Gemini 可同時處理各種輸入資料,包括文字、圖片和音訊。
本指南說明如何使用 Files API 處理媒體檔案。音訊檔案、圖片、影片、文件和其他支援的檔案類型,基本操作都相同。
如需檔案提示指南,請參閱「檔案提示指南」一節。
上傳檔案
你可以使用 Files API 上傳媒體檔案。如果要求總大小 (包括檔案、文字提示、系統指令等) 超過 20 MB,請一律使用 Files API。
下列程式碼會上傳檔案,然後在呼叫 generateContent 時使用該檔案。
Python
from google import genai
client = genai.Client()
myfile = client.files.upload(file="path/to/sample.mp3")
response = client.models.generate_content(
model="gemini-2.5-flash", contents=["Describe this audio clip", myfile]
)
print(response.text)
JavaScript
import {
GoogleGenAI,
createUserContent,
createPartFromUri,
} from "@google/genai";
const ai = new GoogleGenAI({});
async function main() {
const myfile = await ai.files.upload({
file: "path/to/sample.mp3",
config: { mimeType: "audio/mpeg" },
});
const response = await ai.models.generateContent({
model: "gemini-2.5-flash",
contents: createUserContent([
createPartFromUri(myfile.uri, myfile.mimeType),
"Describe this audio clip",
]),
});
console.log(response.text);
}
await main();
Go
file, err := client.Files.UploadFromPath(ctx, "path/to/sample.mp3", nil)
if err != nil {
log.Fatal(err)
}
defer client.Files.Delete(ctx, file.Name)
resp, err := client.Models.GenerateContent(ctx, "gemini-2.5-flash", []*genai.Content{
{
Parts: []*genai.Part{
genai.NewPartFromFile(*file),
genai.NewPartFromText("Describe this audio clip"),
},
},
}, nil)
if err != nil {
log.Fatal(err)
}
printResponse(resp)
REST
AUDIO_PATH="path/to/sample.mp3"
MIME_TYPE=$(file -b --mime-type "${AUDIO_PATH}")
NUM_BYTES=$(wc -c < "${AUDIO_PATH}")
DISPLAY_NAME=AUDIO
tmp_header_file=upload-header.tmp
# Initial resumable request defining metadata.
# The upload url is in the response headers dump them to a file.
curl "${BASE_URL}/upload/v1beta/files" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-D "${tmp_header_file}" \
-H "X-Goog-Upload-Protocol: resumable" \
-H "X-Goog-Upload-Command: start" \
-H "X-Goog-Upload-Header-Content-Length: ${NUM_BYTES}" \
-H "X-Goog-Upload-Header-Content-Type: ${MIME_TYPE}" \
-H "Content-Type: application/json" \
-d "{'file': {'display_name': '${DISPLAY_NAME}'}}" 2> /dev/null
upload_url=$(grep -i "x-goog-upload-url: " "${tmp_header_file}" | cut -d" " -f2 | tr -d "\r")
rm "${tmp_header_file}"
# Upload the actual bytes.
curl "${upload_url}" \
-H "Content-Length: ${NUM_BYTES}" \
-H "X-Goog-Upload-Offset: 0" \
-H "X-Goog-Upload-Command: upload, finalize" \
--data-binary "@${AUDIO_PATH}" 2> /dev/null > file_info.json
file_uri=$(jq ".file.uri" file_info.json)
echo file_uri=$file_uri
# Now generate content using that file
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-flash:generateContent" \
-H "x-goog-api-key: $GEMINI_API_KEY" \
-H 'Content-Type: application/json' \
-X POST \
-d '{
"contents": [{
"parts":[
{"text": "Describe this audio clip"},
{"file_data":{"mime_type": "${MIME_TYPE}", "file_uri": '$file_uri'}}]
}]
}' 2> /dev/null > response.json
cat response.json
echo
jq ".candidates[].content.parts[].text" response.json
取得檔案的中繼資料
您可以呼叫 files.get,確認 API 是否已成功儲存上傳的檔案並取得其中繼資料。
Python
from google import genai
client = genai.Client()
myfile = client.files.upload(file='path/to/sample.mp3')
file_name = myfile.name
myfile = client.files.get(name=file_name)
print(myfile)
JavaScript
import {
GoogleGenAI,
} from "@google/genai";
const ai = new GoogleGenAI({});
async function main() {
const myfile = await ai.files.upload({
file: "path/to/sample.mp3",
config: { mimeType: "audio/mpeg" },
});
const fileName = myfile.name;
const fetchedFile = await ai.files.get({ name: fileName });
console.log(fetchedFile);
}
