
提示设计策略(例如少样本提示)可能并不总能产生您需要的结果。微调是一种流程,可提高模型针对特定任务的效果,或帮助模型在说明不足且您有一系列示例来展示所需输出时符合特定的输出要求。
本页面从概念上简要介绍了如何微调 Gemini API 文本服务背后的文本模型。当您准备好开始调整时,请尝试精细调整教程。如需更全面地了解如何针对特定用例自定义 LLM,请参阅机器学习速成课程中的 LLM:微调、提炼和提示工程。
微调的运作方式
微调的目标是进一步提高模型针对特定任务的效果。微调的工作原理是为模型提供包含许多任务样本的训练数据集。对于特定领域的任务,您可以使用适量样本调优模型,以此来显著改善模型性能。这种模型微调有时也称为监督式微调,以将其与其他类型的微调区分开来。
训练数据应进行结构化处理,以提示输入和预期回答输出为示例。您还可以直接在 Google AI Studio 中使用示例数据来调优模型。目标是通过提供许多展示相应行为或任务的样本来训练模型,让其模拟所需的行为或任务。
运行调整作业时,模型会学习其他参数,以便对所需信息进行编码以执行所需任务或学习预期行为。这些参数随后可在推断时使用。调整作业的输出是新模型,实际上就是新学习的参数和原始模型的组合。
准备数据集
在开始微调之前,您需要一个数据集来调优模型。为了获得最佳性能,数据集中的示例应具有高质量、多样化且具有代表性的真实输入和输出。
格式
数据集中包含的样本应与您的预期生产流量相匹配。如果您的数据集包含特定的格式、关键字、说明或信息,则生产数据应以相同方式设置格式并包含相同的说明。
例如,如果数据集中的样本包含 "question:" 和 "context:",则生产流量的格式也应设置为包含 "question:" 和 "context:",其顺序与在数据集样本中的显示顺序相同。如果排除语境,则模型无法识别该模式,即使确切的问题包含在数据集内的样本中也是如此。
再举一个例子,下面是用于生成序列中下一个数字的应用的 Python 训练数据:
training_data = [
{"text_input": "1", "output": "2"},
{"text_input": "3", "output": "4"},
{"text_input": "-3", "output": "-2"},
{"text_input": "twenty two", "output": "twenty three"},
{"text_input": "two hundred", "output": "two hundred one"},
{"text_input": "ninety nine", "output": "one hundred"},
{"text_input": "8", "output": "9"},
{"text_input": "-98", "output": "-97"},
{"text_input": "1,000", "output": "1,001"},
{"text_input": "10,100,000", "output": "10,100,001"},
{"text_input": "thirteen", "output": "fourteen"},
{"text_input": "eighty", "output": "eighty one"},
{"text_input": "one", "output": "two"},
{"text_input": "three", "output": "four"},
{"text_input": "seven", "output": "eight"},
]
为数据集中的每个示例添加提示或前言也可以帮助提升经过调优的模型的性能。请注意,如果数据集中包含提示或前言,则在推理时,对经过调优的模型的提示中也应包含这些内容。
限制
注意:针对 Gemini 1.5 Flash 微调数据集存在以下限制:
- 每个示例的输入大小上限为 4 万个字符。
- 每个示例的输出大小上限为 5,000 个字符。
