
온디바이스 머신러닝 (ML)을 대규모로 테스트하고 벤치마킹하기 위한 AI Edge의 Google Cloud 솔루션입니다.
다양한 모바일 기기에서 ML 모델 성능을 최적화하는 것은 어려울 수 있습니다. 수동 테스트는 느리고 비용이 많이 들며 대부분의 개발자가 액세스할 수 없는 경우가 많아 실제 모델 성능에 불확실성이 발생합니다. Google AI Edge Portal은 다양한 모바일 기기에서 LiteRT 모델 벤치마킹을 지원하여 이 문제를 해결하고 개발자가 대규모 ML 모델 배포에 가장 적합한 구성을 찾을 수 있도록 지원합니다.
모바일 ML 배포 최적화
다양한 하드웨어 환경에서 테스트 주기 간소화 및 가속화: 수백 개의 대표적인 모바일 기기에서 몇 분 만에 모델 성능을 손쉽게 평가할 수 있습니다.
모델 품질을 사전 예방적으로 보장하고 문제를 조기에 식별: 배포 전에 하드웨어별 성능 변동 또는 회귀 (예: 특정 칩셋 또는 메모리 제한 기기)를 정확히 파악합니다.
기기 테스트 비용 절감 및 최신 하드웨어 액세스: 자체 실험실을 유지하는 데 드는 비용과 복잡성 없이 다양하고 지속적으로 증가하는 실제 기기 (현재 다양한 Android OEM의 100개 이상의 기기 모델)에서 테스트합니다.
강력한 데이터 기반 의사 결정 및 비즈니스 인텔리전스 활용: Google AI Edge Portal은 풍부한 실적 데이터와 비교를 제공하여 모델 최적화를 자신 있게 안내하고 배포 준비 상태를 검증하는 데 필요한 중요한 비즈니스 인텔리전스를 제공합니다.
벤치마크 예:
Google AI Edge Portal이 LiteRT 모델의 벤치마킹에 도움이 되는 방법
기기 선택: NPU 지원, 기기 등급, 브랜드, 칩셋, RAM 등 특정 하드웨어 필터를 사용하여 광범위한 풀에서 타겟 기기를 선택합니다. 또는 맞춤 바로가기를 사용하여 인기 기기 목록에 즉시 액세스하세요.
구성 만들기: 벤치마킹 작업에 CPU, GPU 또는 NPU 가속기 중에서 선택합니다.
고급 맞춤설정: 선택한 액셀러레이터의 하드웨어 관련 설정을 조정하거나 기본값으로 진행합니다.
NPU 지원: 이제 하드웨어 가속 기능에 30개가 넘는 Qualcomm 기기가 포함된 NPU가 포함됩니다.
- Ahead-Of-Time (AOT) 컴파일: 프로덕션 수준의 성능에 권장되며 초기화가 훨씬 빠르고 메모리 사용량이 적습니다. 이 모드에서는 기기 선택에 있는 각 고유 SoC에 컴파일된 모델을 제공해야 합니다.
- 적시 (JIT) 컴파일: 선택한 기기에서 컴파일할 단일 모델을 지원합니다.
모델 업로드: UI를 사용하여 모델 파일을 업로드하거나 Google Cloud Storage 버킷에서 모델 파일을 가리킵니다.
