

La tâche MediaPipe Pose Landmarker vous permet de détecter les points de repère des corps humains dans une image ou une vidéo. Vous pouvez utiliser cette tâche pour identifier les principaux points du corps, analyser la posture et catégoriser les mouvements. Cette tâche utilise des modèles de machine learning (ML) qui fonctionnent avec des images ou des vidéos uniques. La tâche génère des repères de position du corps en coordonnées d'image et en coordonnées mondiales tridimensionnelles.
Premiers pas
Pour commencer à utiliser cette tâche, suivez le guide d'implémentation de votre plate-forme cible. Ces guides spécifiques à la plate-forme vous expliquent comment implémenter de manière basique cette tâche, y compris un modèle recommandé et un exemple de code avec les options de configuration recommandées:
- Android – Exemple de code – Guide
- Python – Exemple de code – Guide
- Web – Exemple de code – Guide
Détails de la tâche
Cette section décrit les fonctionnalités, les entrées, les sorties et les options de configuration de cette tâche.
Fonctionnalités
- Traitement des images d'entrée : le traitement comprend la rotation, le redimensionnement, la normalisation et la conversion d'espaces colorimétriques.
- Seuil de score : filtrez les résultats en fonction des scores de prédiction.
| Entrées de tâche | Sorties de tâche |
|---|---|
Le repère de position accepte l'un des types de données suivants:
|
Le Pose Landmarker génère les résultats suivants:
|
Options de configuration
Cette tâche propose les options de configuration suivantes:
| Nom de l'option | Description | Plage de valeurs | Valeur par défaut |
|---|---|---|---|
running_mode |
Définit le mode d'exécution de la tâche. Il existe trois modes: IMAGE: mode pour les entrées d'une seule image. VIDEO: mode des images décodées d'une vidéo. LIVE_STREAM: mode de diffusion en direct des données d'entrée, par exemple à partir d'une caméra. Dans ce mode, resultListener doit être appelé pour configurer un écouteur afin de recevoir les résultats de manière asynchrone. |
{IMAGE, VIDEO, LIVE_STREAM} |
IMAGE |
num_poses |
Nombre maximal de poses pouvant être détectées par le repère de pose. | Integer > 0 |
1 |
min_pose_detection_confidence |
Score de confiance minimal pour que la détection de la position soit considérée comme réussie. | Float [0.0,1.0] |
0.5 |
min_pose_presence_confidence |
Score de confiance minimal de la présence de la pose dans la détection des repères de la pose. | Float [0.0,1.0] |
0.5 |
min_tracking_confidence |
Score de confiance minimal pour que le suivi de la position soit considéré comme réussi. | Float [0.0,1.0] |
0.5 |
output_segmentation_masks |
Indique si Pose Landmarker génère un masque de segmentation pour la position détectée. | Boolean |
False |
result_callback |
Définit l'écouteur de résultats pour qu'il reçoive les résultats du repère de manière asynchrone lorsque le repère de pose est en mode diffusion en direct.
Ne peut être utilisé que lorsque le mode d'exécution est défini sur LIVE_STREAM. |
ResultListener |
N/A |
Modèles
Le détecteur de repères de position utilise une série de modèles pour prédire les repères de position. Le premier modèle détecte la présence de corps humains dans un cadre d'image, et le second modèle localise des repères sur les corps.
Les modèles suivants sont regroupés dans un lot de modèles téléchargeable:
- Modèle de détection des postures: détecte la présence de corps avec quelques repères clés de la posture.
- Modèle de repère de pose: ajoute une cartographie complète de la pose. Le modèle génère une estimation de 33 repères de position tridimensionnels.
Ce bundle utilise un réseau de neurones convolutifs semblable à MobileNetV2 et est optimisé pour les applications de fitness en temps réel sur l'appareil. Cette variante du modèle BlazePose utilise GHUM, un pipeline de modélisation de la forme humaine en 3D, pour estimer la position complète du corps d'un individu dans des images ou des vidéos.