await main();
Go
file, err := client.Files.UploadFromPath(ctx, "path/to/sample.mp3", nil)
if err != nil {
log.Fatal(err)
}
gotFile, err := client.Files.Get(ctx, file.Name)
if err != nil {
log.Fatal(err)
}
fmt.Println("Got file:", gotFile.Name)
REST
# file_info.json was created in the upload example
name=$(jq ".file.name" file_info.json)
# Get the file of interest to check state
curl https://generativelanguage.googleapis.com/v1beta/files/$name \
-H "x-goog-api-key: $GEMINI_API_KEY" > file_info.json
# Print some information about the file you got
name=$(jq ".file.name" file_info.json)
echo name=$name
file_uri=$(jq ".file.uri" file_info.json)
echo file_uri=$file_uri
列出上傳的檔案
下列程式碼會取得所有已上傳檔案的清單:
Python
from google import genai
client = genai.Client()
print('My files:')
for f in client.files.list():
print(' ', f.name)
JavaScript
import {
GoogleGenAI,
} from "@google/genai";
const ai = new GoogleGenAI({});
async function main() {
const listResponse = await ai.files.list({ config: { pageSize: 10 } });
for await (const file of listResponse) {
console.log(file.name);
}
}
await main();
Go
for file, err := range client.Files.All(ctx) {
if err != nil {
log.Fatal(err)
}
fmt.Println(file.Name)
}
REST
echo "My files: "
curl "https://generativelanguage.googleapis.com/v1beta/files" \
-H "x-goog-api-key: $GEMINI_API_KEY"
刪除上傳的檔案
檔案會在 48 小時後自動刪除。你也可以手動刪除上傳的檔案:
Python
from google import genai
client = genai.Client()
myfile = client.files.upload(file='path/to/sample.mp3')
client.files.delete(name=myfile.name)
JavaScript
import {
GoogleGenAI,
} from "@google/genai";
const ai = new GoogleGenAI({});
async function main() {
const myfile = await ai.files.upload({
file: "path/to/sample.mp3",
config: { mimeType: "audio/mpeg" },
});
const fileName = myfile.name;
await ai.files.delete({ name: fileName });
}
await main();
Go
file, err := client.Files.UploadFromPath(ctx, "path/to/sample.mp3", nil)
if err != nil {
log.Fatal(err)
}
client.Files.Delete(ctx, file.Name)
REST
curl --request "DELETE" https://generativelanguage.googleapis.com/v1beta/files/$name \
-H "x-goog-api-key: $GEMINI_API_KEY"
使用資訊
您可以使用 Files API 上傳媒體檔案並與之互動。透過 Files API,每個專案最多可儲存 20 GB 的檔案,每個檔案的大小上限為 2 GB。檔案會儲存 48 小時。在這段期間,您可以使用 API 取得檔案的中繼資料,但無法下載檔案。在 Gemini API 支援的所有地區,您都可以免費使用 Files API。
檔案提示策略
本節提供指南和最佳做法,說明如何搭配 Gemini API 的提示使用媒體檔案。
提示中可使用的資料類型越多,您就能越靈活地運用 Gemini API 處理各種工作。例如,您可以向模型傳送美味餐點的相片,並請模型撰寫有關該餐點的短篇網誌。
| 提示 | 回應 |
|
根據這張圖片撰寫簡短有趣的網誌文章。並說明相片中的餐點,以及我準備餐點的過程。 
|
事先備餐不僅省時省錢,還能幫助你吃得更健康。這道餐點是健康美味的絕佳範例,而且可以輕鬆提前準備。 這道餐點包含糙米、烤蔬菜和照燒雞肉。 糙米是健康且複雜的碳水化合物,可提供持久的能量。烤蔬菜富含維生素和礦物質,是補充每日營養的好選擇;照燒雞肉則美味可口,且含有豐富的蛋白質。 這道餐點的準備方式也很簡單,只要煮好糙米飯、烤蔬菜,以及照燒雞肉,所有食材煮熟後,請分裝到備餐容器中,然後放入冰箱。這樣就能在忙碌的早晨隨時取用! 如果你想吃健康美味的餐點,而且可以輕鬆提前準備,這道料理就是絕佳選擇。這道料理營養豐富、風味十足,保證能讓您吃得飽足又滿足。 祝你餐點準備順利,吃得健康又美味! |
如果使用媒體檔案的提示無法產生所需輸出內容,可以嘗試一些策略,協助你獲得想要的結果。以下各節提供設計方法和疑難排解提示,協助您改善使用多模態輸入內容的提示。
如要改善多模態提示,請參考下列最佳做法:
-
提示設計基礎知識
- 提供明確的指示:請提供清楚簡潔的指示,盡量避免誤解。
- 在提示中加入幾個範例:使用實際的少樣本範例,說明您想達成的目標。
- 逐步分解:將複雜任務拆解成可管理的小目標,引導模型完成整個程序。
- 指定輸出格式:在提示中要求輸出內容採用所需格式,例如 Markdown、JSON、HTML 等。
- 單一圖片提示請先放圖片:Gemini 可以處理任何順序的圖片和文字輸入內容,但如果提示只含一張圖片,先放圖片 (或影片) 再放文字提示,效果可能會更好。不過,如果提示需要圖片與文字高度交錯才能有意義,請使用最自然的順序。
-
排解多模態提示問題
- 如果模型未從圖片的相關部分提取資訊:請提供提示,說明要從圖片的哪些部分提取資訊。
- 如果模型輸出內容過於一般 (不夠符合輸入的圖片/影片): 在提示開頭,先要求模型描述圖片或影片,再提供工作指令,或要求模型參照圖片內容。
- 如要排解哪個部分發生錯誤:要求模型描述圖片或說明推論過程,藉此評估模型的初步理解程度。
- 如果提示導致模型產生幻覺內容:請嘗試調低溫度設定,或要求模型提供較短的說明,這樣模型就不太可能推斷出額外的詳細資料。
- 調整取樣參數:嘗試不同的溫度設定和前 K 個選項,調整模型的創意程度。
明確說明指示
提示越清楚詳細,生成結果就越符合需求。如果您有特定輸出內容,建議在提示中加入該要求,確保取得所需輸出內容。
以這張機場看板圖片為例,如果只要求模型「描述這張圖片」,模型可能會生成一般描述。如要讓模型從圖片中剖析時間和城市,可以直接在提示中加入這項要求。
| 提示詞 | 模型回應 |
|---|---|

