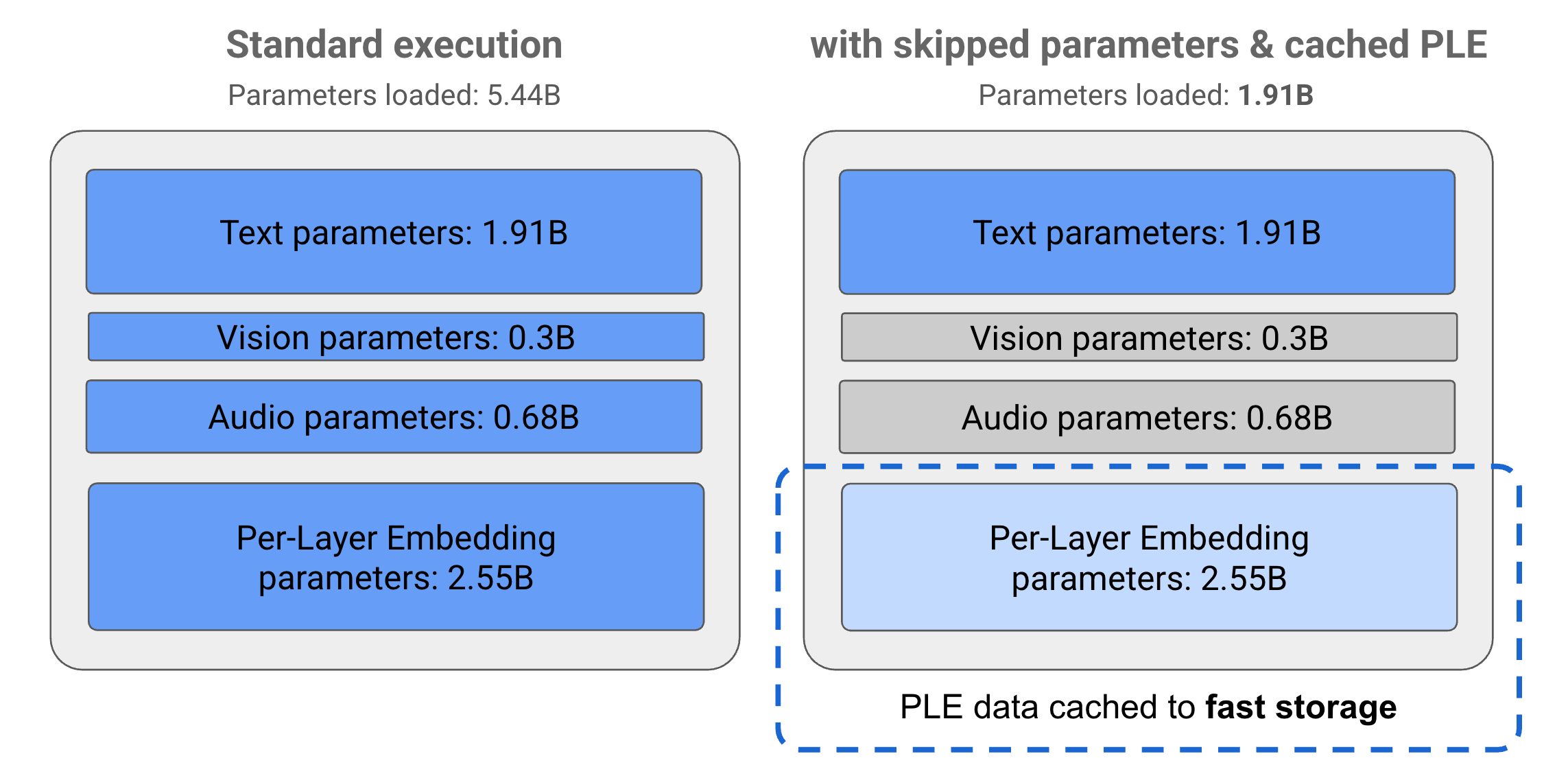
Figure 1. Paramètres du modèle Gemma 3n E2B exécutés en exécution standard par rapport à une charge de paramètres effectivement inférieure à l'aide de techniques de mise en cache PLE et de saut de paramètres.
Grâce à ces techniques d'externalisation de paramètres et d'activation sélective, vous pouvez exécuter le modèle avec un ensemble très restreint de paramètres ou activer des paramètres supplémentaires pour gérer d'autres types de données, tels que les visuels et les audios. Ces fonctionnalités vous permettent d'augmenter ou de réduire les fonctionnalités du modèle en fonction des fonctionnalités de l'appareil ou des exigences de la tâche. Les sections suivantes expliquent plus en détail les techniques d'efficacité des paramètres disponibles dans les modèles Gemma 3n.
Mise en cache PLE
Les modèles Gemma 3n incluent des paramètres d'embedding par couche (PLE) qui sont utilisés lors de l'exécution du modèle pour créer des données qui améliorent les performances de chaque couche du modèle. Les données PLE peuvent être générées séparément, en dehors de la mémoire de fonctionnement du modèle, mises en cache dans un stockage rapide, puis ajoutées au processus d'inférence du modèle à mesure que chaque couche s'exécute. Cette approche permet de ne pas inclure les paramètres PLE dans l'espace mémoire du modèle, ce qui réduit la consommation de ressources tout en améliorant la qualité des réponses du modèle.
Architecture MatFormer
Les modèles Gemma 3n utilisent une architecture de modèle Matryoshka Transformer ou MatFormer qui contient des modèles plus petits imbriqués dans un seul modèle plus grand. Les sous-modèles imbriqués peuvent être utilisés pour les inférences sans activer les paramètres des modèles englobants lors de la réponse aux requêtes. Cette capacité à exécuter uniquement les modèles de base plus petits dans un modèle MatFormer peut réduire les coûts de calcul, le temps de réponse et l'empreinte énergétique du modèle. Dans le cas de Gemma 3n, le modèle E4B contient les paramètres du modèle E2B. Cette architecture vous permet également de sélectionner des paramètres et d'assembler des modèles de tailles intermédiaires entre 2 et 4 milliards. Pour en savoir plus sur cette approche, consultez le rapport de recherche sur MatFormer. Essayez d'utiliser des techniques MatFormer pour réduire la taille d'un modèle Gemma 3n avec le guide MatFormer Lab.
Chargement conditionnel des paramètres
Comme pour les paramètres PLE, vous pouvez ignorer le chargement de certains paramètres en mémoire, tels que les paramètres audio ou visuels, dans le modèle Gemma 3n afin de réduire la charge de mémoire. Ces paramètres peuvent être chargés dynamiquement au moment de l'exécution si l'appareil dispose des ressources requises. Globalement, le saut de paramètres peut réduire davantage la mémoire de fonctionnement requise pour un modèle Gemma 3n, ce qui permet d'exécuter le modèle sur un plus grand nombre d'appareils et aux développeurs d'augmenter l'efficacité des ressources pour les tâches moins exigeantes.
Prêt à commencer à créer ?
Commencez à utiliser les modèles Gemma.