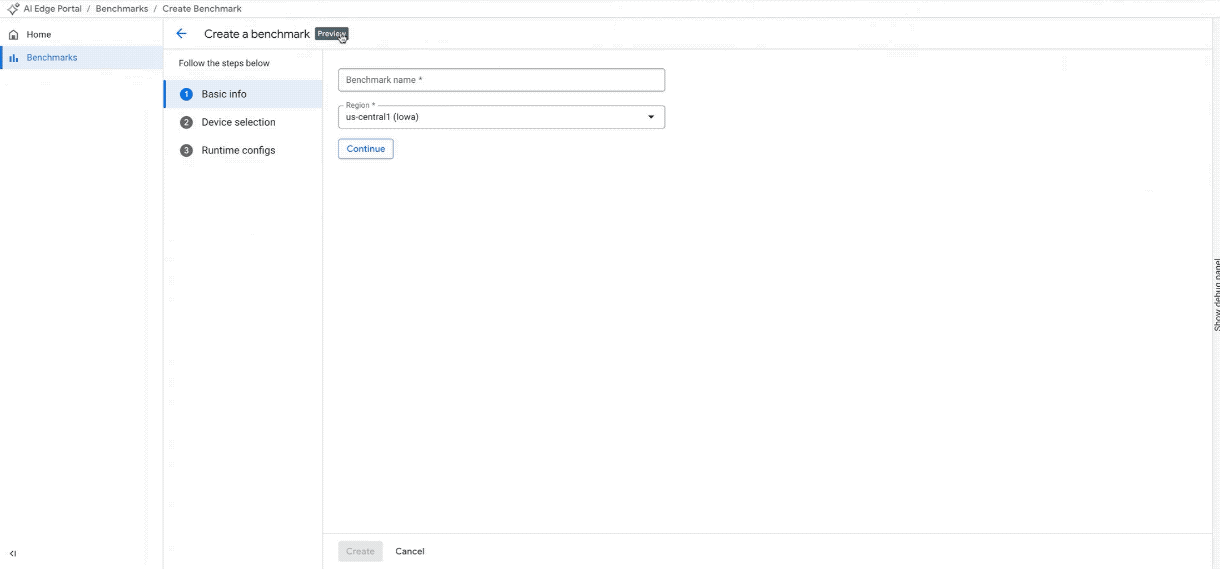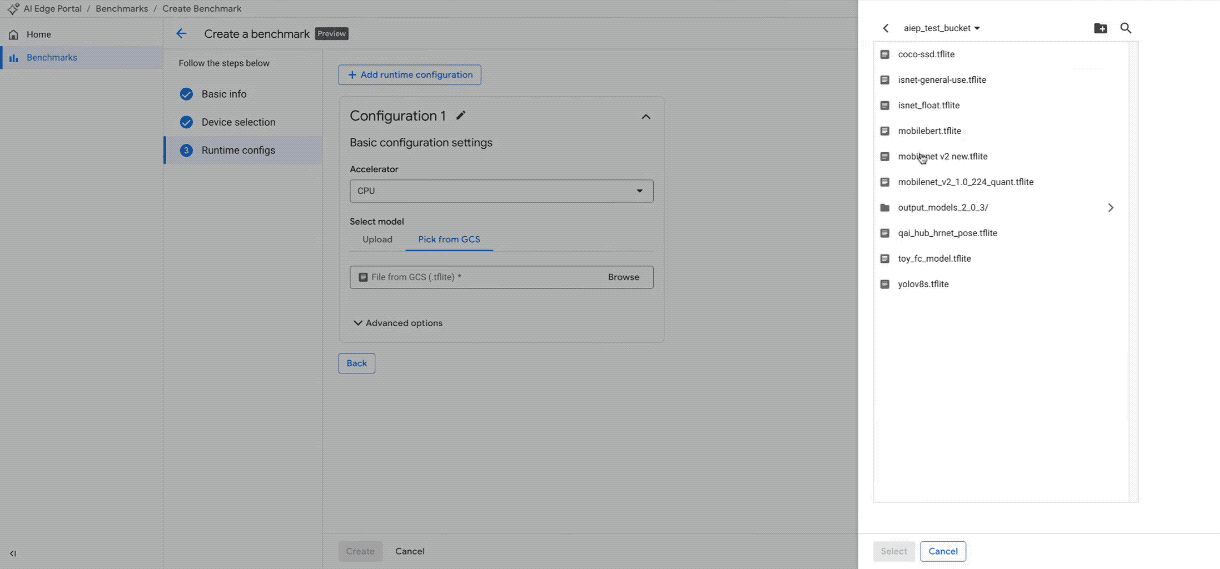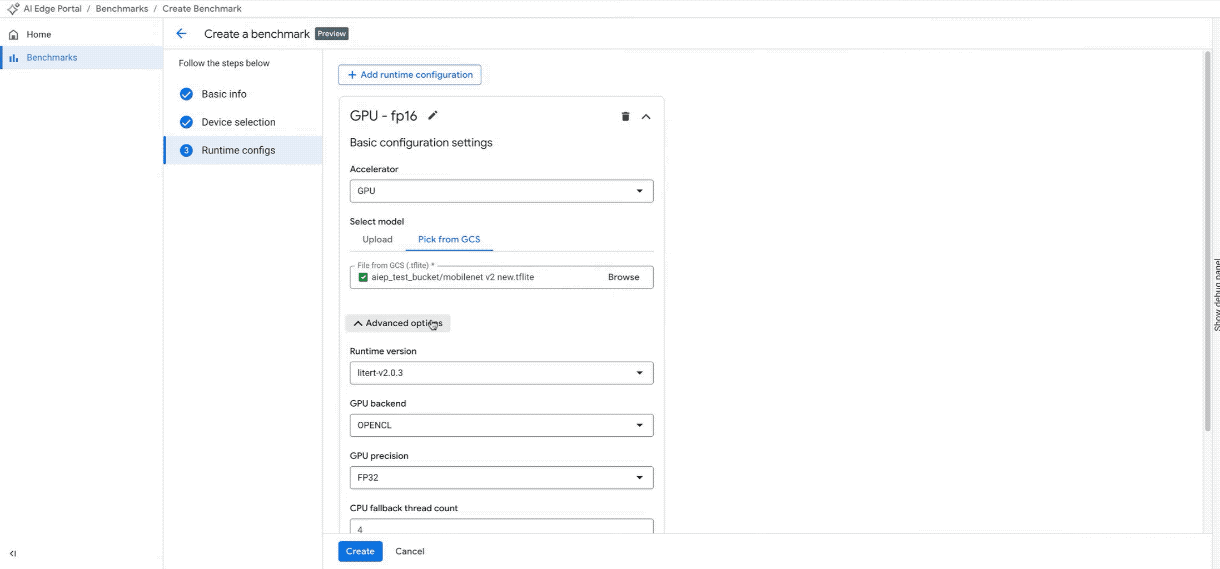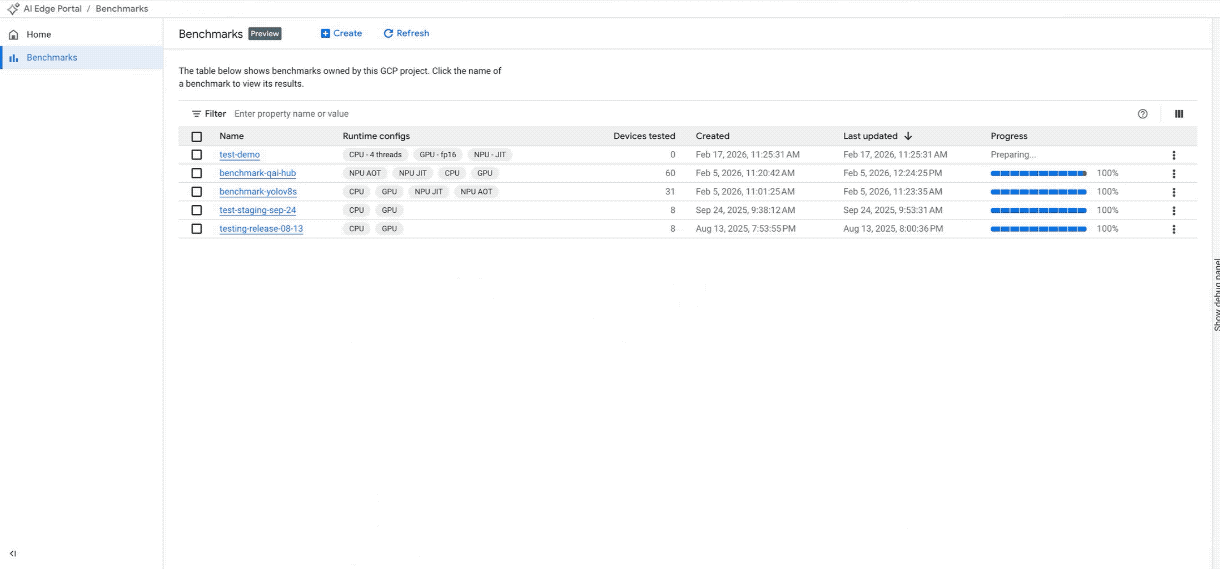
100개 이상의 기기에서 새 벤치마크 작업을 만듭니다. (참고: GIF는 간결성을 위해 속도를 높이고 편집되었습니다.)
여기에서 작업을 제출하고 완료될 때까지 기다립니다. 준비가 되면 대화형 대시보드에서 결과를 살펴봅니다.
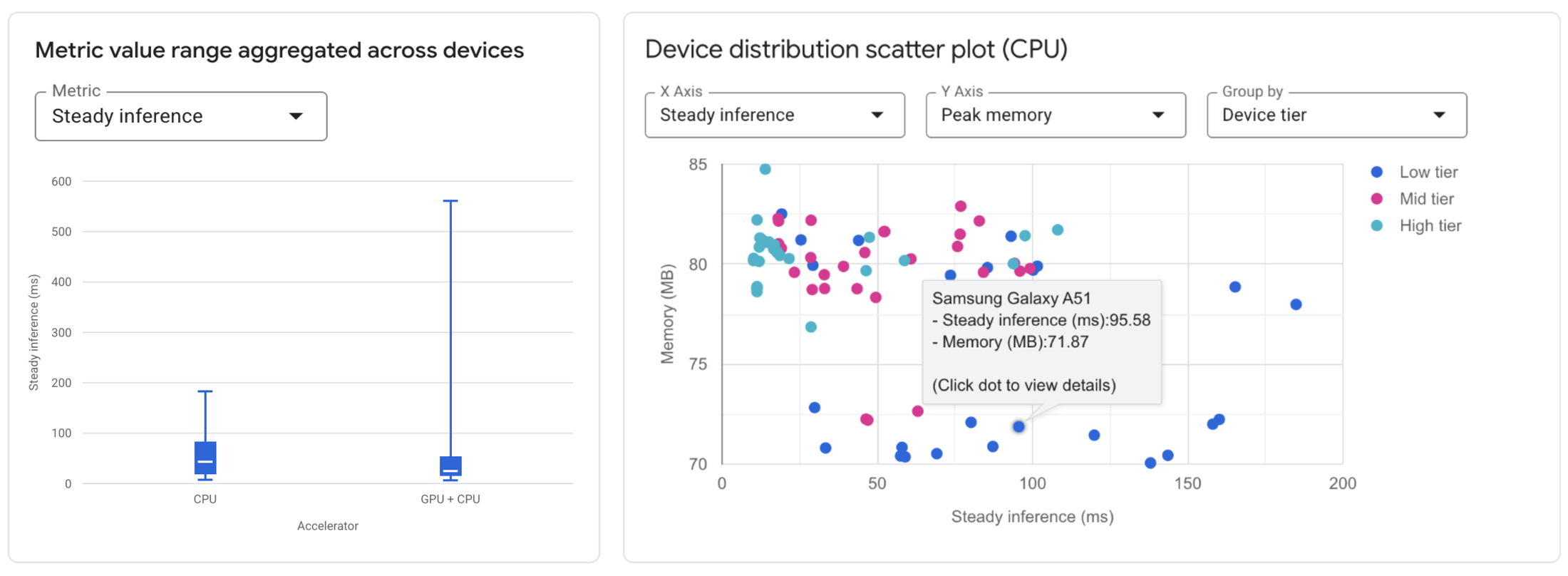
구성 비교: 테스트된 모든 기기에서 서로 다른 액셀러레이터를 사용할 때 성능 측정항목 (예: 평균 지연 시간, 최대 메모리)이 어떻게 다른지 빠르게 시각화합니다.
기기 영향 분석: 선택한 기기 범위에서 특정 모델 구성이 어떻게 작동하는지 확인합니다. 히스토그램과 분산형 차트를 사용하여 기기 특성과 관련된 성능 변동을 빠르게 파악합니다.
세부 측정항목: 각 개별 기기의 구체적인 측정항목(초기화 시간, 추론 지연 시간, 메모리 사용량)과 하드웨어 사양을 보여주는 정렬 가능한 세부 표에 액세스합니다. 모델 작업이 커널에 분산되는 방식을 보여주는 가속기 할당 표를 사용하여 하드웨어 사용률을 확인합니다 (CPU 및 GPU에 사용 가능하며 NPU 지원은 곧 제공 예정).
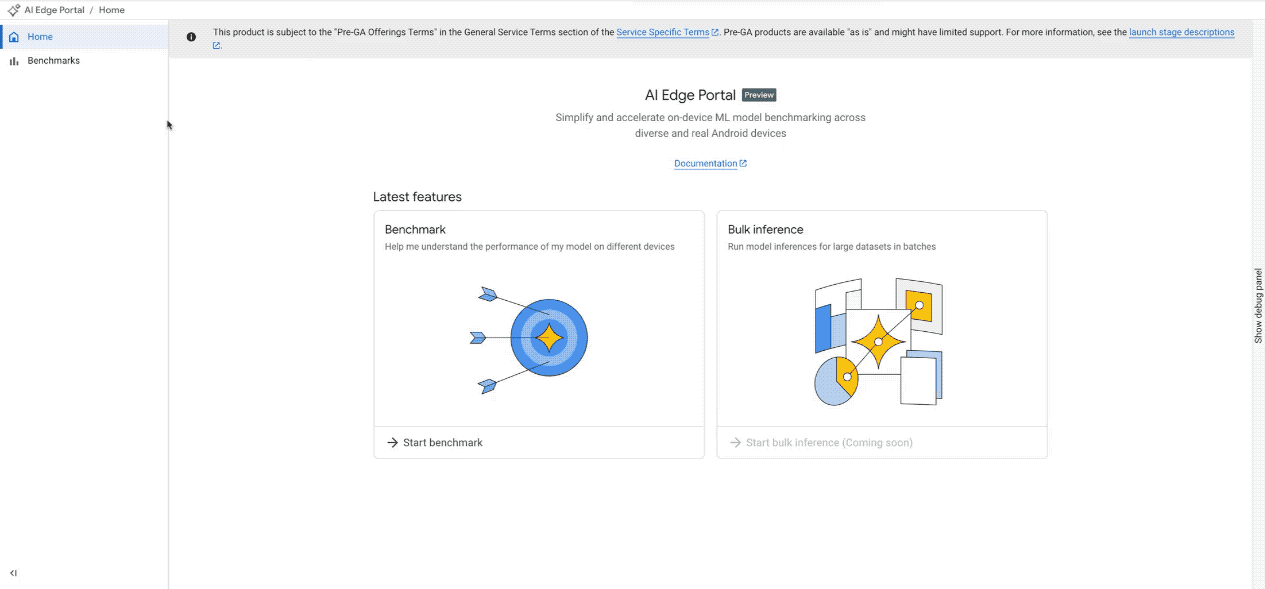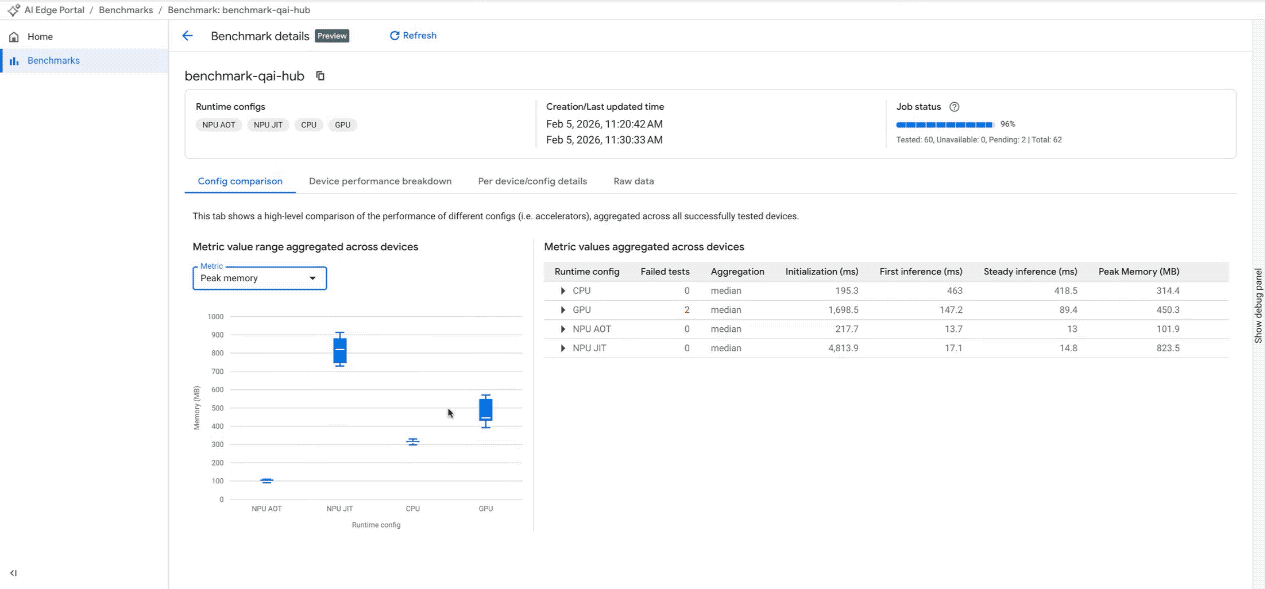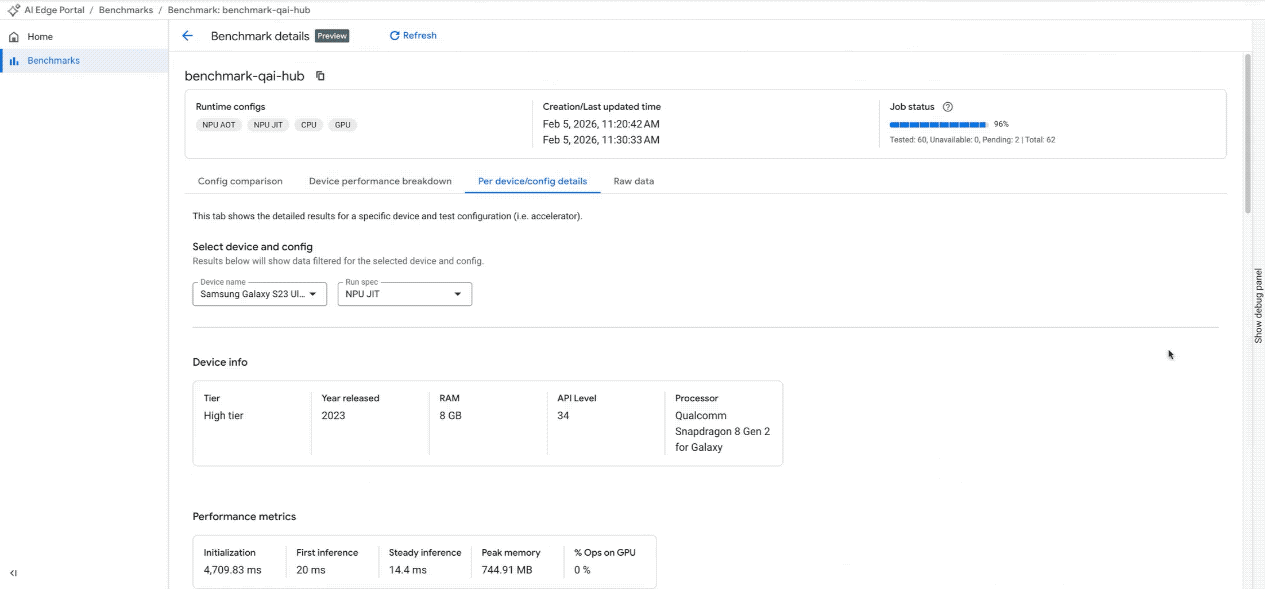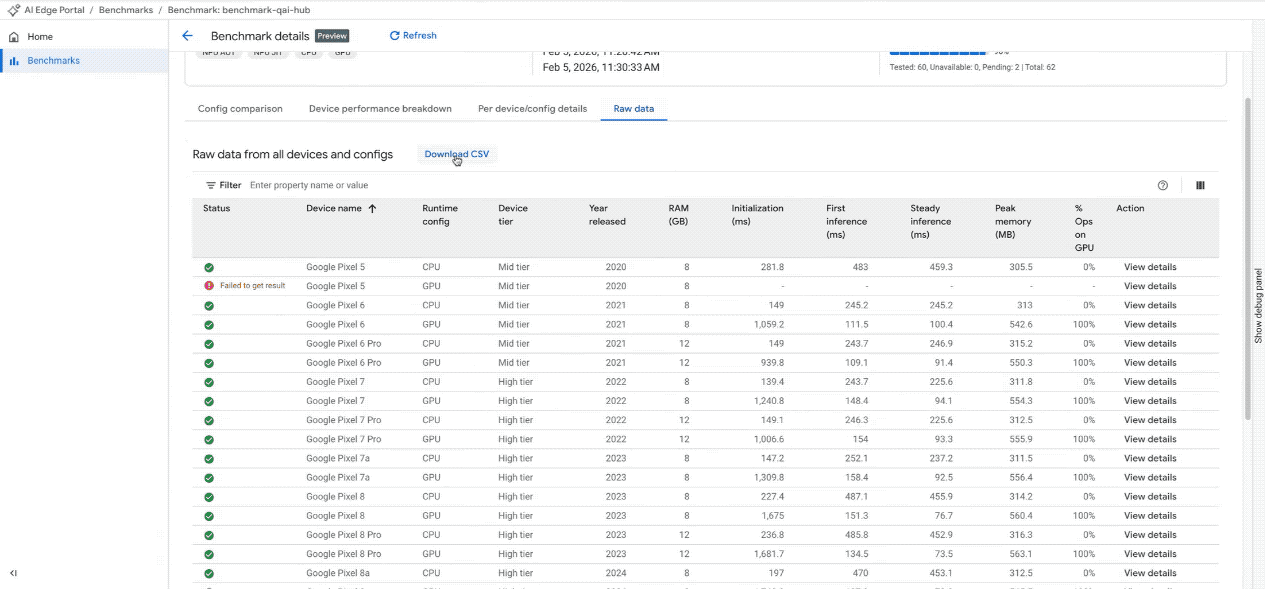
대화형 대시보드에서 벤치마크 결과를 확인합니다. (참고: GIF는 간결성을 위해 속도를 높이고 편집되었습니다.)
Google AI Edge Portal 비공개 미리보기 참여
Google AI Edge Portal은 허용 목록에 추가된 Google Cloud 고객을 대상으로 비공개 프리뷰로 제공됩니다. 이 비공개 미리보기 기간 동안 미리보기 약관에 따라 액세스가 무료로 제공됩니다.
이 미리보기는 다양한 Android 하드웨어에서 안정적인 벤치마킹 데이터가 필요하고 제품의 미래를 개선하는 데 도움이 되는 의견을 제공하려는 LiteRT를 사용하여 모바일 ML 애플리케이션을 빌드하는 개발자와 팀에 적합합니다. 액세스를 요청하려면 여기에서 가입 양식을 작성하여 관심을 표현하세요. 액세스 권한은 허용 목록을 통해 부여됩니다.