描述這張圖片。 |
圖片:機場抵達與起飛時刻資訊看板。 |
| 更新提示 | 提升回應品質 |
|---|---|
Parse the time and city from the airport board shown in this image into a list. |
新增幾個範例
Gemini 模型可接受多個輸入內容,並將其做為範例,瞭解您想要的輸出內容。加入這些範例可協助模型找出模式,並將指定圖片和回覆之間的關係套用至新範例。這也稱為「少量樣本」學習。
在下方範例中,初始輸出內容是以句子形式撰寫,且包含國家/地區 (巴西)。假設您希望輸出內容採用不同格式或風格,而且只想要城市,而非國家/地區。在提示中加入少量樣本範例,可引導模型以您想要的方式回覆。
| 提示 | 模型回覆 |
|---|---|
 判斷城市和地標。 |
地標是巴西里約熱內盧的救世基督像。 |
| 更新提示 | 提升回應品質 |
|---|---|
|
判斷城市和地標。 
|
城市:羅馬,地標:羅馬競技場。 |

|
城市:北京,地標:紫禁城 |
|
|
城市:里約熱內盧,地標:救世基督像 |
逐步分解
對於需要視覺理解和推理的複雜工作,建議將工作拆解為較小且更直接的步驟。或者,在提示中直接要求模型「逐步思考」,也可能會有效果。
| 提示詞 | 模型回應 |
|---|---|