训练数据大小
您只需 20 个示例即可微调模型。提供更多数据通常可以提高回答质量。您应以 100 到 500 个示例为目标,具体取决于您的应用。下表显示了针对各种常见任务微调文本模型的建议数据集大小:
| 任务 | 数据集中的示例数 |
|---|---|
| 分类 | 100 多项 |
| 总结 | 100-500+ |
| 文档搜索 | 100 多项 |
上传调整数据集
数据是使用 API 或通过在 Google AI Studio 中上传的文件内嵌传递的。
如需使用该客户端库,请在 createTunedModel 调用中提供数据文件。文件大小上限为 4 MB。如需开始使用,请参阅使用 Python 进行微调的快速入门。
如需使用 c网址 调用 REST API,请向 training_data 参数提供 JSON 格式的训练示例。如需开始使用,请参阅使用 c网址 进行调整的快速入门。
高级调音设置
创建调优作业时,您可以指定以下高级设置:
- 周期:在训练时,整个训练集的一次完整遍历,不会漏掉任何一个样本。
- 批次大小:一次训练迭代中使用的一组示例。批处理大小决定了批处理中的示例数量。
- 学习速率:一个浮点数,用于指示算法在每次迭代中调整模型参数的幅度。例如,与学习率为 0.1 相比,学习率为 0.3 会使权重和偏差的调整力度提高三倍。高学习率和低学习率各有利弊,应根据您的用例进行调整。
- 学习速率调节系数:速率调节系数用于修改模型的原始学习速率。值为 1 表示使用模型的原始学习速率。大于 1 的值会提高学习率,介于 1 和 0 之间的值会降低学习率。
建议的配置
下表显示了对基础模型进行微调的建议配置:
| 超参数 | 默认值 | 建议的调整 |
|---|---|---|
| 周期 | 5 |
如果损失在 5 个 epoch 之前开始趋于稳定,请使用较小的值。 如果损失值正在收敛,并且似乎没有达到平台期,请使用较高的值。 |
| 批次大小 | 4 | |
| 学习速率 | 0.001 | 对于较小的数据集,请使用较小的值。 |
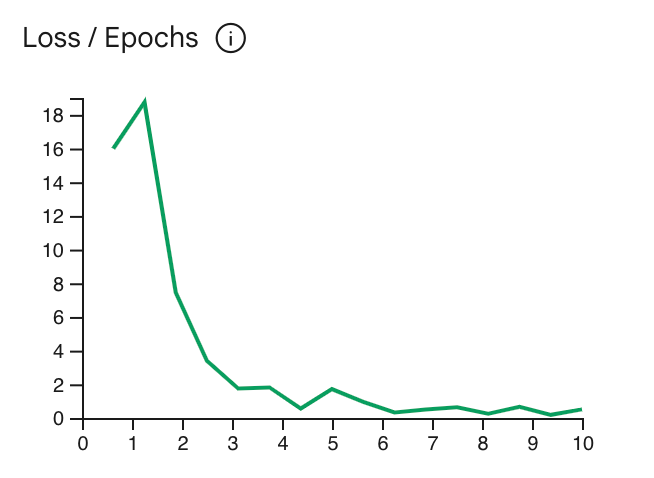
损失曲线显示了在每个训练周期结束后,模型的预测与训练示例中的理想预测的偏差程度。理想情况下,您应在曲线达到平台期之前,在曲线的最低点停止训练。例如,下图显示了损失曲线在第 4-6 个迭代大约达到平台期,这意味着您可以将 Epoch 参数设置为 4,仍然可以获得相同的效果。
检查调整作业的状态
您可以在 Google AI Studio 的 My Library(我的库)标签页中检查调优作业的状态,也可以在 Gemini API 中使用经过调优的模型的 metadata 属性检查调优作业的状态。
排查错误
本部分包含有关如何解决您在创建调优模型时可能遇到的错误的提示。
身份验证
使用 API 和客户端库进行调整需要进行身份验证。您可以使用 API 密钥(推荐)或 OAuth 凭据设置身份验证。如需了解如何设置 API 密钥,请参阅设置 API 密钥。
如果您看到 'PermissionDenied: 403 Request had insufficient authentication
scopes' 错误,则可能需要使用 OAuth 凭据设置用户身份验证。如需为 Python 配置 OAuth 凭据,请参阅我们的 OAuth 设置教程。
已取消的模型
在微调作业完成之前,您可以随时取消该作业。不过,取消的模型的推理性能是不可预测的,尤其是在训练阶段提前取消调优作业时。如果您因为想在较早的迭代中停止训练而取消了作业,则应创建新的调优作业,并将迭代设置为较低的值。
调优型模型的限制
注意:经过优化的模型具有以下限制:
- 经过优化的 Gemini 1.5 Flash 模型的输入限制为 4 万个字符。
- 经过调优的模型不支持 JSON 模式。
- 经过调优的模型不支持系统指令。
- 仅支持文本输入。
后续步骤
请参阅以下微调教程,快速上手: