2025 年 4 月 9 日
Langbase の Gemini Flash を使用した高スループットで低コストの AI エージェント

オペレーションと外部ツールを自律的に管理できる AI エージェントを構築するには、通常、統合とインフラストラクチャのハードルを乗り越える必要があります。Langbase は、こうした根本的な複雑さを管理する負担を軽減し、Gemini などのモデルを搭載したサーバーレス AI エージェントをフレームワークなしで作成してデプロイするためのプラットフォームを提供します。
Gemini Flash のリリース以来、Langbase ユーザーは、エージェント エクスペリエンスにこれらの軽量モデルを使用することによるパフォーマンスとコストのメリットをすぐに実感しています。
Gemini Flash でスケーラビリティと高速 AI エージェントを実現する
Langbase プラットフォームは、Gemini API を介して Gemini モデルへのアクセスを提供します。これにより、ユーザーは複雑なタスクを処理し、大量のデータを処理できる高速モデルを選択できます。スムーズなリアルタイム エクスペリエンスを実現するには低レイテンシが不可欠であるため、Gemini Flash モデル ファミリーは、ユーザー向けのエージェントの構築に特に適しています。
Gemini 1.5 Flash を使用すると、応答時間が 28% 短縮されるだけでなく、運用コストが 50% 削減され、スループットが 78% 向上します。パフォーマンスを損なうことなく大量のリクエストを処理できる Gemini Flash モデルは、ソーシャル メディア コンテンツの作成、研究論文の要約、医療文書のアクティブな分析などのユースケースで、需要の高いアプリケーションに最適な選択肢です。
31.1 トークン/秒
Flash は同等のモデルと比較してスループットが 78% 向上
7.8 倍
Flash と同等のモデルのコンテキスト ウィンドウの比較
28%
Flash と同等のモデルの応答時間の比較
50%
同等のモデルと比較して Flash のコストを削減
- 出典: Langbase ブログ
Langbase がエージェント開発を簡素化する方法
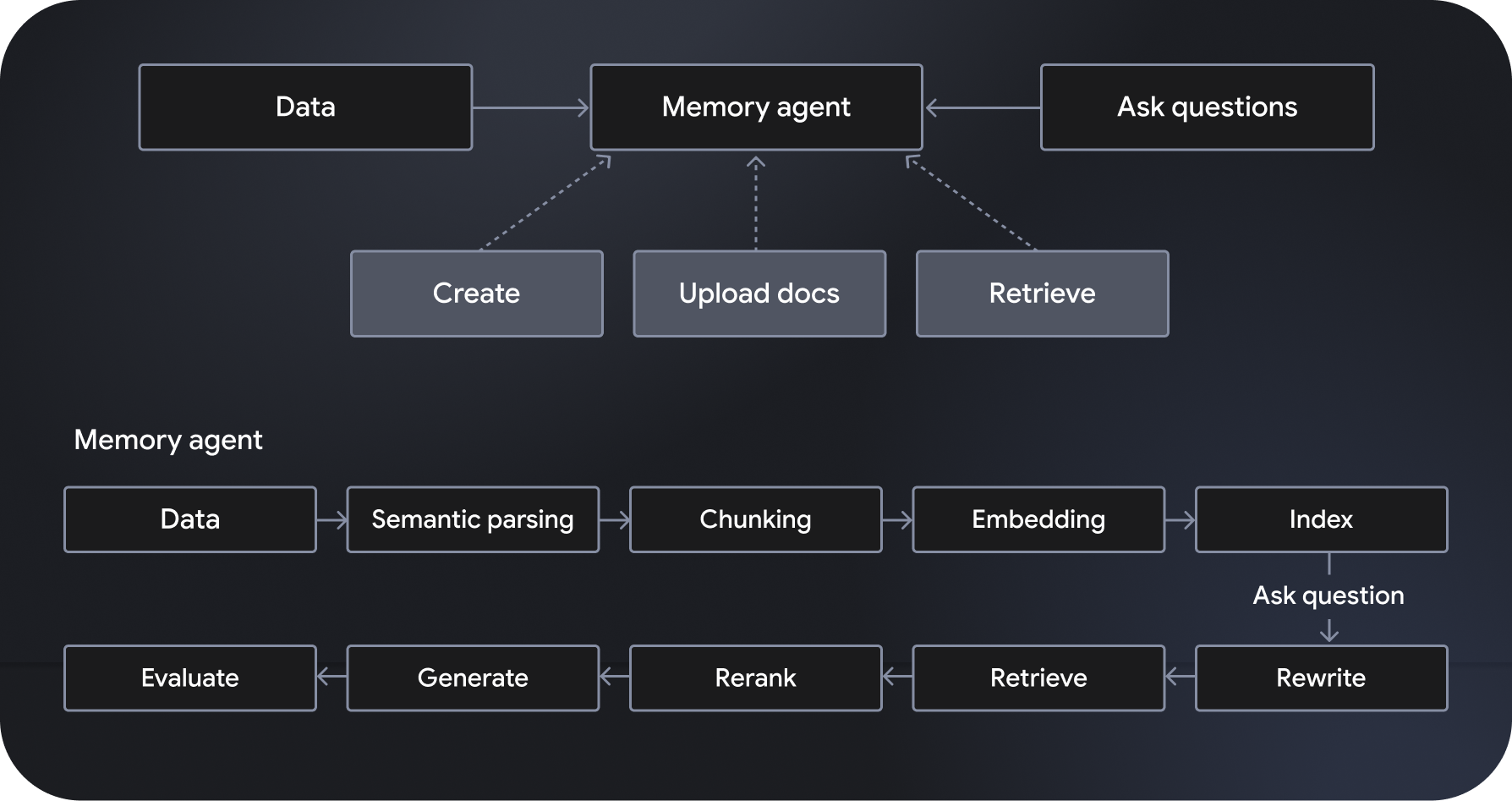
Langbase は、サーバーレス AI エージェントの作成を可能にする、サーバーレスでコンポーザブルな AI エージェントの開発とデプロイのプラットフォームです。「メモリエージェント」と呼ばれる、フルマネージドでスケーラブルなセマンティック検索拡張生成(RAG)システムを提供します。その他の機能には、ワークフロー オーケストレーション、データ管理、ユーザー インタラクションの処理、外部サービスとの統合などがあります。
Gemini 2.0 Flash などのモデルを搭載した「パイプ エージェント」は、指定された指示に従って行動し、ウェブ検索やウェブクローリングなどの強力なツールにアクセスできます。一方、メモリ エージェントは関連データを動的にアクセスして、グラウンディングされたレスポンスを生成します。Langbase の Pipe API と Memory API を使用すると、強力な推論を新しいデータソースに接続して強力な機能を構築し、AI モデルの知識とユーティリティを拡張できます。