我何時會用完衛生紙? |
不久後,你只剩下 3 卷底片。 |
| 更新提示 | 提升回應品質 |
|---|---|
|
|
數學問題或其他類型的文字題很適合要求模型逐步思考。
| 提示 | 回應 |
|---|---|
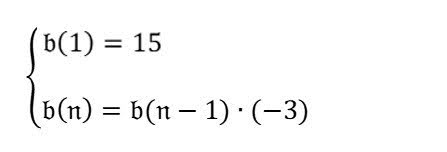
這個數列的第 4 項為何? |
-135 |
模型回覆的內容不正確。如要改善這點,可以要求模型先剖析問題,再回答提示。
| 提示 | 回應 |
|---|---|
請先剖析圖片中的公式。 然後根據公式回答「序列中的第 4 個項是什麼?」。 |
按一下即可展開結果$$ b(n) = b(n-1) * (-3) $$ $$ b(1) = 15 $$
$$ b(4) = b(4-1) * (-3) $$ $$ b(4) = b(3) * (-3) $$ $$ b(3) = b(3-1) * (-3) $$ $$ b(3) = b(2) * (-3) $$ $$ b(2) = b(2-1) * (-3) $$ $$ b(2) = b(1) * (-3) $$ $$ b(2) = 15 * (-3) $$ $$ b(2) = -45 $$ $$ b(3) = b(2) * (-3) $$ $$ b(3) = -45 * (-3) $$ $$ b(3) = 135 $$ $$ b(4) = b(3) * (-3) $$ $$ b(4) = 135 * (-3) $$ $$ b(4) = -405 $$ 因此,這個數列的第 4 項是 -405。 |
這個模型回應正確無誤,現在為了讓回應更加精簡,你可以要求模型逐步思考。
| 更新提示 | 提升回應品質 |
|---|---|
|
這個數列的第 4 項為何?請逐步思考。 |
第一個項是 15。 第二項是 b(1) * (-3) = 15 * (-3) = -45。 第三個項是 b(2) * (-3) = -45 * (-3) = 135。 第四項是 b(3) * (-3) = 135 * (-3) = -405。 |
指定輸出格式
常見的問題是需要模型輸出特定格式的內容 (例如 Markdown、JSON、HTML),尤其是當下游工作需要擷取模型輸出內容時。您可以在提示中指示模型以該格式輸出內容。以下提供兩個範例:
| 提示詞 | 模型回應 |
|---|---|

將這張圖片中的表格剖析為 Markdown 格式 |
| 主題 | 狀態 | 時間 | 開始日期 | 截止日期 | | ------- | ------ | ---- | ---------- | ------ | | 數學 | 完成 | 1.5 小時 | 2023 年 11 月 29 日 | 2023 年 12 月 1 日 | | 地理 | 完成 | 30 分鐘 | 2023 年 12 月 2 日 | 2023 年 12 月 4 日 | | 物理 | 進行中 | 2 小時 | 2023 年 12 月 3 日 | 2023 年 12 月 5 日 | | 生物學 | 未開始 | 6 小時 | 2016 年 11 月 2 日 | 2023 年 12 月 6 日 | |
| 提示 | 模型回覆 |
|---|---|

請提供下列所有屬性的清單: 食材、菜餚類型、是否為素食,以 JSON 格式提供 |
|
如果是單張圖片提示,請將圖片放在最前面
雖然 Gemini 可以解讀提示中的圖片和文字,但將單一圖片放在文字提示之前,可能會得到更理想的結果。在下列範例中,您會發現每個提示中的圖片都排在文字前面。
排解多模態提示問題
如果沒有獲得實用回覆,可能需要排解提示問題。以下提供幾種策略供您參考。
如果模型未從圖片的相關部分擷取資訊
如要取得更具體的回答,可以指出提示要從圖片的哪些方面擷取資訊,以利生成回覆。
| 提示詞 | 模型回應 |
|---|---|

這些尿布夠寶寶用幾天? |
這些尿布可使用 198 天。 |
| 更新提示 | 提升回應品質 |
|---|---|
|
這些尿布可以用多久? 根據包裝盒上顯示的體重判斷孩子的年齡,並使用包裝盒中的尿布總數。 將總數除以孩子每天使用的尿布數量。 |
一箱有 198 片尿布。包裝盒上註明尿布適合體重 22 至 37 磅的兒童。 這個體重範圍的兒童平均年齡可能介於 1 到 2 歲。 2 歲幼童通常每天會用掉 6 片尿布,因此 198 片尿布大約可用 33 天 (198/6)。 |
如果模型輸出內容過於一般,不夠符合圖片輸入內容
為協助模型根據圖片調整回覆內容,請先要求模型描述圖片,再執行推論工作。
| 提示詞 | 模型回應 |
|---|---|