| Groupe de modèles | Forme d'entrée | Type de données | Fiches de modèle | Versions |
|---|---|---|---|---|
| Pos Marker (lite) | Détecteur de position: 224 x 224 x 3 Délimiteur de position: 256 x 256 x 3 |
float 16 | info | Nouveautés |
| Pos (Full) | Détecteur de position: 224 x 224 x 3 Délimiteur de position: 256 x 256 x 3 |
float 16 | info | Nouveautés |
| Pos Marker (Heavy) | Détecteur de position: 224 x 224 x 3 Délimiteur de position: 256 x 256 x 3 |
float 16 | info | Nouveautés |
Modèle de repère de posture
Le modèle de repères de position suit 33 repères corporels, qui représentent l'emplacement approximatif des parties du corps suivantes:
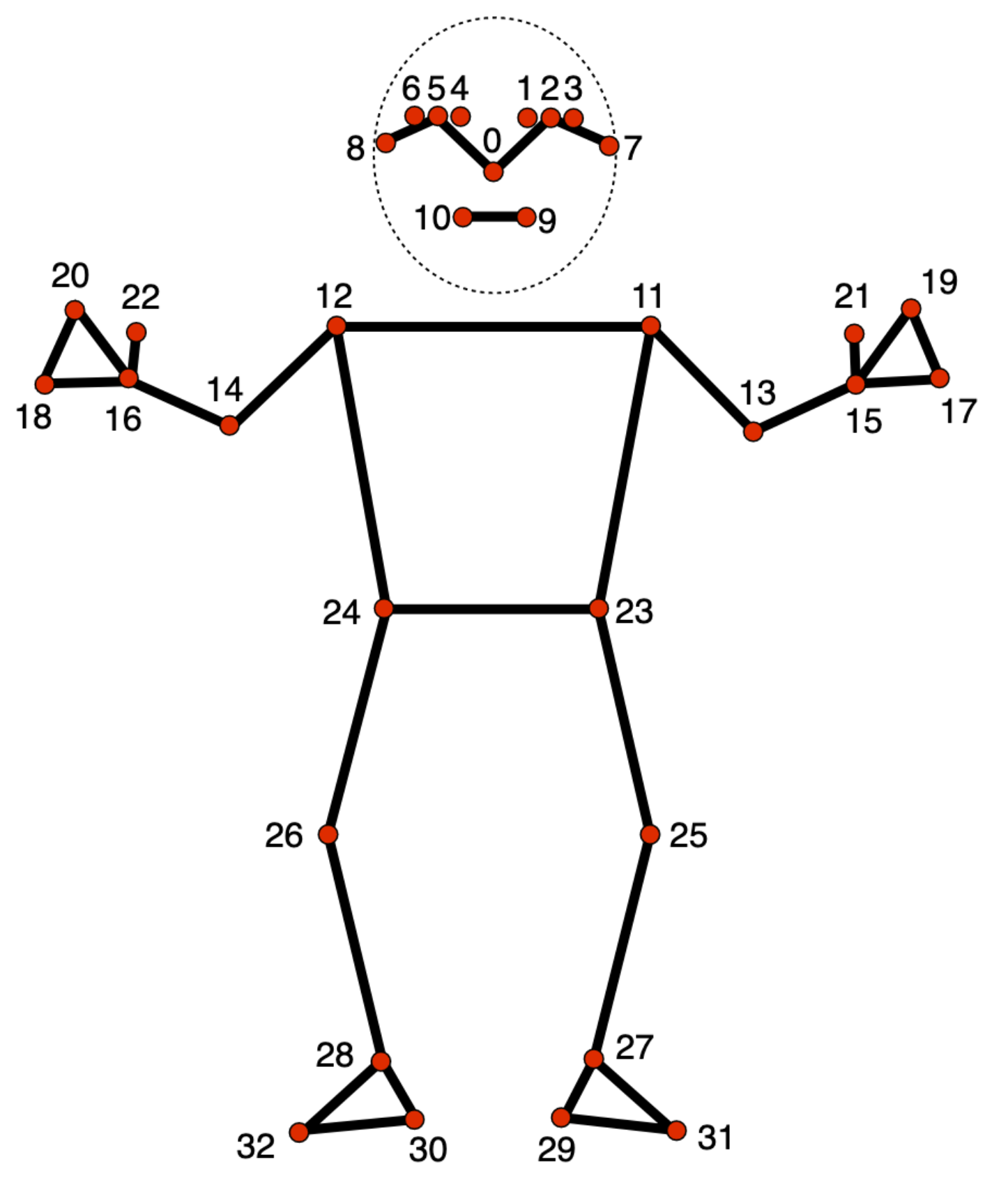
0 - nose
1 - left eye (inner)
2 - left eye
3 - left eye (outer)
4 - right eye (inner)
5 - right eye
6 - right eye (outer)
7 - left ear
8 - right ear
9 - mouth (left)
10 - mouth (right)
11 - left shoulder
12 - right shoulder
13 - left elbow
14 - right elbow
15 - left wrist
16 - right wrist
17 - left pinky
18 - right pinky
19 - left index
20 - right index
21 - left thumb
22 - right thumb
23 - left hip
24 - right hip
25 - left knee
26 - right knee
27 - left ankle
28 - right ankle
29 - left heel
30 - right heel
31 - left foot index
32 - right foot index
La sortie du modèle contient à la fois des coordonnées normalisées (Landmarks) et des coordonnées mondiales (WorldLandmarks) pour chaque repère.