這些圖片有什麼共通點? |
這四張圖片都是風景攝影的例子。 |
| 更新提示 | 提升回應品質 |
|---|---|
|
首先,請詳細描述每張圖片的內容。這些圖片有什麼共通點? |
第一張圖片顯示有人正在打包行李箱。第二張圖片:顯示購物中心空蕩蕩的走廊。第三張圖片顯示一捲衛生紙。第四張圖片顯示狂風暴雨的海面。 這些圖片的共通點是都屬於過渡空間。過渡空間是指介於兩個地點或情況之間的地點或情況。通常會帶有不確定或模稜兩可的感覺。 第一張圖片顯示該使用者在家中和旅途中的狀態。第二張圖片顯示兩間商店之間的走廊。第三張圖片是衛生紙,代表浴室。浴室是私人和公共領域之間的過渡空間。我們會在玄關準備進出外面的世界。 第四張圖片顯示介於平靜和暴風雨之間的海洋。 過渡空間既令人興奮又令人不安。可以是新的開始,也可以是結束。可以是反思或行動的場所。 |
你也可以明確要求模型參照圖片內容。
| 更新提示 | 提升回應品質 |
|---|---|
|
這些圖片有什麼共通點?在回覆中提及圖片內容。 |
所有圖片都與旅遊相關。第一張圖片顯示有人正在打包行李箱,第二張圖片顯示購物中心空蕩蕩的走廊,第三張圖片顯示一疊衛生紙,第四張圖片顯示陰暗且暴風雨的海面。 這些圖片都與旅遊相關,因為都是人們在旅行時需要或使用的物品。第一張圖片顯示一個人正在打包行李箱,這是旅行時會做的事。第二張圖片顯示購物中心的空蕩走廊,人們經常會到這裡購買旅遊用品。第三張圖片顯示一疊衛生紙,這是人們旅行時經常使用的物品。第四張圖片顯示狂風暴雨的海面,這是人們旅行時經常會遇到的情況。 |
這些訣竅也適用於圖片生成的創意內容。在以下兔子範例中,明確要求模型納入圖片中的元素,可以提升輸出結果。
| 提示詞 | 模型回應 |
|---|---|

可以幫我寫一首關於這張圖片的詩嗎? |
小兔兔,柔軟又棕色, 你啃食青翠甜美的草, |
| 更新提示 | 提升回應品質 |
|---|---|
|
請根據這張圖片撰寫一首描述性強烈且充滿戲劇性的詩,並加入地點資訊。 |
綠地上的小兔, 是海洋的藍色嗎? 小兔兒,請你告訴我, 或許是萬物浩瀚, 小兔,我好奇你夢見了什麼, 無論如何,小兔子, |
排解提示的哪個部分失敗
很難判斷提示失敗的原因是模型一開始就不瞭解圖片,還是瞭解圖片但後續推理步驟有誤。如要釐清原因,請要求模型描述圖像內容。
在下列範例中,如果模型回應的點心與茶飲搭配起來似乎很奇怪 (例如爆米花),您可以先進行疑難排解,判斷模型是否正確辨識出圖片含有茶飲。
| 提示詞 | 提示進行疑難排解 |
|---|---|

我可以在 1 分鐘內做出什麼點心,搭配這道菜? |
描述這張圖片的內容。 |
另一種策略是要求模型說明推論過程。這有助於縮小範圍,找出推理過程中的錯誤 (如有)。
| 提示詞 | 提示進行疑難排解 |
|---|---|
|
我可以在 1 分鐘內做出什麼點心,搭配這道菜? |
有什麼 1 分鐘內就能做好的點心適合搭配這道料理?請說明原因。 |
後續步驟
- 使用 Google AI Studio 撰寫自己的多模態提示。
- 如要瞭解如何使用 Gemini Files API 上傳媒體檔案並加入提示,請參閱Vision、音訊和文件處理指南。
- 如需提示設計的更多指引 (例如微調取樣參數),請參閱「提示策略」頁面。